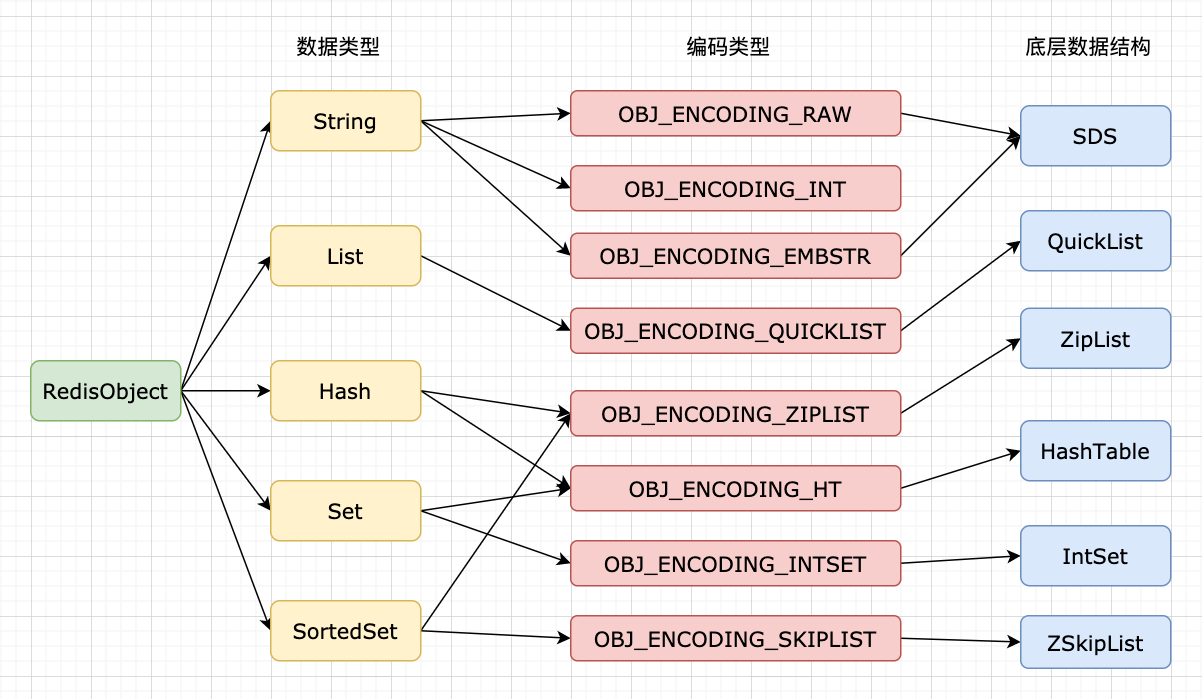
为什么需要消息队列
削峰
业务系统在超高并发场景中,由于后端服务来不及同步处理过多、过快的请求,可能导致请求堵塞,严重时可能由于高负荷拖垮Web服务器。
为了能支持最高峰流量,我们通常采取短平快的方式——直接扩容服务器,增加服务端的吞吐量。
优点是显而易见的,短时间内吞吐量增加了好几倍,甚至数十倍。缺点也明显,流量低峰期服务器相对较闲。
消息队列(比如 Apache RocketMQ,Apache Kafka),也是目前业界比较常用的手段
解耦
不同的业务端在联合开发功能时,常常由于排期不同、人员调配不方便等原因导致项目延期。其实,其根本原因是业务耦合过度。
上下游系统之间的通信是彼此依赖的,所以不得不协调上下游所有的资源同步进行,跨团队处理问题显然比在团队内部处理问题难度大。
你是否依稀记得另一个团队的同事调用你的API,你告诉他发个请求过来,你打断点一步一步调试代码的场景?
