前言
前些天无意间在百度搜索了一下以前写过的博客
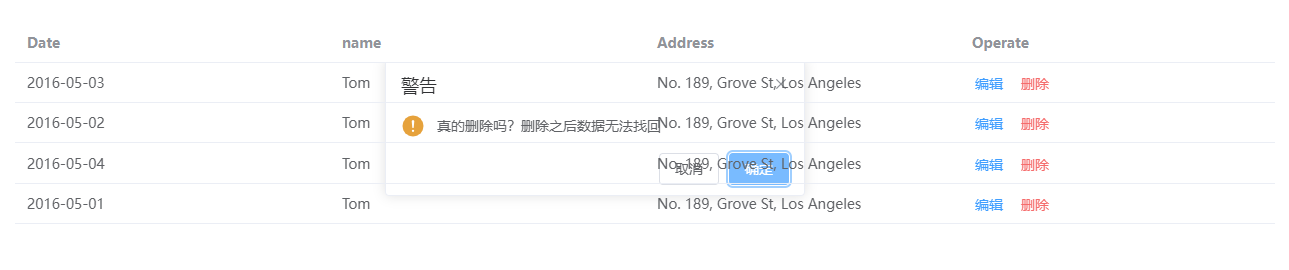
我啥时候在这么多不知名的网站上发表博客了???点进去一看, 内容一模一样,作者却不是我...

然后又去搜了其他篇博客,果然,基本上每篇都在别的网站上有,细想,可能是通过网络爬虫爬取博客园首页博客,然后copy至自己网站中,于是乎,博主也来实现一遍爬取流程。。。
实现思路
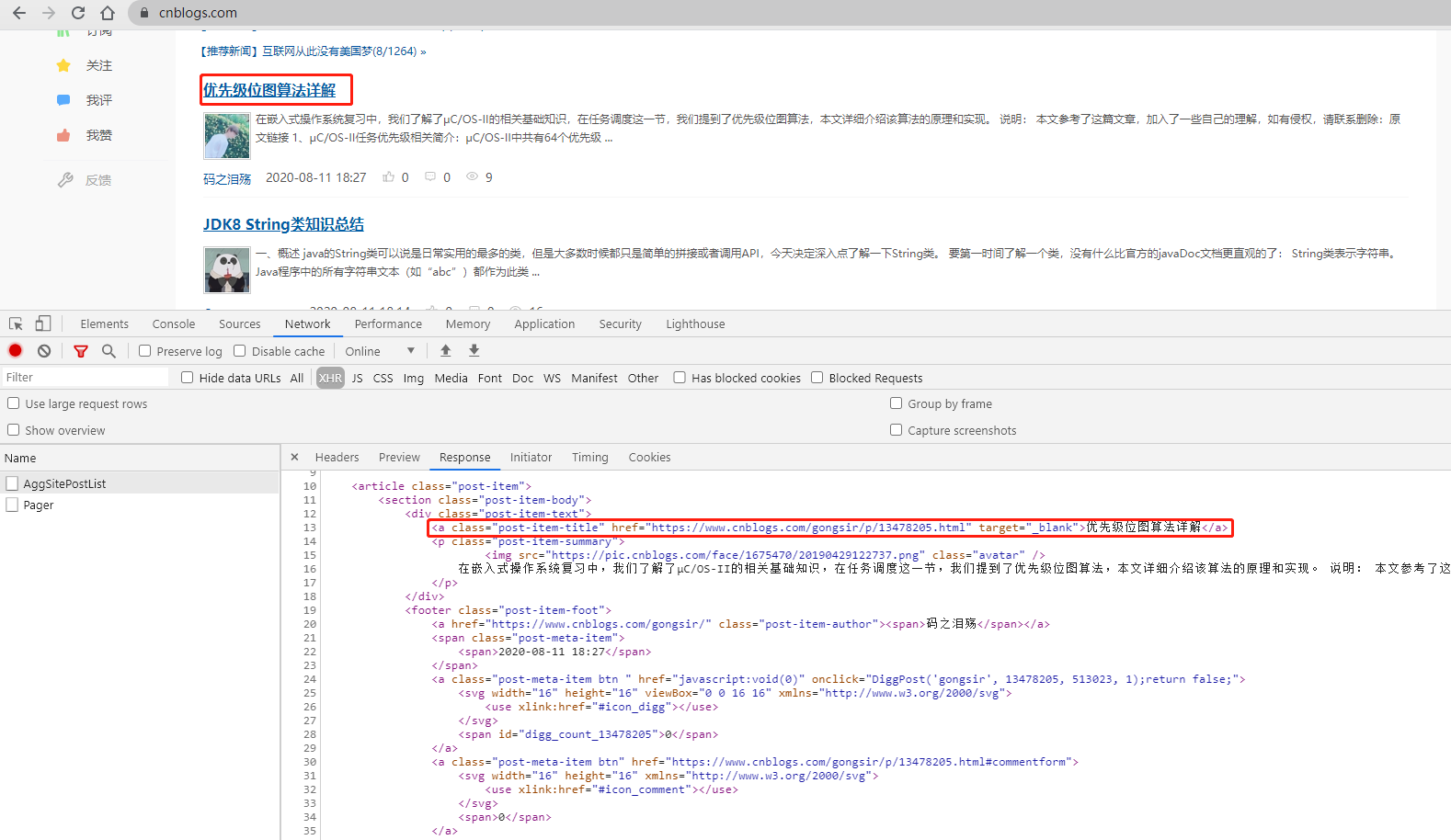
先访问博客园首页,F12查看源代码,可以看到博客的链接和标题都是放在一个a标签里,
点击上一下、下一页,再看一下请求参数,嗯。。。这个应该是页码参数
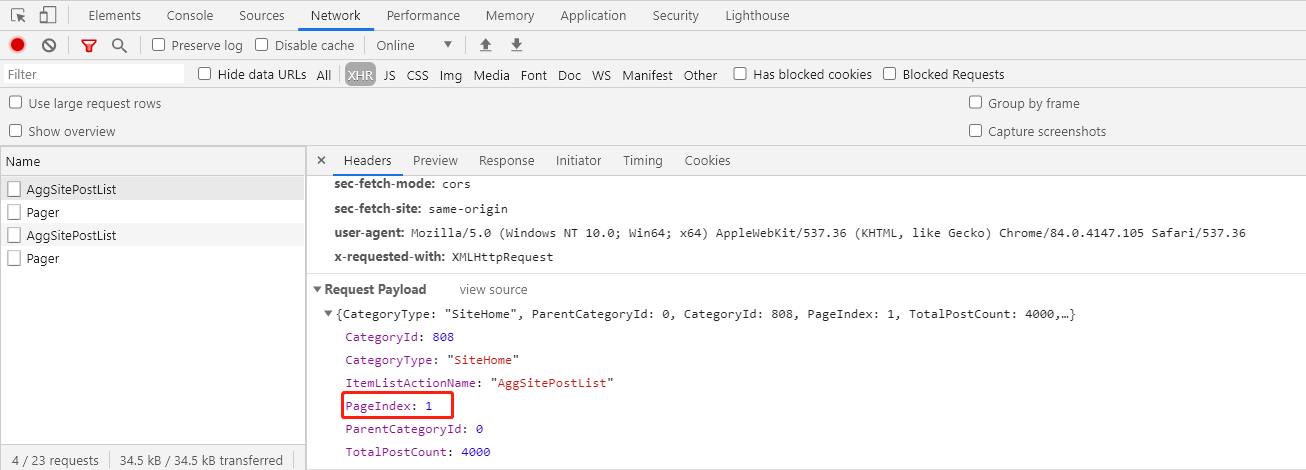
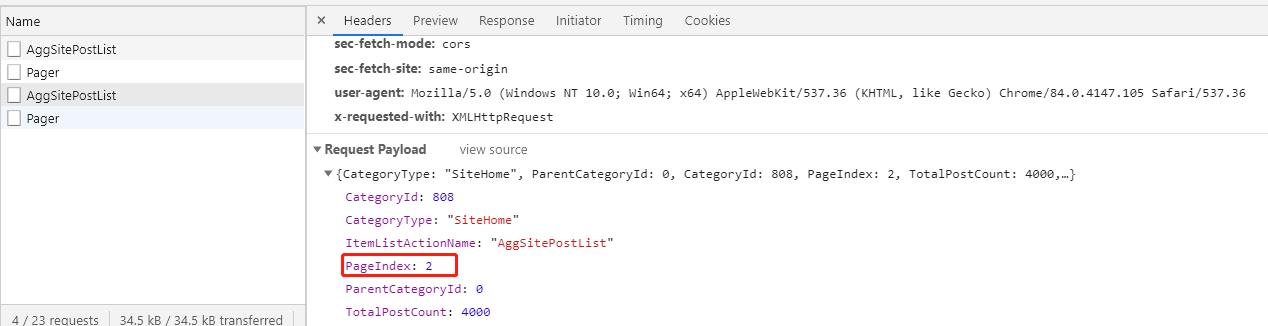
通过以上这些信息,我们就可以知道只需要每次传入不同的页码访问博客园首页,就可以获得相应博客的html页面返回,然后我们根据返回的html页面,解析出当页的博客链接和标题就可以啦。
说干就干,下面我们用代码实现模拟下载博客园200页(200 * 20 = 4000篇)博文的程序
具体实现
直接上代码了,注释都在代码中
import java.io.*; import java.net.URL; import java.net.URLConnection; import java.text.SimpleDateFormat; import java.util.ArrayList; import java.util.Date; import java.util.List; import java.util.Map; import java.util.concurrent.CopyOnWriteArrayList; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * @ClassName BKYPageReptile * @Description TODO(爬取博客园文章) * @Author 我恰芙蓉王 * @Date 2020年08月11日 9:38 * @Version 2.0.0 **/ public class BKYPageReptile { //请求地址 private static final String URL = "https://www.cnblogs.com"; //保存路径 private static final String TARGET_PATH = "F://" + "博客园"; //行匹配正则 private static final Pattern LINE_PATTERN = Pattern.compile("<a class=\"post-item-title\" href=\"https://www.cnblogs.com/.*?\\.html\" target=\"_blank\">.*?</a>"); //url正则 private static final Pattern URL_PATTERN = Pattern.compile("https://www.cnblogs.com/.*?\\.html"); //标题/文件名正则 private static final Pattern TITLE_PATTERN = Pattern.compile(">.*?