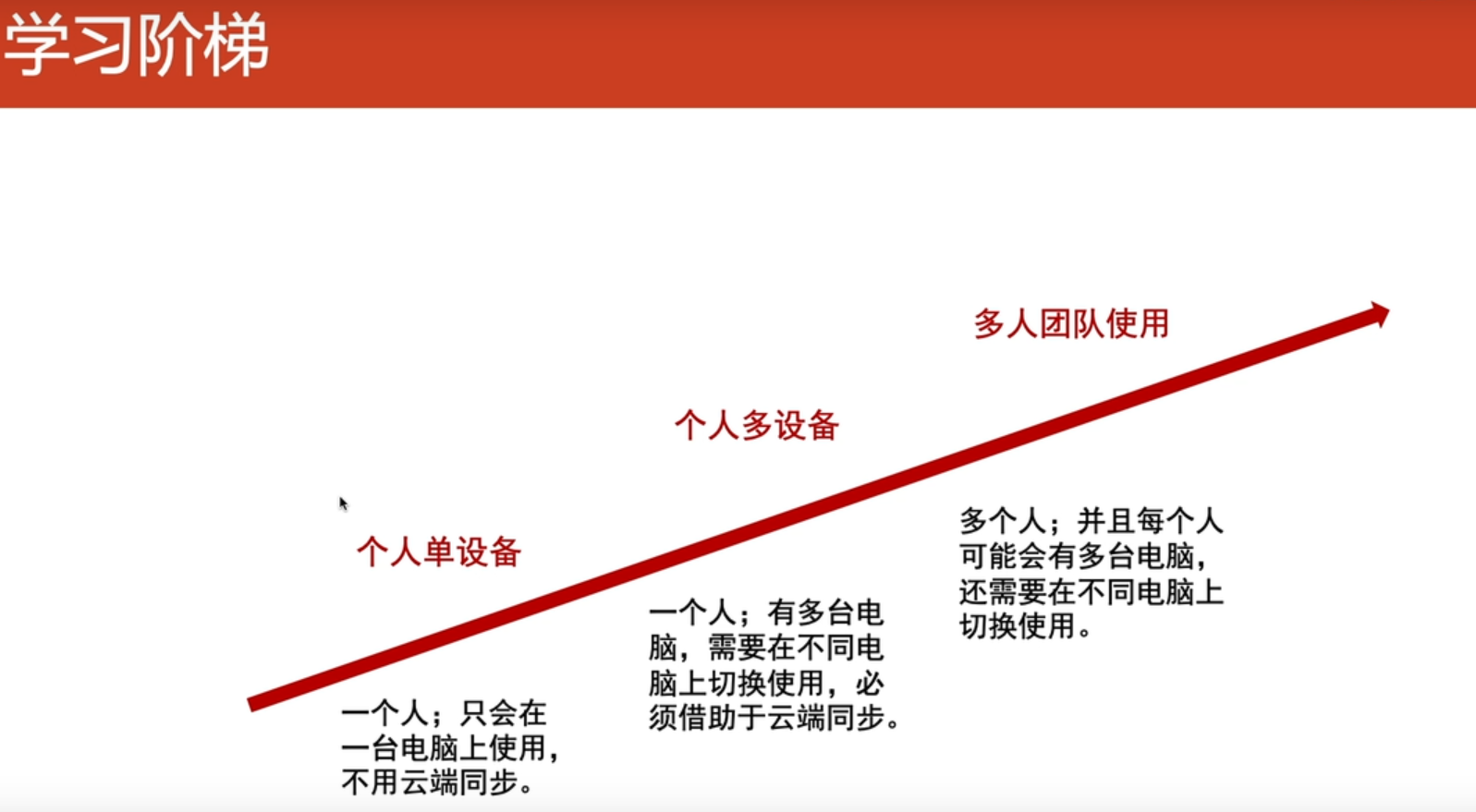
安装依赖
首先保证您的电脑里有 Python 3,且 Python 在环境变量中。
运行:
Windows
python -m pip install requests
python -m pip install bs4
NOI Linux
python3 -m pip install requests
python3 -m pip install bs4
使用方法
- 将代码中的
账号名,密码,账户ID,截止时间设置成自己想要的。 - 输入验证码时,工作目录下会生成
captcha.jpg中,您可以打开查看。 - 结束后,请查看工作目录下的
进程表.md。
代码
import requests, re, urllib, json, bs4
import time as tim
账号名 = ""
账户ID =
密码 = ""
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.70",
"referer" : "https://www.luogu.com.cn/"
}
session = requests.session()
main = session.get("http://www.luogu.com.cn/", headers=headers).text
headers["x-csrf-token"] = bs4.BeautifulSoup(main, "html.parser").select_one("meta[name=\"csrf-token\"]").attrs["content"]
data = session.get("https://www.luogu.com.cn/auth/login", headers=headers).text
def get_data(text):
return json.loads(urllib.parse.unquote(re.findall(r"JSON.parse\(decodeURIComponent\(\".*\"\)\)", text)[0].split("\"")[1].split("\"")[0]))
data = get_data(data)
captcha = session.get("https://www.luogu.com.cn/api/verify/captcha?_t=" + str(
data["currentTime"]
), headers=headers).content
with open("captcha.jpg", "wb") as f:
f.write(captcha)
captcha = input("输入验证码:")
syncToken = session.post("https://www.luogu.com.cn/api/auth/userPassLogin", headers=headers, json={
"username" : 账号名,
"password" : 密码,
"captcha" : captcha
}).json()
print(syncToken)
syncToken=syncToken["syncToken"]
session.post("https://www.luogu.org/api/auth/syncLogin", headers, json = {"syncToken" : syncToken})
page = 1
end = True
截止日期 = "2023-01-08"
endtime = tim.mktime(tim.strptime(截止日期, "%Y-%m-%d"))
problems = {}
while end:
print("https://www.luogu.com.cn/record/list?user=%d&page=%d&status=12" % (账户ID, page))
data = get_data(session.get("https://www.luogu.com.cn/record/list?user=%d&page=%d&status=12" % (账户ID, page), headers=headers).text)["currentData"]
record = data["records"]["result"]
if len(record) == 0:
break
for i in record:
time = i["submitTime"]
if time < endtime:
end = False
break
date = tim.strftime("%Y 年 %m 月 %d 日", tim.localtime(time))
if problems.get(date) is None:
problems[date] = []
problems[date].append({
"name" : i["problem"]["pid"] + " " + i["problem"]["title"],
"difficulty" : i["problem"]["difficulty"],
"link" : "https://www.luogu.com.cn/problem/%s" % i["problem"]["pid"]
})
page += 1
difficulties = ["暂无评定", "入门", "普及-", "普及/提高-", "普及+/提高", "提高+/省选-", "省选/NOI-", "NOI/NOI+/CTSC"]
maps = dict()
with open("进程表.md", "w", encoding="utf-8") as f:
for i in problems:
pro = []
for j in problems[i]:
if maps.get(j["name"]) is None:
pro.append(j)
maps[j["name"]]=114514
f.write("\n\n## %s\n\n" % i)
if len(pro) == 0:
continue
f.write("| 题目名 | 难度 | 备注 |\n| :--: | :--: | :--: |\n")
for j in pro:
f.write("| [%s](%s) | %s | |\n" % (j["name"], j["link"], difficulties[j["difficulty"]]))