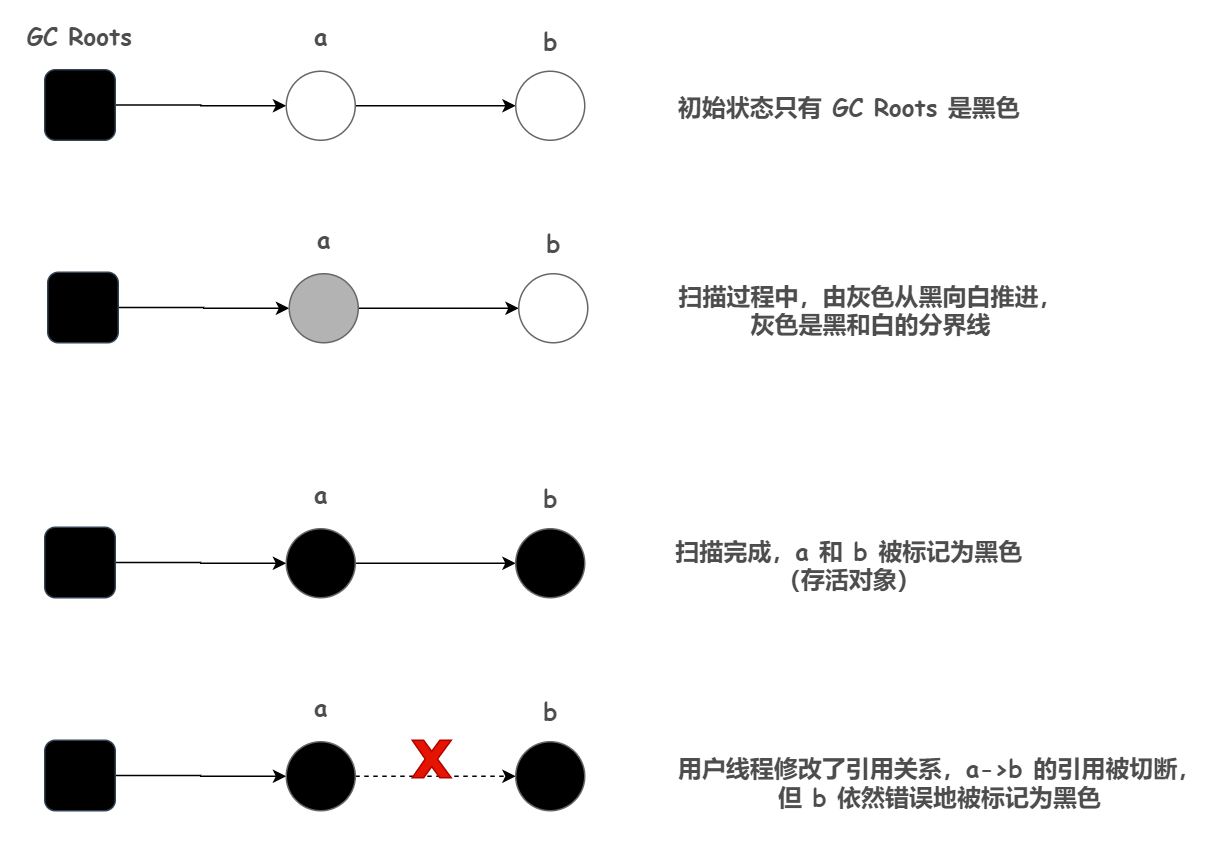
注意:本文章的大部分代码案例出自于《Python3 网络爬虫开发实战(第2版)》。
一、GET请求
import requests
res = requests.get('https://www.python.org')
print(type(res)) #
print(res.status_code) # 200
print(type(res.text)) #
print(res.text[:150])
print(res.encoding) # utf-8
print(res.headers['content-type']) # application/json; charset=utf8
print(res.cookies) #
- 扩展:其它请求类型
r = requests.get('http://www.httpbin.org/get')
r = requests.post('http://www.httpbin.org/post')
r = requests.put('http://httpbin.org/put', data = {'key':'value'})
r = requests.delete('http://www.httpbin.org/delete')
r = requests.patch('http://www.httpbin.org/patch')
1、实例
import requests
r = requests.get('https://www.httpbin.org/get')
print(r.text)
2、params传递参数
import requests
data = {
'name':'germey',
'age':25
}
r = requests.get('https://www.httpbin.org/get',params=data)
print(r.text)
3、JSON 响应内容
import requests
r = requests.get('https://www.httpbin.org/get')
print(type(r.text)) #
print(r.json())
print(type(r.json())) #
返回结果不是JSON格式,会出现解析错误:
import requests
res = requests.get('https://www.baidu.com')
"""
注意,返回结果不是json格式,就会出现解析异常,抛出 json.decoder.JSONDecodeError 异常
"""
print(res.json()) # 报错
4、原始响应内容
import requests
r = requests.get('https://api.github.com/events', stream=True)
print(r.raw.read())
扩展:以下面的模式将文本流保存到文件(下载图片):
r = requests.get('https://docs.python-requests.org/zh_CN/latest/_static/requests-sidebar.png')
with open('requests-sidebar.png',mode='wb') as f:
for chunk in r.iter_content(chunk_size=20):
f.write(chunk)
5、二进制响应内容
import requests
r = requests.get('https://www.sogou.com')
print(r.text) # 抓取文本数据
print(r.content) # 抓取二进制数据
扩展:以二进制的形式,下载图片:
import requests
r = requests.get('https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png')
with open('baidu_logo.png',mode='wb') as f:
f.write(r.content)
- 从请求返回的二进制数据创建图像
import requests
from PIL import Image
from io import BytesIO
r = requests.get('https://pic.ntimg.cn/file/20220402/19727910_161258533101_2.jpg')
img = Image.open(BytesIO(r.content))
# 打开图片看一下
img.show()
# 保存图片到本地磁盘
img.save('BythesIO_IMG.png')
6、添加请求头
import requests
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36'
}
r = requests.get('https://www.so.com',headers=headers)
print(r.text)
注意:定制 header 的优先级低于某些特定的信息源,例如:
- 如果在 .netrc 中设置了用户认证信息,使用 headers= 设置的授权就不会生效。而如果设置了 auth= 参数,.netrc 的设置就无效了。
- 如果被重定向到别的主机,授权 header 就会被删除。
- 代理授权 header 会被 URL 中提供的代理身份覆盖掉。
- 在我们能判断内容长度的情况下,header 的 Content-Length 会被改写。
7、抓取网页
import requests
import re
