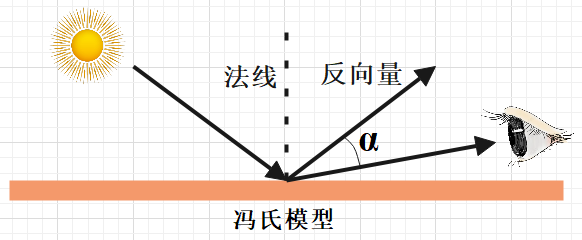
刚学正则表达式的时候,惰性匹配还挺难理解的。所以我看了挺多博客,终于弄懂了,现在用表格整理一下:
| 符号 | 作用 |
|---|---|
| . | 匹配任意除换行符 \n 外的字符 |
| * | 匹配前面的字符 0 次或多次 |
| + | 匹配前面的字符 1 次或多次 |
| ? | 匹配前面的字符零次或一次,或作为非贪婪限定符 |
| .* | 匹配除换行符 \n 外的任意字符 0 次或多次 |
| .+ | 匹配除换行符 \n 外的任意字符 1 次或多次 |
| .*? | 匹配除换行符 \n 外的任意字符 0 次或多次,但匹配结果尽可能短 |
| .+? | 匹配除换行符 \n 外的任意字符 0 次或多次,但匹配结果尽可能短 |
上面表格中最后两行的 ? 的作用就是指明一个非贪婪限定符,什么叫尽可能少重复?简单点说就是匹配最短的符合要求的表达式,如果不加 ?,默认匹配满足要求的最长的字符串,下面举出例子:
示例一(.*?)
re.match(r'a.*b', 'aababa') # 1
re.match(r'a.*?b', 'aababa') # 2
- 1 式没有非贪婪限定符,匹配满足要求的最长表达式,结果为 aabab
- 2 式有非贪婪限定符,结果尽可能短,因此结果为 aab。但是!到这里字符串还没有匹配完,还会继续匹配直到最后一个字符,因此最终的结果是两个,aab 和 ab
示例二(.+?)
re.match(r'a.+?b', 'aababa') # 3
同理 .+? 也一样,只不过和 .*? 比起来,这里最后的结果不包括匹配 0 次的情况而已,所以 3 式结果为 aab,ab 由于中间匹配 0 次,不会被匹配。
较难一点的示例
re.match(r'hello.*?world', 'xxxhelloworldxxhelloxxworld' # 4
通过上面的解析,结果显而易见:helloworld 和 helloxxworld。至于为什么没有 helloworldxxhelloxxworld,相信你也清楚了。






![[数据结构] 稀疏矩阵的加法与乘法](https://img2023.cnblogs.com/blog/3039354/202302/3039354-20230219180218837-1606393782.jpg)


![[软件设计] 软件系统总体结构设计 | 软件架构概述 [转载]](https://img2023.cnblogs.com/blog/1173617/202303/1173617-20230325231804467-1077074750.png)