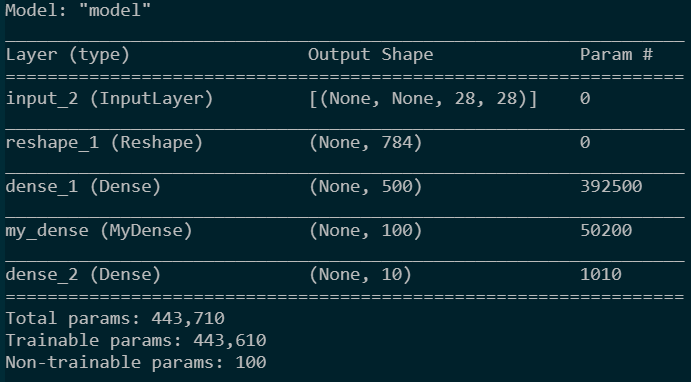
正则表达式
正则表达式描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
(说人话就是匹配字符串的简便方法)
本文采用regex101进行测试
限定符(Quantifier)
1) ?:即匹配该符号前的字符出现0次或者1次的文本
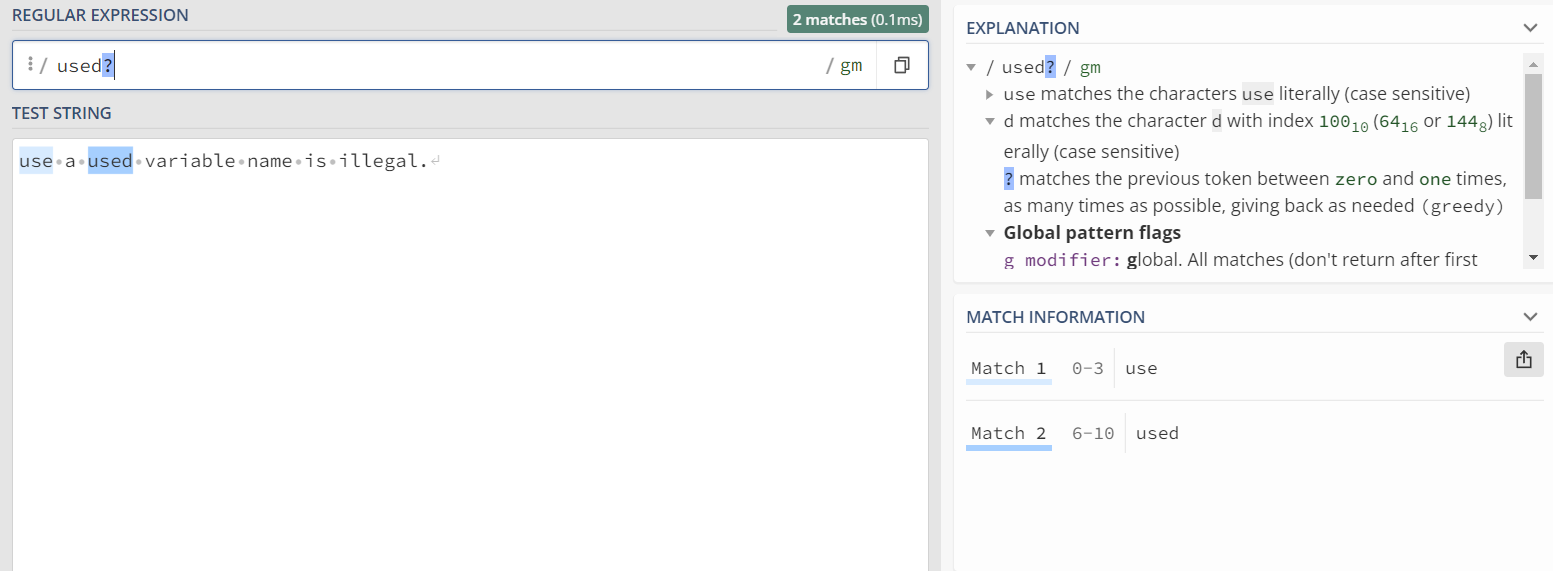
