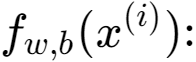在Python中,可以使用多种方法处理数据中的空值,以下是一些常见的处理方法:
1、删除空值:可以使用pandas库中的dropna方法删除数据中的空值,例如:
import pandas as pd
df = pd.read_csv("data.csv")
df = df.dropna()2、填充空值:可以使用fillna方法将数据中的空值填充为指定的值,例如:
import pandas as pd
df = pd.read_csv("data.csv")
df = df.fillna(0)其中,0可以替换为其他值,例如均值、中位数等。
3、插值:可以使用interpolate方法对数据中的空值进行插值,例如:
import pandas as pd
df = pd.read_csv("data.csv")
df = df.interpolate()4、使用机器学习模型:可以使用机器学习模型对数据中的空值进行预测并填充,例如使用线性回归模型:
import pandas as pd
from sklearn.linear_model import LinearRegression
df = pd.read_csv("data.csv")
model = LinearRegression()
X = df.dropna().drop("target", axis=1)
y = df.dropna()["target"]
model.fit(X, y)
X_pred = df[df["target"].isna()].drop("target", axis=1)
y_pred = model.predict(X_pred)
df.loc[df["target"].isna(), "target"] = y_pred其中,target是需要填充的列名,可以根据具体情况进行替换。
5、预处理数据时避免产生空值:在进行数据预处理时,应尽量避免产生空值,例如通过删除缺失值较多的列、进行合适的特征选择等方法来降低数据中的空值数量。同时,对于某些需要填充的数据,也应尽量使用更加可靠的方法进行填充。
注意,在处理数据中的空值时,需要根据具体情况进行选择和调整处理方法,以避免对数据的质量和准确性造成影响。有些情况下,不同的方法可能会对数据产生不同的影响,例如使用均值填充可能会导致数据分布变形,使用插值方法可能会产生过拟合等问题。因此,在进行数据处理时,需要进行多种处理方法的比较和实验,以确定最适合当前数据的处理方法。同时,在使用机器学习模型进行预测和填充时,需要保证模型的准确性和可靠性。