import pandas as pd
df=pd.read_excel("./test.xlsx")
df.head()
|
product |
计数项:单位 |
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| 0 |
福临门家宴小麦粉 |
1 |
29.9 |
54.0 |
1 |
27.0 |
| 1 |
福临门老家土榨菜籽油 |
3 |
409.7 |
340.7 |
3 |
340.7 |
| 2 |
福临门麦芯粉面粉 |
4 |
159.6 |
222.0 |
4 |
148.0 |
| 3 |
福临门自然香稻花香 |
4 |
319.6 |
425.4 |
4 |
283.6 |
| 4 |
金龙鱼小榨菜籽油 |
2 |
219.8 |
210.0 |
2 |
210.0 |
可以指定值展示多少行
df.head(3)
|
product |
计数项:单位 |
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| 0 |
福临门家宴小麦粉 |
1 |
29.9 |
54.0 |
1 |
27.0 |
| 1 |
福临门老家土榨菜籽油 |
3 |
409.7 |
340.7 |
3 |
340.7 |
| 2 |
福临门麦芯粉面粉 |
4 |
159.6 |
222.0 |
4 |
148.0 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12 entries, 0 to 11
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 product 12 non-null object
1 计数项:单位 12 non-null int64
2 求和项:原价 12 non-null float64
3 求和项:金额 12 non-null float64
4 计数项:数量 12 non-null int64
5 求和项:团购价 12 non-null float64
dtypes: float64(3), int64(2), object(1)
memory usage: 704.0+ bytes
df.index
RangeIndex(start=0, stop=12, step=1)
df.columns
Index(['product', '计数项:单位', '求和项:原价', '求和项:金额', '计数项:数量', '求和项:团购价'], dtype='object')
df.values
array([['福临门家宴小麦粉', 1, 29.9, 54.0, 1, 27.0],
['福临门老家土榨菜籽油', 3, 409.70000000000005, 340.70000000000005, 3,
340.70000000000005],
['福临门麦芯粉面粉', 4, 159.6, 222.0, 4, 148.0],
['福临门自然香稻花香', 4, 319.6, 425.40000000000003, 4, 283.6],
['金龙鱼小榨菜籽油', 2, 219.8, 210.0, 2, 210.0],
['金苑精制粉', 1, 38.0, 66.0, 1, 33.0],
['龙大铁桶原浆花生油', 1, 185.2, 152.0, 1, 152.0],
['鲁花低芥酸菜籽油', 2, 239.8, 198.0, 2, 198.0],
['鲁花花生油', 1, 165.9, 157.0, 1, 157.0],
['荣平干菜', 6, 716.5, 632.5, 6, 632.5],
['五丰小产地长粒香', 2, 119.8, 165.0, 2, 110.0],
['总计', 32, 2603.8, 5245.200000000001, 32, 2291.8]], dtype=object)
可以自己创建一个dataframe的值
data={'country':['aaa','bbb','ccc'],
'money':[11,22,33]}
df_data=pd.DataFrame(data)
df_data
|
country |
money |
| 0 |
aaa |
11 |
| 1 |
bbb |
22 |
| 2 |
ccc |
33 |
df.info
<bound method DataFrame.info of product 计数项:单位 求和项:原价 求和项:金额 计数项:数量 求和项:团购价
0 福临门家宴小麦粉 1 29.9 54.0 1 27.0
1 福临门老家土榨菜籽油 3 409.7 340.7 3 340.7
2 福临门麦芯粉面粉 4 159.6 222.0 4 148.0
3 福临门自然香稻花香 4 319.6 425.4 4 283.6