use出现 'use' 字符且 'd' 未出现即匹配成功,used出现 'use' 字符且 'd' 出现一次也匹配成功。
2) * :即匹配该符号前的字符出现0次或者多次的文本
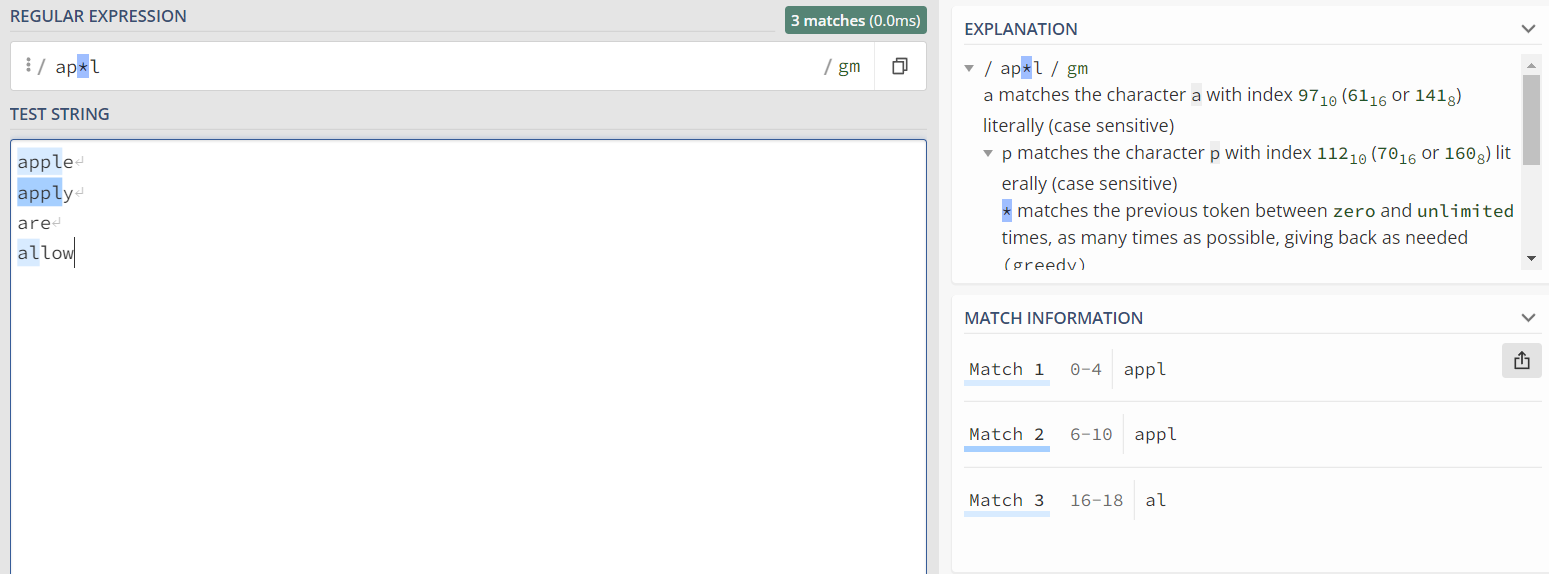
'p'字符出现多次则apple和apply匹配成功,未出现则allow匹配成功。两种情况前后均有'a'和'l'字符。
3)+ :即匹配该符号前的字符出现1次或者多次的文本
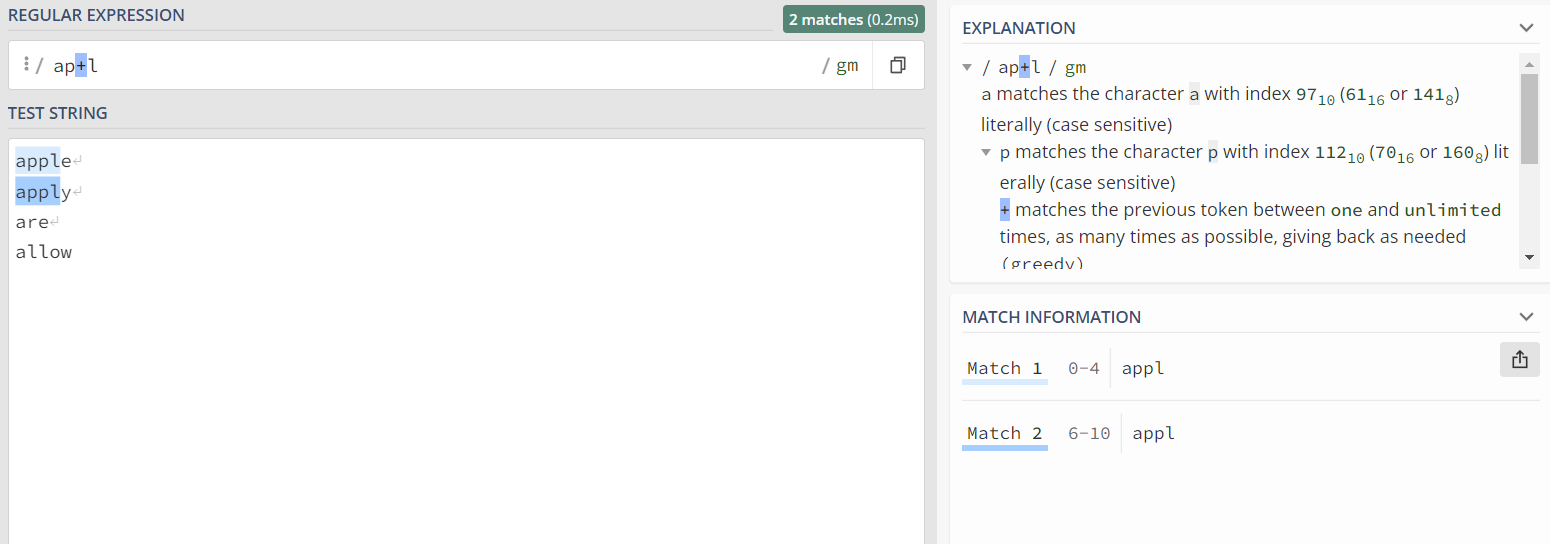