r = requests.get('https://ssr1.scrape.center')
pattern = re.compile('(.*?)',re.S)
titles = re.findall(pattern,r.text)
print(titles)
二、POST请求
1、data 接收 字典 类型的数据
import requests
data = {'name':'germey','age':'25'}
r = requests.post('https://httpbin.org/post',data=data)
print(r.text)
2、data 接收 JSON 数据
import requests
import json
url = 'https://httpbin.org/post'
payload = {'some':'data'}
r = requests.post(url,data=json.dumps(payload))
print(r.text)
3、json 接收 JSON 数据
import requests
url = 'https://httpbin.org/post'
payload = {'some':'data'}
r = requests.post(url,json=payload)
print(r.text)
4、获取响应内容
a、状态码
import requests
r = requests.get('https://www.qq.com/')
# 响应状态码,可以通过状态码数字200知道爬虫爬取成功
print(type(r.status_code),r.status_code) # 200
- 扩展:r.status_code == requests.codes.ok
import requests
r = requests.get('https://www.baidu.com/')
# 判断状态码这个数字是否爬虫爬取成功的代码如下:
exit() if not r.status_code == requests.codes.ok else print('request successfully')
运行结果如下:
request successfully
b、响应头
import requests
r = requests.get('https://www.qq.com/')
# 文件头信息
print(type(r.headers),r.headers)
print(r.headers['content-type'])
print(r.headers.get('content-type'))
c、Cookie
import requests
r = requests.get('https://www.qq.com/')
# cookie
print(type(r.cookies),r.cookies)
d、URL
import requests
r = requests.get('https://www.qq.com/')
# URL
print(type(r.url),r.url)
e、请求历史
import requests
r = requests.get('https://www.qq.com/')
# 请求历史
print(type(r.history),r.history)
三、高级用法
1、文件上传
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post('https://www.httpbin.org/post', files=files)
if r.status_code == requests.codes.ok:
print(r.text)
2、获取Cookie
import requests
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key,value in r.cookies.items():
print(key + '=' + value)
3、Cookie设置
# Python版本:3.6
# -*- coding:utf-8 -*-
import requests
"""
从浏览器的开发者工具中复制cookie,将其设置到请求头headers里面
"""
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/98.0.4758.80 Safari/537.36',
'Cookie':'__yjs_duid=1_86f7e6bca32c93983e1d41bcd81ba1a61643807279657; '
'BAIDUID=0B4418964BD37E97784AE7BADE39438E:FG=1; BAIDUID_BFESS=0B4418964BD37E9747028796C4E53DBE:FG=1; '
'BIDUPSID=0B4418964BD37E97784AE7BADE39438E; PSTM=1643894126; BD_UPN=12314753; '
'COOKIE_SESSION=332_0_1_5_0_1_0_0_1_1_0_0_0_0_0_0_0_0_1643981338|5#0_0_1643981338|1; '
'baikeVisitId=20c3652e-6429-4306-9c4f-631ab804fa2c; BD_HOME=1; '
'H_PS_PSSID=35411_35106_34584_35490_*****_35322_26350_35752_35746; BA_HECTOR=81al04ag8k8h0ha04m1gvsv740r',
}