4 金龙鱼小榨菜籽油 2 219.8 210.0 2 210.0
5 金苑精制粉 1 38.0 66.0 1 33.0
6 龙大铁桶原浆花生油 1 185.2 152.0 1 152.0
7 鲁花低芥酸菜籽油 2 239.8 198.0 2 198.0
8 鲁花花生油 1 165.9 157.0 1 157.0
9 荣平干菜 6 716.5 632.5 6 632.5
10 五丰小产地长粒香 2 119.8 165.0 2 110.0
11 总计 32 2603.8 5245.2 32 2291.8>
## 取指定的数据
a=df['product']
print(type(a))
a[:2]
<class 'pandas.core.series.Series'>
0 福临门家宴小麦粉
1 福临门老家土榨菜籽油
Name: product, dtype: object
## series是dataframe中的一部分的意思
a.index
RangeIndex(start=0, stop=12, step=1)
a.values[:5]
array(['福临门家宴小麦粉', '福临门老家土榨菜籽油', '福临门麦芯粉面粉', '福临门自然香稻花香', '金龙鱼小榨菜籽油'],
dtype=object)
df.head()
|
product |
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| 计数项:单位 |
|
|
|
|
|
| 1 |
福临门家宴小麦粉 |
29.9 |
54.0 |
1 |
27.0 |
| 3 |
福临门老家土榨菜籽油 |
409.7 |
340.7 |
3 |
340.7 |
| 4 |
福临门麦芯粉面粉 |
159.6 |
222.0 |
4 |
148.0 |
| 4 |
福临门自然香稻花香 |
319.6 |
425.4 |
4 |
283.6 |
| 2 |
金龙鱼小榨菜籽油 |
219.8 |
210.0 |
2 |
210.0 |
## 可以设置索引的列
df=df.set_index('product')#注意:这里使用的是他返回的一张表
df.head()
|
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| product |
|
|
|
|
| 福临门家宴小麦粉 |
29.9 |
54.0 |
1 |
27.0 |
| 福临门老家土榨菜籽油 |
409.7 |
340.7 |
3 |
340.7 |
| 福临门麦芯粉面粉 |
159.6 |
222.0 |
4 |
148.0 |
| 福临门自然香稻花香 |
319.6 |
425.4 |
4 |
283.6 |
| 金龙鱼小榨菜籽油 |
219.8 |
210.0 |
2 |
210.0 |
df['计数项:数量'][:4]
product
福临门家宴小麦粉 1
福临门老家土榨菜籽油 3
福临门麦芯粉面粉 4
福临门自然香稻花香 4
Name: 计数项:数量, dtype: int64
### 这样每个每个所对应的名字再是不好看的列数了
count=df['计数项:数量']
count
product
福临门家宴小麦粉 1
福临门老家土榨菜籽油 3
福临门麦芯粉面粉 4
福临门自然香稻花香 4
金龙鱼小榨菜籽油 2
金苑精制粉 1
龙大铁桶原浆花生油 1
鲁花低芥酸菜籽油 2
鲁花花生油 1
荣平干菜 6
五丰小产地长粒香 2
总计 32
Name: 计数项:数量, dtype: int64
count['福临门麦芯粉面粉']
4
count=count+10
count[:]#
product
福临门家宴小麦粉 11
福临门老家土榨菜籽油 13
福临门麦芯粉面粉 14
福临门自然香稻花香 14
金龙鱼小榨菜籽油 12
金苑精制粉 11
龙大铁桶原浆花生油 11
鲁花低芥酸菜籽油 12
鲁花花生油 11
荣平干菜 16
五丰小产地长粒香 12
总计 42
Name: 计数项:数量, dtype: int64
count=count*count
count
product
福临门家宴小麦粉 121
福临门老家土榨菜籽油 169
福临门麦芯粉面粉 196
福临门自然香稻花香 196
金龙鱼小榨菜籽油 144
金苑精制粉 121
龙大铁桶原浆花生油 121
鲁花低芥酸菜籽油 144
鲁花花生油 121
荣平干菜 256
五丰小产地长粒香 144
总计 1764
Name: 计数项:数量, dtype: int64
## numpy 一样的计算能力
count.max()
1764
count.mean()
291.4166666666667
count.min()
121
.descirbe()可以得到基本的统计特性
df.describe()
|