p字符出现1次和多次的apple、apply匹配成功。
4){ } :即匹配该符号前的字符出现花括号内范围的文本(共三种情况)
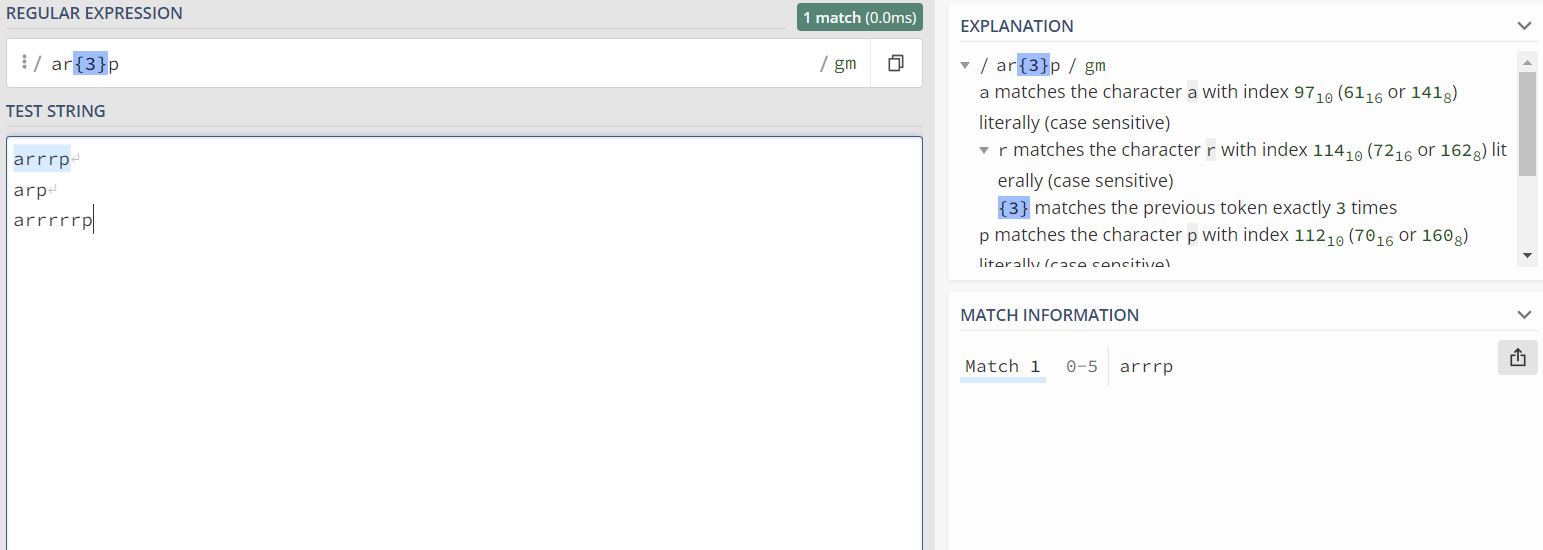
① {n} :匹配出现n次的字符
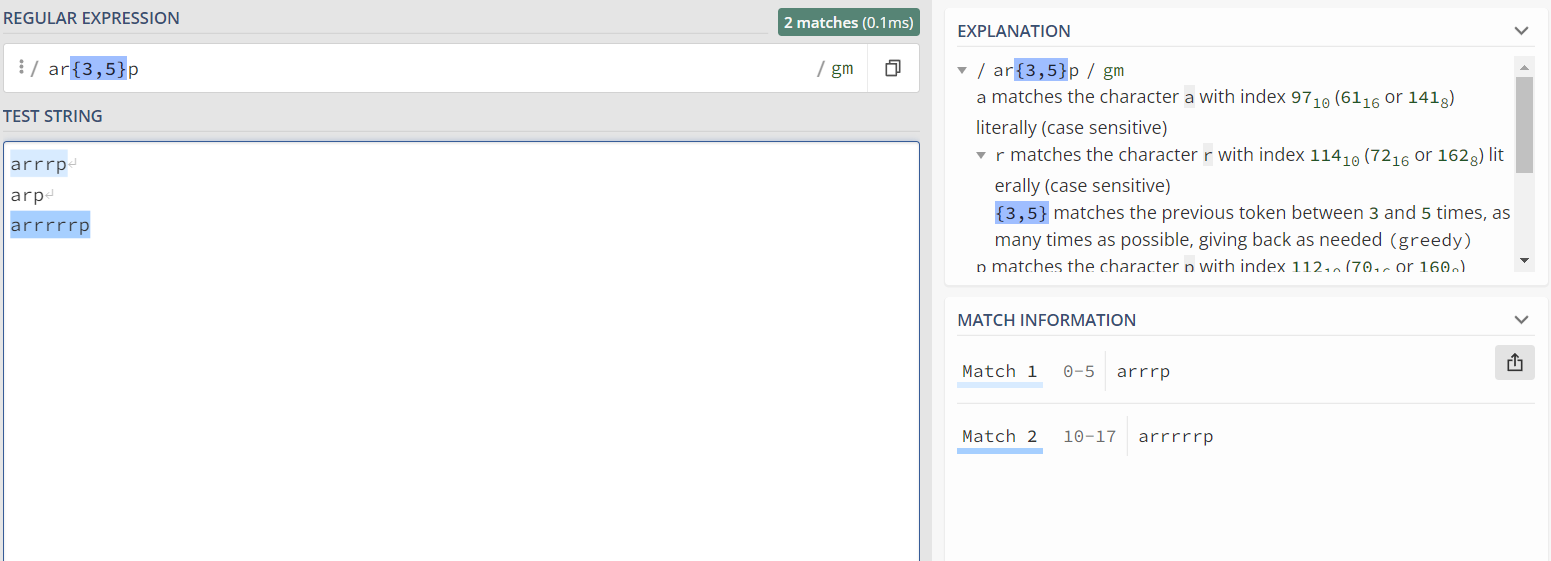
② {n,m} :匹配出现n次到m次的字符
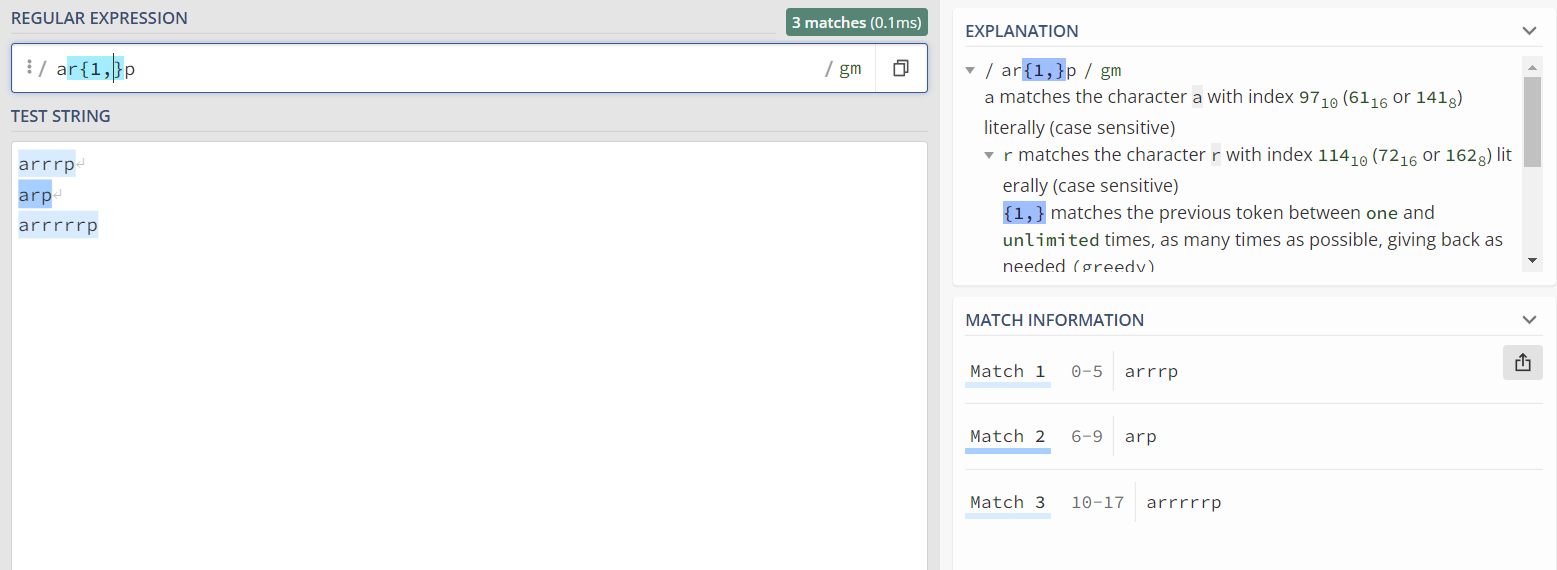
③ {n,} :匹配出现n次即以上的字符