</a>"); //标题缓存 private static final List<String> TITLE_LIST = new CopyOnWriteArrayList<>(); //当前页数 private static int PAGE = 1; //最大拉取页数 private static final int MAX_PAGE = 200; //一共拉取博客篇数 private static int ALL_COUNT = 0; //时间格式 private static final SimpleDateFormat SDF = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); public static void main(String[] args) { //创建根目录 File rootDir = new File(TARGET_PATH); if (!rootDir.exists()) { rootDir.mkdir(); } //创建日志文件夹 String logPath = TARGET_PATH + "//拉取日志"; File logDir = new File(logPath); if (!logDir.exists()) { logDir.mkdir(); } //创建日志文件 File logFile = new File(logPath + "//log.txt"); if (!logFile.exists()) { try { logFile.createNewFile(); } catch (IOException e) { e.printStackTrace(); } } //循环拉取 while (PAGE <= MAX_PAGE) { //日志内容 String logContent = "正在拉取第" + PAGE + "页\n"; System.err.println("\n" + logContent); String param = "PageIndex=" + PAGE; try { //获取指定页页返回内容 String response = sendPost(URL, param); Matcher matcher = LINE_PATTERN.matcher(response); //需要写入的文件集合 ArrayList<FileTemplate> urlList = new ArrayList<>(20); /** * 解析返回内容封装成FileTemplate */ while (matcher.find()) { //匹配行 String matchLine = matcher.group(); Matcher matcher1 = TITLE_PATTERN.matcher(matchLine); String title = null; while (matcher1.find()) { //匹配的标题 >标题</a> title = matcher1.group(); } //截取拿到真实标题 title = title.substring(1, title.length() - 4); //特殊字符处理 title = title.replace("<", "《") .replace(">", "》") .replace("\\", "-") .replace("/", "-") .replace(":", ":") .replace("*", "") .replace("?", "?") .replace("|", "") + ".html"; System.err.println("title = " + title); //如果已经拉取了此标题的html文件 则跳过此篇 if (TITLE_LIST.contains(title)) { continue; } Matcher