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| count |
12.000000 |
12.000000 |
12.000000 |
12.000000 |
| mean |
433.966667 |
655.650000 |
4.916667 |
381.966667 |
| std |
707.943261 |
1454.320706 |
8.670308 |
622.677906 |
| min |
29.900000 |
54.000000 |
1.000000 |
27.000000 |
| 25% |
149.650000 |
155.750000 |
1.000000 |
138.500000 |
| 50% |
202.500000 |
204.000000 |
2.000000 |
177.500000 |
| 75% |
342.125000 |
361.875000 |
4.000000 |
297.875000 |
| max |
2603.800000 |
5245.200000 |
32.000000 |
2291.800000 |
Pandas 索引结构
定位一个列
df['计数项:数量']
product
福临门家宴小麦粉 1
福临门老家土榨菜籽油 3
福临门麦芯粉面粉 4
福临门自然香稻花香 4
金龙鱼小榨菜籽油 2
金苑精制粉 1
龙大铁桶原浆花生油 1
鲁花低芥酸菜籽油 2
鲁花花生油 1
荣平干菜 6
五丰小产地长粒香 2
总计 32
Name: 计数项:数量, dtype: int64
定位两个列
df[['求和项:金额','计数项:数量']]#这里有两层
|
求和项:金额 |
计数项:数量 |
| product |
|
|
| 福临门家宴小麦粉 |
54.0 |
1 |
| 福临门老家土榨菜籽油 |
340.7 |
3 |
| 福临门麦芯粉面粉 |
222.0 |
4 |
| 福临门自然香稻花香 |
425.4 |
4 |
| 金龙鱼小榨菜籽油 |
210.0 |
2 |
| 金苑精制粉 |
66.0 |
1 |
| 龙大铁桶原浆花生油 |
152.0 |
1 |
| 鲁花低芥酸菜籽油 |
198.0 |
2 |
| 鲁花花生油 |
157.0 |
1 |
| 荣平干菜 |
632.5 |
6 |
| 五丰小产地长粒香 |
165.0 |
2 |
| 总计 |
5245.2 |
32 |
指定索引
- loc 指定lable索引
- iloc 指定position索引
df[0]#不允许这样索引
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File e:\anaconda\lib\site-packages\pandas\core\indexes\base.py:3621, in Index.get_loc(self, key, method, tolerance)
3620 try:
-> 3621 return self._engine.get_loc(casted_key)
3622 except KeyError as err:
File e:\anaconda\lib\site-packages\pandas\_libs\index.pyx:136, in pandas._libs.index.IndexEngine.get_loc()
File e:\anaconda\lib\site-packages\pandas\_libs\index.pyx:163, in pandas._libs.index.IndexEngine.get_loc()
File pandas\_libs\hashtable_class_helper.pxi:5198, in pandas._libs.hashtable.PyObjectHashTable.get_item()
File pandas\_libs\hashtable_class_helper.pxi:5206, in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 0
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
f:\文档\panda汇总.ipynb 单元格 38 in <cell line: 1>()
----> <a href='vscode-notebook-cell:/f%3A/%E6%96%87%E6%A1%A3/panda%E6%B1%87%E6%80%BB.ipynb#X61sZmlsZQ%3D%3D?line=0'>1</a> df[0]
File e:\anaconda\lib\site-packages\pandas\core\frame.py:3505, in DataFrame.__getitem__(self, key)