或运算符(OR Operator)
1)(a|b) :即匹配a或者b的文本
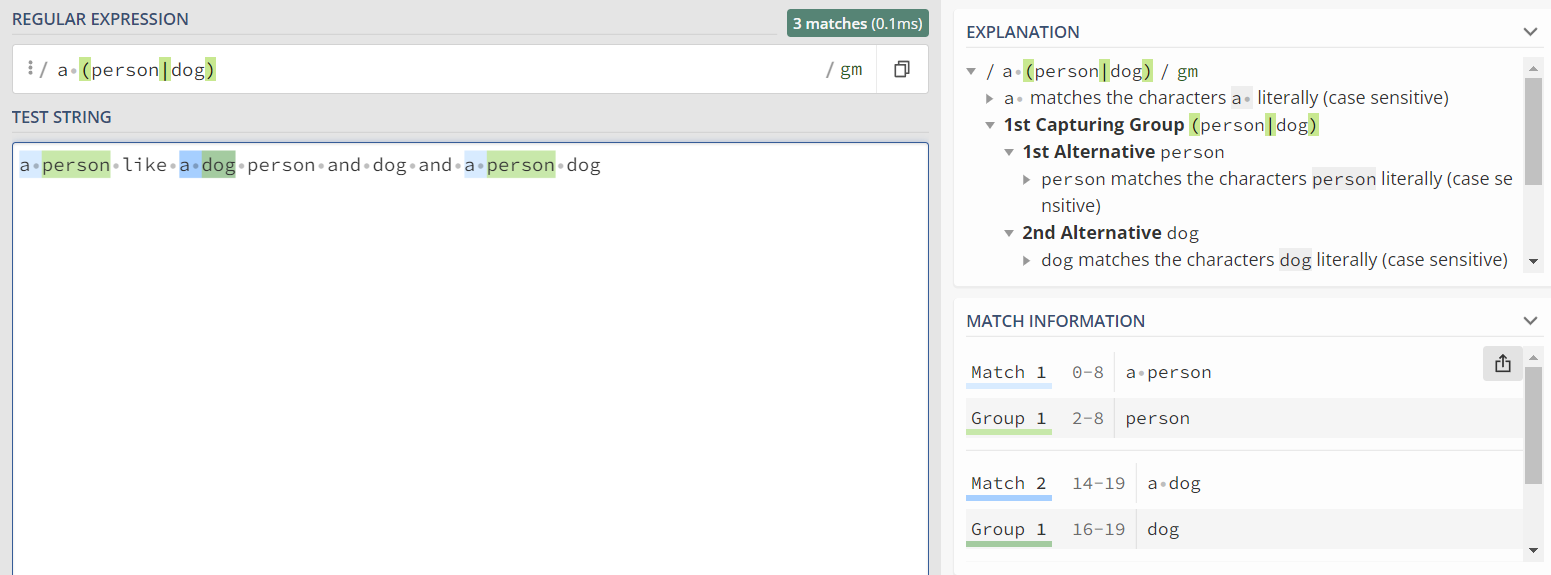
先匹配"a "的情况再匹配后面是person或者dog的情况
字符类(Character Classes)
1)[abc] :即匹配包含abc的文本 (通常与+一起使用)
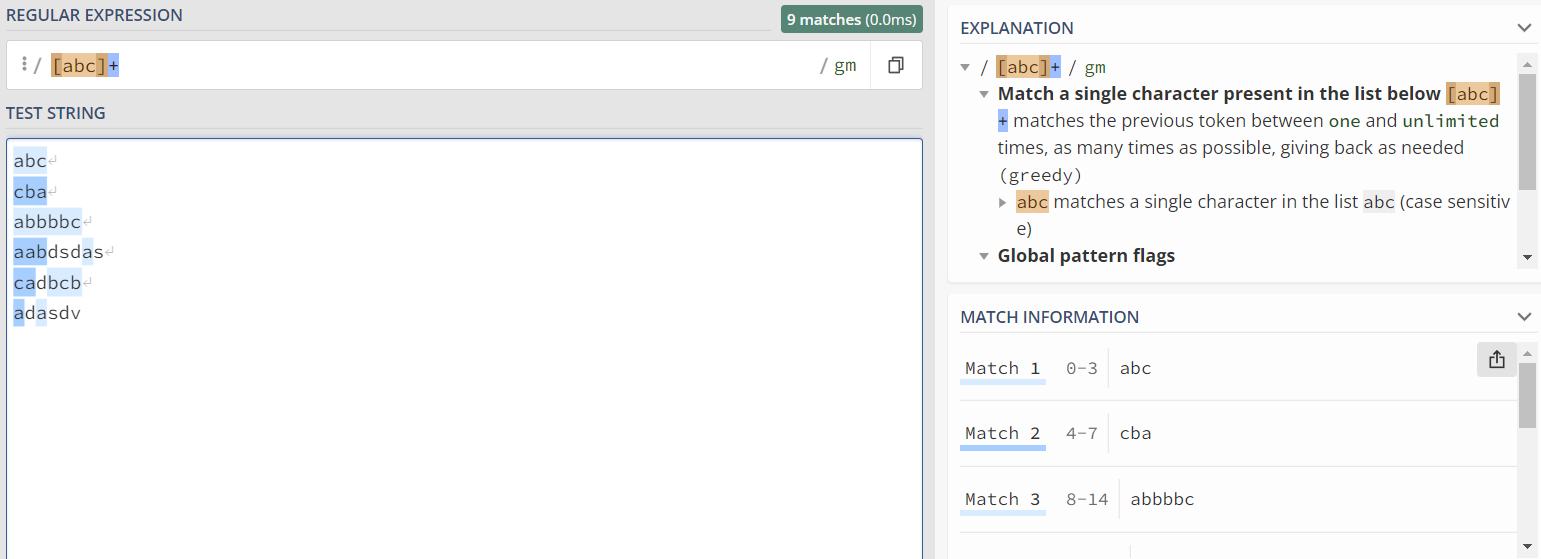
包含'a' 'b' 'c' 字符的文本均匹配成功