r = requests.get('https://www.baidu.com',headers=headers)
print(r.text)
# 查看cookie,与设置的cookie一样:"H_PS_PSSID=35411_35106_34584_35490_*****_35322_26350_35752_35746; "
print(r.cookies)
"""outPut:
4、通过Cookie参数来设置Cookie的信息
# Python版本:3.6
# -*- coding:utf-8 -*-
import requests
# 首先在浏览器上登录帐号后,提取cookies信息,用cookies模拟了登录状态,这样就能爬取登录之后才能看到的页面了
# cookie可能会过期,需要重新从浏览器提取cookie过来
cookies = '_octo=GH1.1.46492411.1643975102; tz=Asia%2FShanghai; _device_id=397217a23bfb6953f8994efb95142319; '
'has_recent_activity=1; tz=Asia%2FShanghai; '
'color_mode=%7B%22color_mode%2uto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C'
'%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A'
'%22dark%22%7D%7D; user_session=6ULX20UhnDk08MsEjP7ngv3_PW4GgIAbOmSAKi9jwrvgS; '
'__Host-user_session_same_site=6ULX20UhnDk08MsEjP7ngv3_PWlOb4GgIAbOmSAKi9jwrvgS; logged_in=yes; '
'dotcom_user=juerson; _gh_sess=zR%2FV9HmFlSokFIt1F%2B63Ltg6igWu1GOYumK'
'%2BAsflH38KNrDgzdpnKMYNcZ8Kg1lpjxvAkQp1kZQ5zKLsaJBwTo62x9MMg2mK6yvNOb0Z3fVWDUYQbCIdZvy7bzR74NoJ7KBaG7D6ckAU2mANSFZWEdkIw5oOyAY6trLHZEVz4HCZRrgUA4fSB8OTvmruruAq%2BMDwWDcqlQvk2Hbg9uPJHVQ9yXt0nPyvXpprc5gjdRNlyurM7LBL6UHrw71%2B4vLy1SmjeI2mbji9xf97p0mj2vF0AXYNL5N9b8i8InTF%2BaUAZVqkawg4MKqfuj0GMsFjrcVEnlkRpNIkD8Y6QDfRABcClI2IdjoGtVY9YQIY8EM65nc7dPmlTR7yPowAQ1mjddHk0eZ%2BlNZXXz6xU6NsWAoUwFg5pWngLLXdJhpPDbNk1%2B4EYfOAgOUbIBh3nuJDrOfSbkAficQKoN7WczLFe%2BLK6QSdZUJpvXUfNm25%2FVBHr32POUC8nH3cGLVZnVYXflAwChW6JemDvMvMNbZmnTCx4z%2FnRSOU2c10ogSwsabfxq7JnmfGYMGrCn7%2FRd5YGkaBN44Q0nc%2B1vJDKTM%2FZXfNw%3D%3D--n%2F%2B2Aj9tuz9j--Ng18Cfe2ofjEQ%2B55GQMozA%3D%3D '
# 构造RequestsCookieJar对象
jar = requests.cookies.RequestsCookieJar()
# 文件头
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/98.0.4758.80 Safari/537.36'
}
# 对cookies进行处理以及赋值:将复制的cookies分割
for cookie in cookies.split(';'):
# 再次分割成key、value
key,value = cookie.split('=',1)
# 使用set方法设置好每个键名和键值
jar.set(key,value)
# 将RequestsCookieJar对象通过cookies参数传递
r = requests.get('https://github.com/',cookies=jar,headers=headers)
# 获取登录后的页面
print(r.text)
5、获取设置好的seesion
import requests
"""方法一:不能获取cookie信息"""
requests.get('https://www.httpbin.org/cookies/set/number/123456789')
r = requests.get('https://www.httpbin.org/cookies')
print(r.text)# { "cookies": {}}
"""
方法二:使用session获取当前cookie信息
"""
s = requests.session()
s.get('https://www.httpbin.org/cookies/set/number/123456789')
r = s.get('https://www.httpbin.org/cookies')
print(r.text) # {"cookies": { "number": "123456789" }}
6、使用 cookies 参数,发送cookies到服务器