3503 if self.columns.nlevels > 1:
3504 return self._getitem_multilevel(key)
-> 3505 indexer = self.columns.get_loc(key)
3506 if is_integer(indexer):
3507 indexer = [indexer]
File e:\anaconda\lib\site-packages\pandas\core\indexes\base.py:3623, in Index.get_loc(self, key, method, tolerance)
3621 return self._engine.get_loc(casted_key)
3622 except KeyError as err:
-> 3623 raise KeyError(key) from err
3624 except TypeError:
3625 # If we have a listlike key, _check_indexing_error will raise
3626 # InvalidIndexError. Otherwise we fall through and re-raise
3627 # the TypeError.
3628 self._check_indexing_error(key)
KeyError: 0
df.iloc[0]
求和项:原价 29.9
求和项:金额 54.0
计数项:数量 1.0
求和项:团购价 27.0
Name: 福临门家宴小麦粉, dtype: float64
df.iloc[0:5]
|
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| product |
|
|
|
|
| 福临门家宴小麦粉 |
29.9 |
54.0 |
1 |
27.0 |
| 福临门老家土榨菜籽油 |
409.7 |
340.7 |
3 |
340.7 |
| 福临门麦芯粉面粉 |
159.6 |
222.0 |
4 |
148.0 |
| 福临门自然香稻花香 |
319.6 |
425.4 |
4 |
283.6 |
| 金龙鱼小榨菜籽油 |
219.8 |
210.0 |
2 |
210.0 |
df.iloc[0:5][0:2]
|
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| product |
|
|
|
|
| 福临门家宴小麦粉 |
29.9 |
54.0 |
1 |
27.0 |
| 福临门老家土榨菜籽油 |
409.7 |
340.7 |
3 |
340.7 |
df.loc['福临门老家土榨菜籽油']
求和项:原价 409.7
求和项:金额 340.7
计数项:数量 3.0
求和项:团购价 340.7
Name: 福临门老家土榨菜籽油, dtype: float64
df.loc['福临门老家土榨菜籽油','求和项:原价']
409.70000000000005
df.loc['福临门老家土榨菜籽油':'金龙鱼小榨菜籽油',:]
|
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| product |
|
|
|
|
| 福临门老家土榨菜籽油 |
409.7 |
340.7 |
3 |
340.7 |
| 福临门麦芯粉面粉 |
159.6 |
222.0 |
4 |
148.0 |
| 福临门自然香稻花香 |
319.6 |
425.4 |
4 |
283.6 |
| 金龙鱼小榨菜籽油 |
219.8 |
210.0 |
2 |
210.0 |
df.loc['福临门老家土榨菜籽油','求和项:原价']=99999
df.head()
|
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| product |
|
|
|
|
| 福临门家宴小麦粉 |
29.9 |
54.0 |
1 |
27.0 |
| 福临门老家土榨菜籽油 |
99999.0 |
340.7 |
3 |
340.7 |
| 福临门麦芯粉面粉 |
159.6 |
222.0 |
4 |
148.0 |
| 福临门自然香稻花香 |
319.6 |
425.4 |
4 |
283.6 |
| 金龙鱼小榨菜籽油 |
219.8 |
210.0 |
2 |
210.0 |
bool类型索引
df['求和项:原价']>199
product
福临门家宴小麦粉 False
福临门老家土榨菜籽油 True
福临门麦芯粉面粉 False
福临门自然香稻花香 True
金龙鱼小榨菜籽油 True
金苑精制粉 False
龙大铁桶原浆花生油 False