2)[a-zA-Z] :即匹配a到z和A-Z的文本 (即匹配所有英文字符)
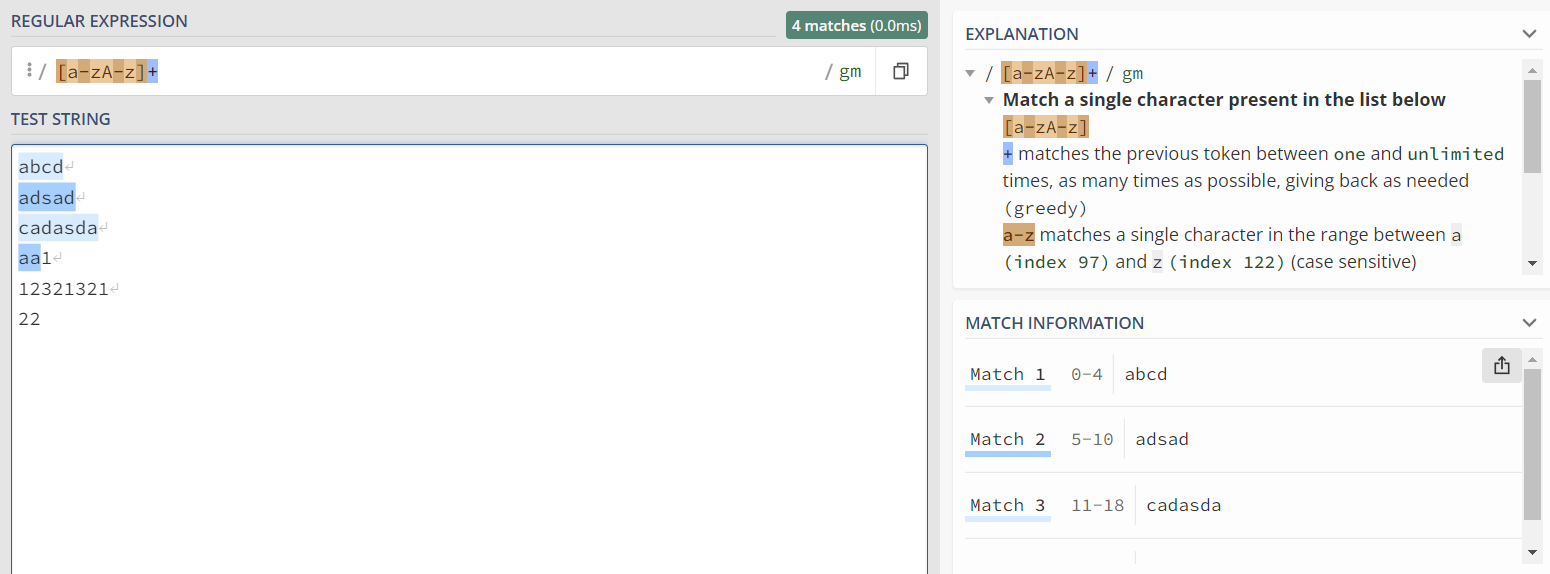
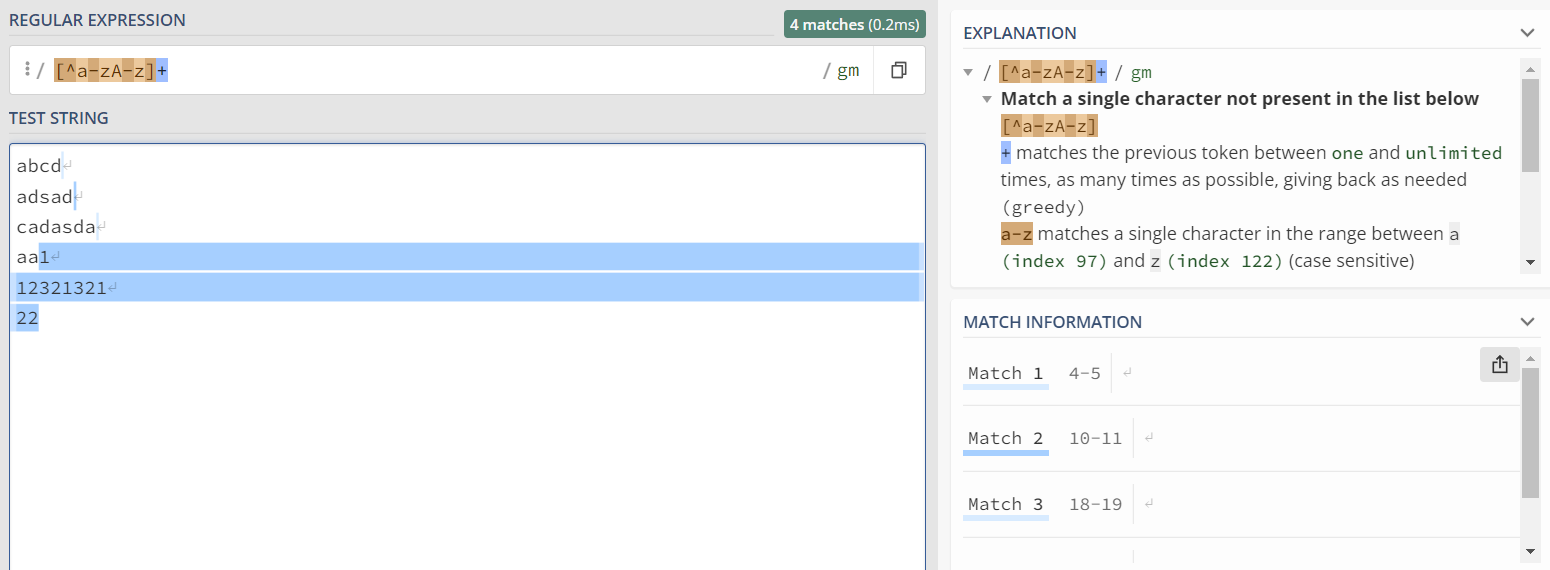
3)[^a-z] :即匹配不包含a到z的文本 (^代表除后续范围的匹配情况)
元字符类(Meta-characters)
\d : 匹配数字字符
\D :匹配非数字字符
\w :匹配单词字符(英文、数字、下划线)
\s :匹配空白符(包含换行符、Tab)
. :匹配任意字符(换行符除外)