matcher2 = URL_PATTERN.matcher(matchLine); String url = null; while (matcher2.find()) { //匹配博客的请求url url = matcher2.group(); } //封装成文件模板对象 urlList.add(new FileTemplate(url, title, false)); } /** * 写入磁盘 */ urlList.parallelStream().forEach(v -> { FileOutputStream fos = null; PrintWriter pw = null; try { String result = sendGet(v.getGetUrl(), ""); File file = new File(TARGET_PATH + File.separator + v.getTitle()); file.createNewFile(); fos = new FileOutputStream(file); pw = new PrintWriter(fos); pw.write(result.toCharArray()); pw.flush(); v.setFlag(true); TITLE_LIST.add(v.getTitle()); } catch (Exception e) { System.out.println(v.toString()); e.printStackTrace(); } finally { try { if (fos != null) { fos.close(); } if (pw != null) { pw.close(); } } catch (IOException e) { e.printStackTrace(); } } }); /** * 记录日志 */ //本次写入成功博客数 long count = urlList.stream().filter(v -> v.getFlag()).count(); String date = SDF.format(new Date()); //累加次数 ALL_COUNT += count; logContent += "本次拉取完成,共 " + count + " 篇新博客\r\n"; logContent += "一共拉取了 " + ALL_COUNT + " 篇\r\n"; logContent += "时间 : " + date + "\n\n"; BufferedWriter out = null; try { out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(logFile, true))); out.write(logContent + "\r\n"); } catch (Exception e) { e.printStackTrace(); } finally { try { out.close(); } catch (IOException e) { e.printStackTrace(); } } PAGE++; } catch (Exception e) { e.printStackTrace(); } } } /** * 文件模板类 */ private static class FileTemplate { /** * 请求地址 */ private String getUrl; /** * 标题 */ private String title; /** * 已经爬取标识 */ private boolean