import requests url = 'http://httpbin.org/cookies' cookies = dict(cookies_are='working') r = requests.get(url,cookies=cookies) print(r.text)
7、SSL证书验证
import requests
"""SSL证书验证错误:"""
response = requests.get('https://ssr2.scrape.center')
print(response.status_code) # 抛出SSLError错误,原因我们请求的URL的证书是无效
设置verify参数,默认值为verify=“True”(即自动验证)
import requests
response = requests.get('https://ssr2.scrape.center/',verify=False)
print(response.status_code) # 200
8、设置忽略警告(屏蔽警告)
- disable_warnings方法:
# Python版本:3.6
# -*- coding:utf-8 -*-
import requests
from requests.packages import urllib3
# 忽略警告下面两行的警告:
# D:PythonPython36libsite-packagesurllib3connectionpool.py:1050: InsecureRequestWarning: Unverified HTTPS request is being made to host 'ssr2.scrape.center'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
# InsecureRequestWarning
# 忽略警告
urllib3.disable_warnings()
response = requests.get('https://ssr2.scrape.center/',verify=False)
print(response.status_code) # 200
- captureWarnings方法
# Python版本:3.6
# -*- coding:utf-8 -*-
import logging
import requests
# 通过捕获警告到日志的方式忽略警告:
logging.captureWarnings(True)
response = requests.get('https://ssr2.scrape.center/',verify=False)
print(response.status_code) # 200
- 指定本地证书
import requests
# 需要有crt和key文件,并且指定它们的路径
response = requests.get('https://ssr2.scrape.center/',cret=('/path/server.crt','/path/server.key'))
print(response.status_code)
9、超时设置
-
永久等待
timeout参数不设置,或者设置为None,表示一直等待网站响应完毕
import requests
response = requests.get('https://httpbin.org/get',timeout=None)
print(response.status_code) # 200
- 设置timeout的总和
import requests
"""
本机网络状况不好或服务器网络响应太慢甚至无响应,超出这个设置的数就会抛出异常
参数timeout用于超时,超过这个时间就会抛出异常。
"""
response = requests.get('https://httpbin.org/get',timeout=1)
print(response.status_code) # 200
- 分别设置连接和读取的timeout值
import requests
'''
timeout参数:实际上,请求分为两个阶段——连接和读取;
timeout=1,意味如果1秒内没有响应,就会抛出异常,其中1是连接和读取的总和;
如果要分别指定用作连接和读取的timeout,则可以传入一个元组,如timeout=(1,5),1代表连接时间,5代表读取时间
'''
response = requests.get('https://httpbin.org/get',timeout=(5,30)) # 分别设置连接和读取的时间并存放到元组中
print(response.status_code) # 200
10、身份认证
- 使用requests库自带的身份证功能,通过auth参数设置
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('https://ssr3.scrape.center/',auth=HTTPBasicAuth('admin','admin'))
print(r.status_code) # 200
- 简写auth参数,直接传一个元组(简单的写法)
import requests
# 简写auth参数
res = requests.get('https://ssr3.scrape.center/',auth=('admin','admin'))
print(res.status_code) # 200
11、代理设置
注意:下面案例设置的代理ip,可能是过期、无效了,需要搜索寻找有效的代理并替换试验一下(可以尝试在这个网站寻找:https://www.proxy-list.download/)
