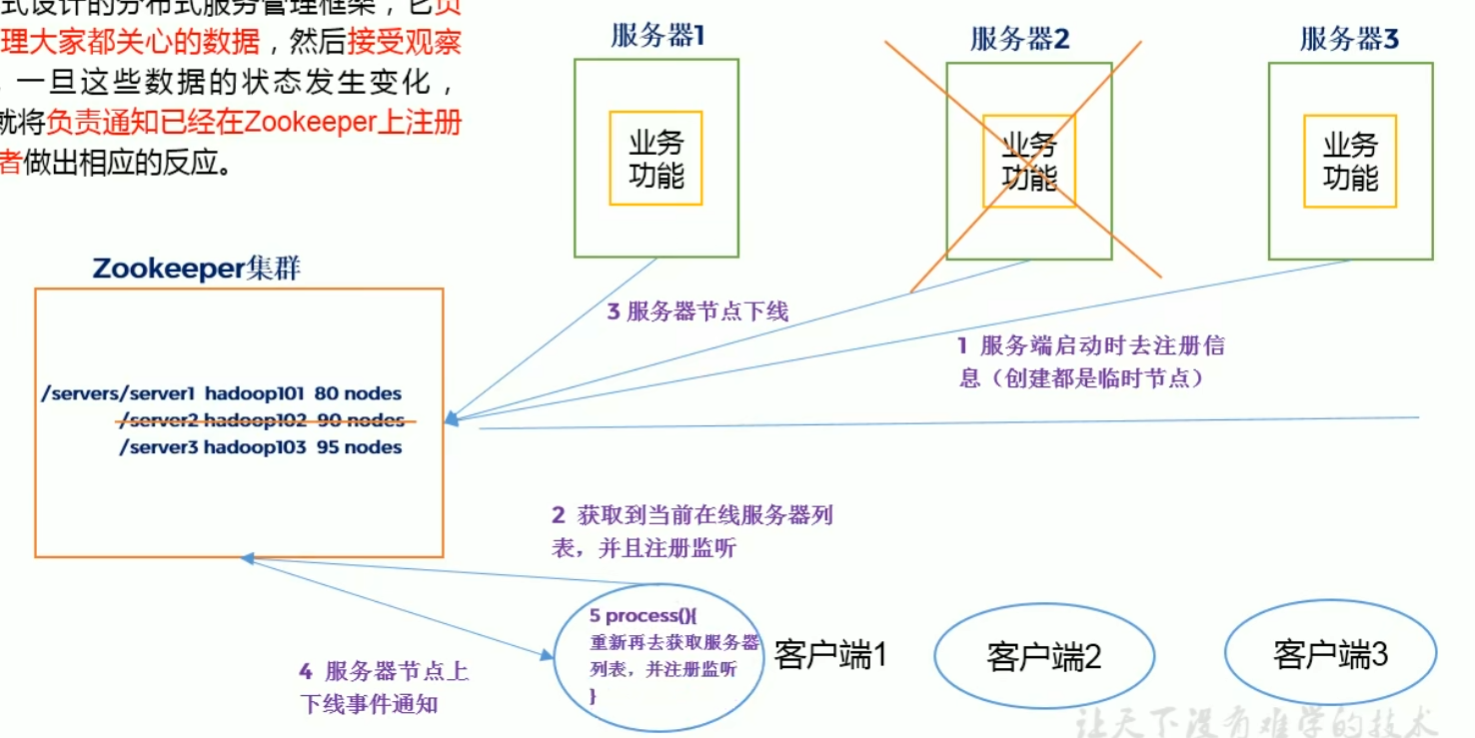
方法一:使用punctuation。
punctuation其中定义的是所以英文的标点符号。
add_punc相当于是自定义的,
如果只要去掉英文,那么if判断的地方,只保留add_punc即可,如果英文的标点符号也想去掉,就使用punctuation
比如,要去掉数字:add_punc=‘0123456789’ 即可。字母也同理。
代码:
from string import punctuation
str = "《三国演义》中的“水镜先生”是司马徽56585622"
add_punc='0123456789' # 自定义--数字
all_punc = punctuation + add_punc
temp = []
for c in str:
if c not in all_punc :
temp.append(c)
newText = ''.join(temp)
print(newText)
#输出结果:《三国演义》中的“水镜先生”是司马徽同理 这种方式可以去掉任何特定的字符。请参考另一篇文章:去掉字符串中的标点符号
方法二:
使用re.sub 函数
import re
str="aksjnekljfklen"
temp = re.sub('[a-zA-Z]','1',str)输出结果就都是1。
注意的是,sub需要import re; 第二,他的参数使用的是单引号,第三,他的第一个参数,也 就是【a-z】那部分是正则表达式的写法。