flag; public FileTemplate(String getUrl, String title, boolean flag) { this.getUrl = getUrl; this.title = title; this.flag = flag; } public String getGetUrl() { return getUrl; } public void setGetUrl(String getUrl) { this.getUrl = getUrl; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } @Override public String toString() { final StringBuilder sb = new StringBuilder("FileTemplate{"); sb.append("getUrl='").append(getUrl).append('\''); sb.append(", title='").append(title).append('\''); sb.append('}'); return sb.toString(); } public boolean getFlag() { return flag; } public void setFlag(boolean flag) { this.flag = flag; } } /** * 功能描述: 向指定URL发送GET请求 * * @param url 发送请求的URL * @param param 请求参数,请求参数应该是 name1=value1&name2=value2 的形式 * @创建人: 我恰芙蓉王 * @创建时间: 2020年08月11日 16:42:17 * @return: java.lang.String 响应结果 **/ public static String sendGet(String url, String param) { StringBuilder sb = new StringBuilder(); BufferedReader in = null; try { String urlNameString = url + "?" + param; URL realUrl = new URL(urlNameString); // 打开和URL之间的连接 URLConnection connection = realUrl.openConnection(); // 设置通用的请求属性 connection.setRequestProperty("accept", "*/*"); connection.setRequestProperty("connection", "Keep-Alive"); connection.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)"); // 建立实际的连接 connection.connect(); // 获取所有响应头字段 Map<String, List<String>> map = connection.getHeaderFields(); // 定义 BufferedReader输入流来读取URL的响应 in = new BufferedReader(new InputStreamReader( connection.getInputStream())); String line; while ((line = in.readLine()) != null) { sb.append(line); } } catch (Exception