^ :匹配行首
$ :匹配行尾
贪婪/懒惰匹配(Greedy / Lazy Match)
* + {} 默认会去匹配尽可能多的字符
例如我们想匹配html标签 此时便为贪婪匹配,'.+'会尽可能多的去匹配字符。
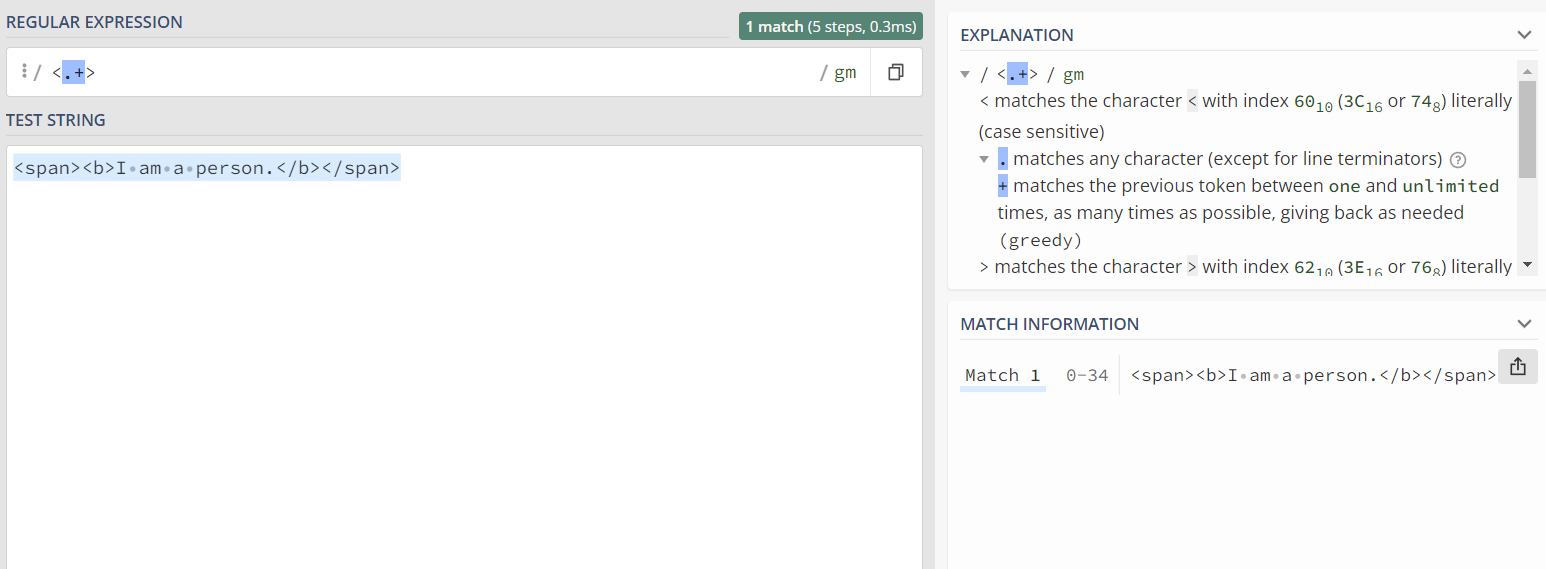
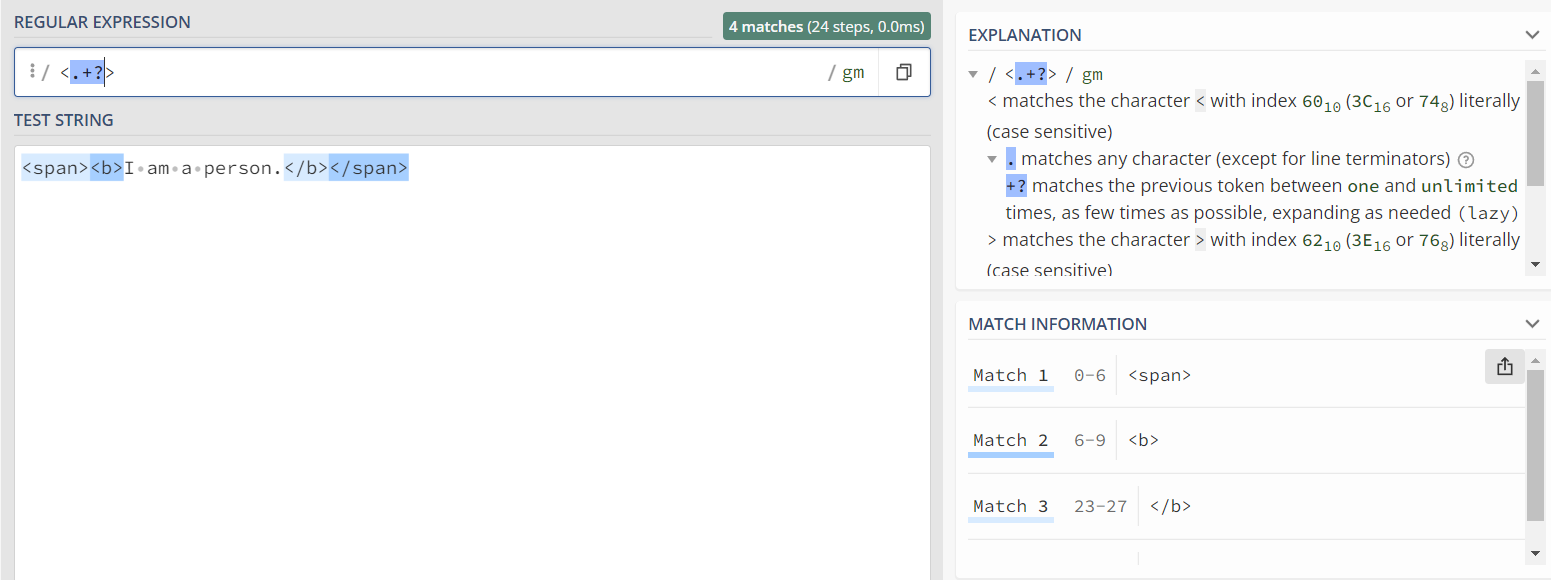
解决方法便是<.+?>将贪婪匹配转化为懒惰匹配
例题实例:
1. RGB颜色值匹配