你是否记得为了协调开发资源、QA 资源,以及协调上线时间等所做的一切,你被老板骂了多少次,最后还是延期了:我们依赖他们,他们的QA说,高峰期不让发布。
加入消息队列后,不同的业务端又会是何种情况呢?上下游系统进行开发、联调、上线,彼此完全不依赖,也就是说,系统间解耦了
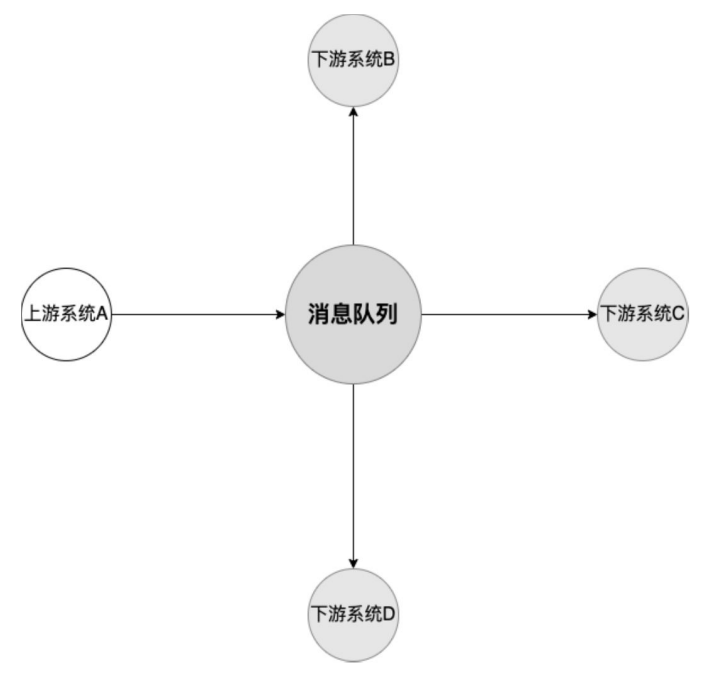
异步
处理订票请求是一个漫长的过程,需要检查预订的车次是否有预订数量的票、下单扣库存、更新缓存等一系列操作。这些耗时的操作,我们可以通过使用消息队列的方式,把提交请求成功的消息告诉用户
数据一致性
消息系统的优点:
(1)免去了多次重试(发起请求)的复杂逻辑。
(2)免去了处理过多重试请求的压力。
(3)即使服务不可用,业务也不受影响。
常见消息队列
| 消息队列名字 | Apache ActiveMQ | Apache Kafka | Apache RocketMQ |
|---|---|---|---|
| 产生时间 | 2007 | 2012 | 2017 |
| 贡献公司 | Apache | 阿里巴巴 | |
| 当时流行MQ | JMS | ActiveMO | Kafka,ActiveMO |
| 特性 | (1)支持协议众多:AMOP,STOMP,MOTT,JMS (2)消息是持久化的JDBC |
(1)超高写入速率 (2)end-to-end 耗时毫秒级 |
(1)万亿级消息支持 (2)万级Topic数量支持 (3)end-to-end耗时毫秒级 |
| 管理后台 | 自带 | 独立部署 | 独立部署 |
| 多语言客户端 | 支持 | 支持 | Java、C++、Python、Go、C# |
| 数据流支持 | 不支持 | 支持 | 支持 |
| 消息丢失 | 理论上不会丢失 | 理论上不会丢失 | 理论上不会丢失 |
| 文档完备性 | 好 | 极好 | 极好 |
| 商业公司实践 | 国内部分企业 | 阿里巴巴 | |
| 容错 | 无重试机制 | 无重试机制 | 支持重试,死信消息 |
| 顺序消息 | 支持 | 支持 | 支持 |
| 定时消息 | 不支持 | 不支持 | 支持 |
| 事务消息 | 不支持 | 支持 | 支持 |
| 消息轨迹 | 不支持 | 不支持 | 支持 |
| 消息查询 | 数据库中查询 | 不支持 | 支持 |
| 重放消息 | 不清楚 | 暂停重放 | 实时重放 |
| 宕机 | 自动切换 | 自动选主 | 手动重启 |