e) { System.out.println("发送GET请求出现异常!" + e); e.printStackTrace(); } // 使用finally块来关闭输入流 finally { try { if (in != null) { in.close(); } } catch (Exception e2) { e2.printStackTrace(); } } return sb.toString(); } /** * 功能描述: 向指定URL发送POST请求 * * @param url 发送请求的URL * @param param 请求参数,请求参数应该是 name1=value1&name2=value2 的形式 * @创建人: 我恰芙蓉王 * @创建时间: 2020年08月11日 16:42:17 * @return: java.lang.String 响应结果 **/ public static String sendPost(String url, String param) { PrintWriter out = null; BufferedReader in = null; StringBuilder sb = new StringBuilder(); try { URL realUrl = new URL(url); // 打开和URL之间的连接 URLConnection conn = realUrl.openConnection(); // 设置通用的请求属性 conn.setRequestProperty("accept", "*/*"); conn.setRequestProperty("connection", "Keep-Alive"); conn.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)"); // 发送POST请求必须设置如下两行 conn.setDoOutput(true); conn.setDoInput(true); // 获取URLConnection对象对应的输出流 out = new PrintWriter(conn.getOutputStream()); // 发送请求参数 out.print(param); // flush输出流的缓冲 out.flush(); // 定义BufferedReader输入流来读取URL的响应 in = new BufferedReader( new InputStreamReader(conn.getInputStream())); String line; while ((line = in.readLine()) != null) { sb.append(line); } } catch (Exception e) { System.out.println("发送 POST 请求出现异常!" + e); e.printStackTrace(); } //使用finally块来关闭输出流、输入流 finally { try { if (out != null) { out.close(); } if (in != null) { in.close(); } } catch (IOException ex) { ex.printStackTrace(); } } return sb.toString(); } }
测试结果
控制台输出
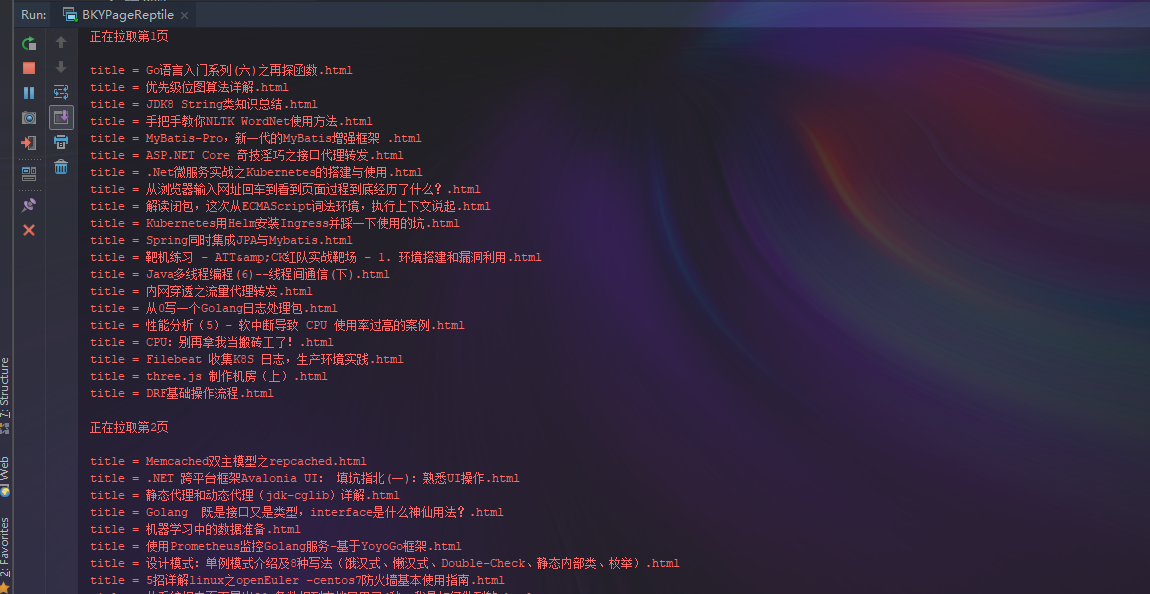
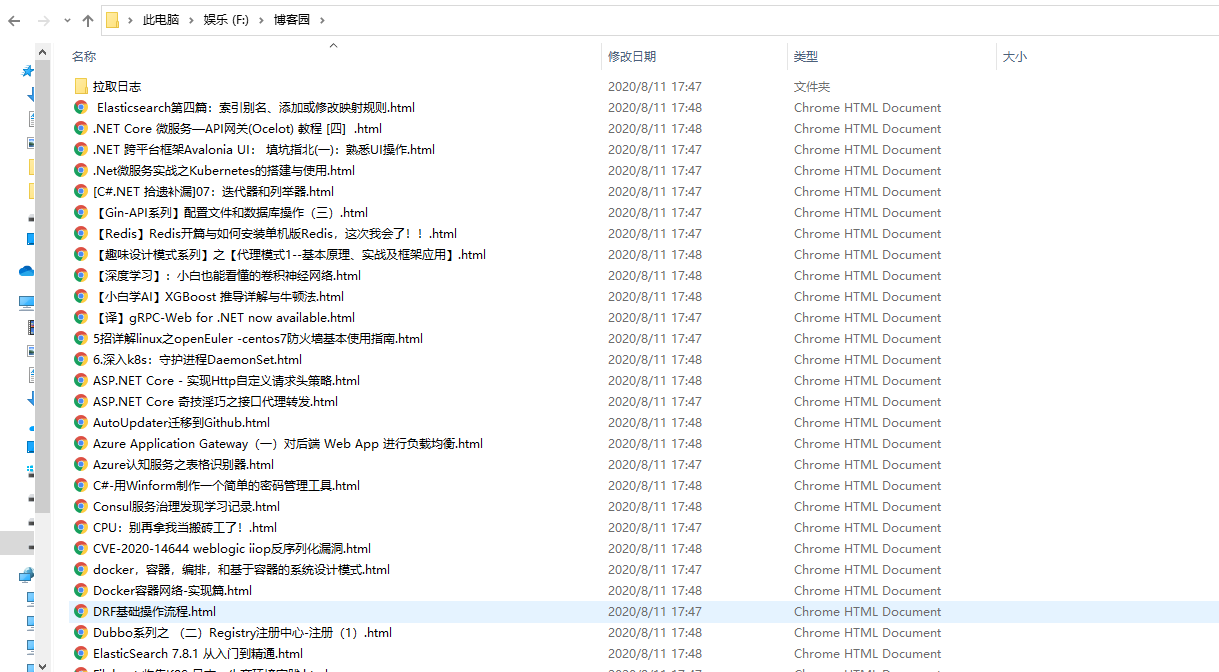
下载在电脑磁盘中
日志文件内容
随便打开一个html文件