首先#进行查询,然后[]选取可能出现的a到f、A到F、0到9的可能字符,{}确定长度大小为6,最后使用\b确定边界避免未设置边界长度的#aaaaaaaa也匹配成功。
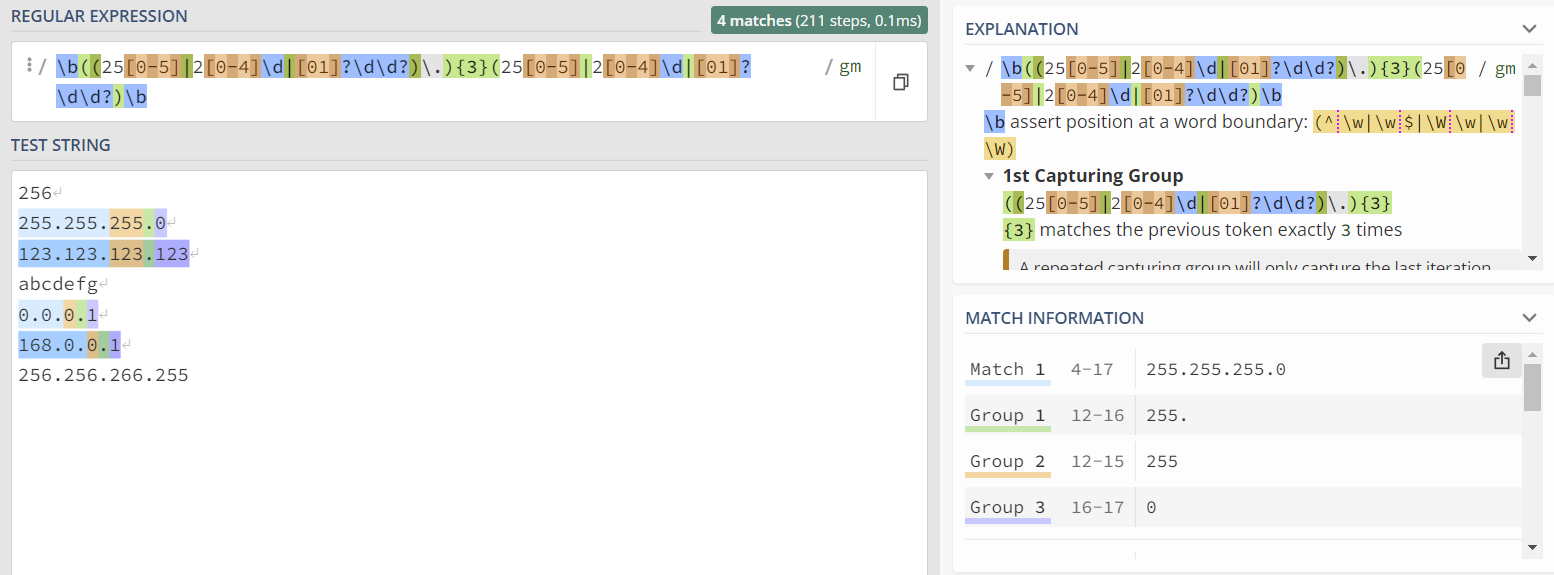
2. IPv4地址匹配
由于ip地址分四段,故我们可以使用\d+\.\d+\.\d+\.+\d+进行匹配:\d+会匹配任何长度大于1的数字,\. 代表转义后的 .
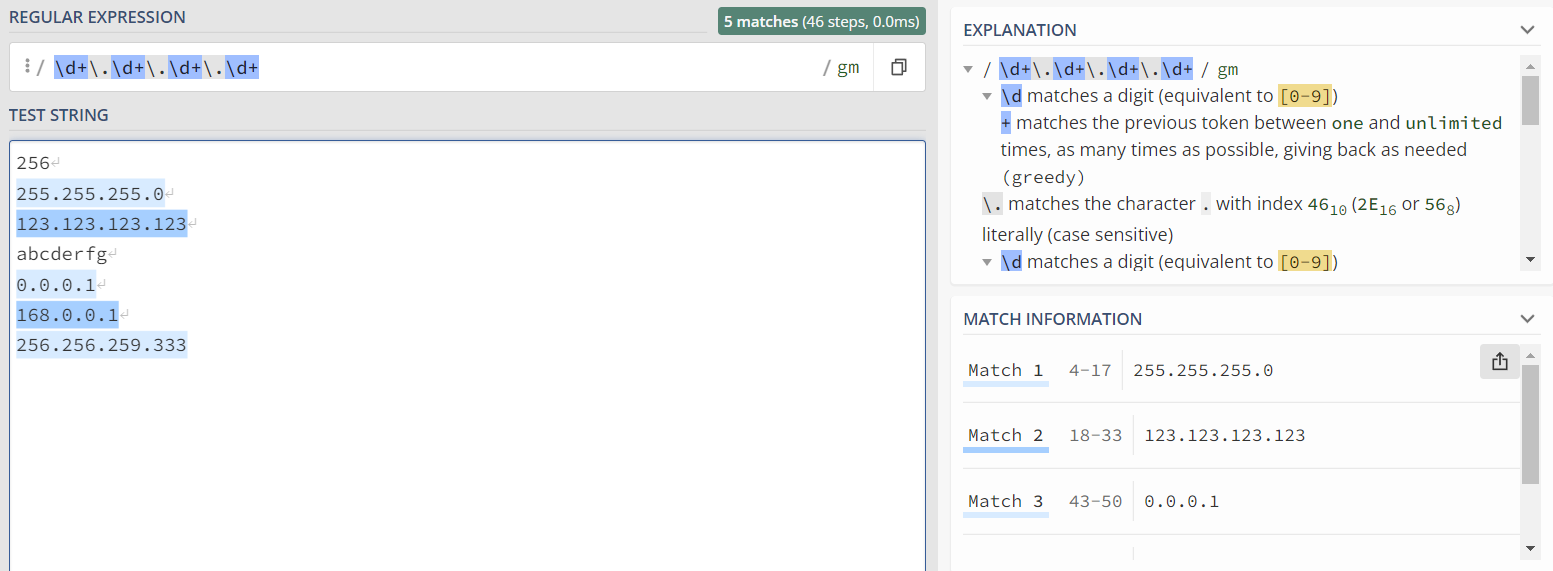
但此时匹配的结果不符合,由于ip地址需在0到255之间。观察ip地址的每一部分(共四部分)
三位数情况:
若前两位为25则第三位为0到5之间的数。
若第一位的数字为2,则第二位为0到5之间的数且第三位为0到9之间的数字即任意数字。
若第一位为0或者1,则第二位和第三位均可以为0到9间的数字即任意数字。
两位数和一位数的情况则均为任意数字即可,故在第一位为01的三位数情况的首位和末位加?代表是否存在
使用\.进行转义匹配.的情况并设置{3}匹配三次
最后在进行一次无.的匹配
在首位加\b确定边界即匹配完成