鲁花低芥酸菜籽油 True
鲁花花生油 False
荣平干菜 True
五丰小产地长粒香 False
总计 True
Name: 求和项:原价, dtype: bool
## 然后再用这个bool进行索引
df[df['求和项:原价']>199]
|
求和项:原价 |
求和项:金额 |
计数项:数量 |
求和项:团购价 |
| product |
|
|
|
|
| 福临门老家土榨菜籽油 |
99999.0 |
340.7 |
3 |
340.7 |
| 福临门自然香稻花香 |
319.6 |
425.4 |
4 |
283.6 |
| 金龙鱼小榨菜籽油 |
219.8 |
210.0 |
2 |
210.0 |
| 鲁花低芥酸菜籽油 |
239.8 |
198.0 |
2 |
198.0 |
| 荣平干菜 |
716.5 |
632.5 |
6 |
632.5 |
| 总计 |
2603.8 |
5245.2 |
32 |
2291.8 |
df.loc['福临门自然香稻花香','求和项:原价']#loc前面行的范围,后面是列的范围
319.6
df.loc[df['求和项:原价']>100,'求和项:团购价']#在原价大于100的数据里看团购价的值
product
福临门老家土榨菜籽油 340.7
福临门麦芯粉面粉 148.0
福临门自然香稻花香 283.6
金龙鱼小榨菜籽油 210.0
龙大铁桶原浆花生油 152.0
鲁花低芥酸菜籽油 198.0
鲁花花生油 157.0
荣平干菜 632.5
五丰小产地长粒香 110.0
总计 2291.8
Name: 求和项:团购价, dtype: float64
#然后求一下,团购价最高的产品的价钱
df.loc[df['求和项:原价']>100,'求和项:团购价'].max()
2291.8
group by语句
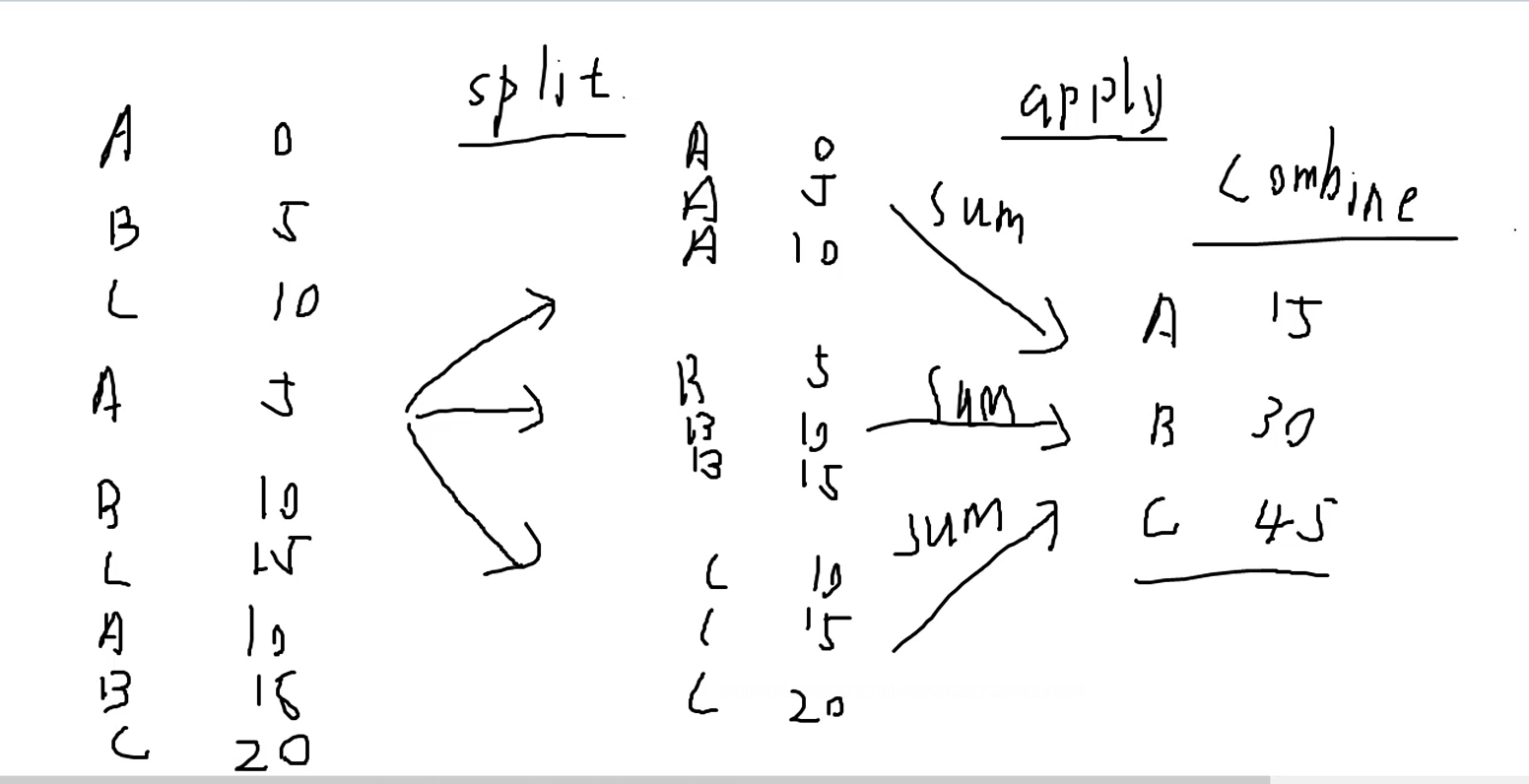
import pandas as pd
df=pd.read_excel('./test.xlsx')
test=pd.DataFrame({'name':['A','X','W','B','B','A','W','X','C','A','B'],
'num':[1,3,4,5,6,3,1,3,4,1,2]})
test.head(10)
|
name |
num |
| 0 |
A |
1 |
| 1 |
X |
3 |
| 2 |
W |
4 |
| 3 |
B |
5 |
| 4 |
B |
6 |
| 5 |
A |
3 |
| 6 |
W |
1 |
| 7 |
X |
3 |
| 8 |
C |
4 |
| 9 |
A |
1 |
for i in test['name']:
print(i,test[test['name']==i].sum())
A name AAA
num 5
dtype: object
X name XX
num 6
dtype: object
W name WW
num 5
dtype: object
B name BBB
num 13
dtype: object
B name BBB
num 13
dtype: object
A name AAA
num 5
dtype: object
W name WW
num 5
dtype: object
X name XX
num 6
dtype: object
C name C
num 4
dtype: object
A name AAA
num 5
dtype: object
B name BBB
num 13
dtype: object
可以看到这样索引比较麻烦,我们使用group by
test.groupby('name').sum()
|
num |
| name |
|
| A |
5 |
| B |
13 |
| C |
4 |
| W |
5 |
| X |
6 |
import numpy as np
test.groupby('name').aggregate(np.mean)
|
num |
| name |
|
| A |
1.666667 |
| B |
4.333333 |
| C |
4.000000 |
| W |
2.500000 |
| X |
3.000000 |
df.groupby('product')['求和项:团购价'].max()
product
五丰小产地长粒香 110.0
总计 2291.8
福临门家宴小麦粉 27.0
福临门老家土榨菜籽油 340.7
福临门自然香稻花香 283.6
福临门麦芯粉面粉 148.0
荣平干菜 632.5
金苑精制粉 33.0
金龙鱼小榨菜籽油 210.0
鲁花低芥酸菜籽油 198.0
鲁花花生油 157.0
龙大铁桶原浆花生油 152.0
Name: 求和项:团购价, dtype: float64