- http协议代理
import requests
proxies = {
'http':'http://27.203.215.138:8060',
# 'http':'http://120.196.112.6:3128',
# 'http':'http://47.242.242.32:80',
# 'https':'http://120.196.112.6:3128',
}
r = requests.get('https://httpbin.org/get',proxies=proxies)
print(r.status_code) # 200
- 类似 http://user:password@host:port
import requests
proxies = {
# 'http':'http://user:password@61.216.185.88:60808/',
# 'http':'http://user:password@128.199.108.29:3128/',
'http':'http://user:password@165.154.23.222:80/',
}
r = requests.get('https://www.httpbin.org/get',proxies=proxies)
print(r.status_code) # 200
- SOCKS 协议代理(socks4、socks5)
import requests
proxies = {
'http':'socks4://user:password@139.159.48.155:39593',
# 'http':'socks5://user:password@139.162.108.196:12347',
# 'http':'socks4://user:password@35.220.160.28:10808',
# 'http':'socks5://user:password@72.206.181.123:4145',
# 'http':'socks5://user:password@103.9.159.235:59350',
# 'http':'socks5://user:password@112.105.12.63:1111',
# 'http':'socks4://user:password@192.111.138.29:4145',
# 'http':'socks5://user:password@72.223.168.86:57481',
}
r = requests.get('https://www.httpbin.org/get',proxies=proxies)
print(r.status_code) # 200
- prepared_request对象创建网络请求
直接使用requests库的get和post方法发送请求,也可以使用Prepared Request。实际上,requests在发送请求的时候,是在内部构造了一个Request对象,并给这个对象赋予了各种参数,包括url、headers、data等,然后直接把这个Request对象发送出去,请求成功后会再得到一个Requese对象,解析这个对象即可。
from requests import Request,Session
URL = "https://www.httpbin.org/post"
data = {'name':'germey'}
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/98.0.4758.80 Safari/537.36'
}
s = Session()
req = Request('POST',URL,data=data,headers=headers)
# 调用Session类的prepare_request方法再其转换为一个Prepared Request对象
prepped = s.prepare_request(req)
# 调用send方法发送
r = s.send(prepped)
print(r.text)
12、禁用重定向
⑴、Github 将所有的 HTTP 请求重定向到 HTTPS
import requests
r = requests.get('http://github.com')
print(r.url) # https://github.com/
print(r.status_code) # 200
print(r.history) # []
⑵、禁用重定向:allow_redirects 参数
import requests
r = requests.get('http://github.com',allow_redirects=False)
print(r.url) # http://github.com/
print(r.status_code) # 301
print(r.history) # []
⑶、启用重定向
r = requests.head('http://github.com',allow_redirects=True)
print(r.url) # https://github.com/
print(r.status_code) # 200
print(r.history) # []





![[Lua][Love Engine] 有效碰撞处理の类别与位掩码 | fixture:setFilterData](https://xiaonenglife.oss-cn-hangzhou.aliyuncs.com/static/pic/2023/08/20230821192959_love_RDKN36y4Zd.gif)