一、爬取目标
小红书是众多客户的流量蓝海,可通过评论区数据高效引流获客。我用python开发的爬虫采集软件,可自动抓取小红书评论数据,并且含二级评论数据。
为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用!
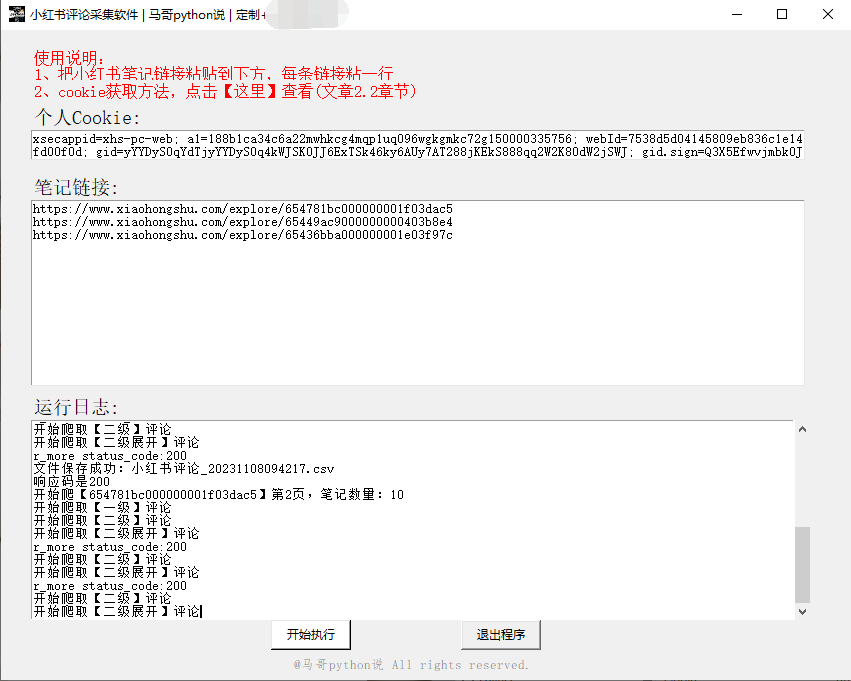
1.1 效果截图
软件界面截图:
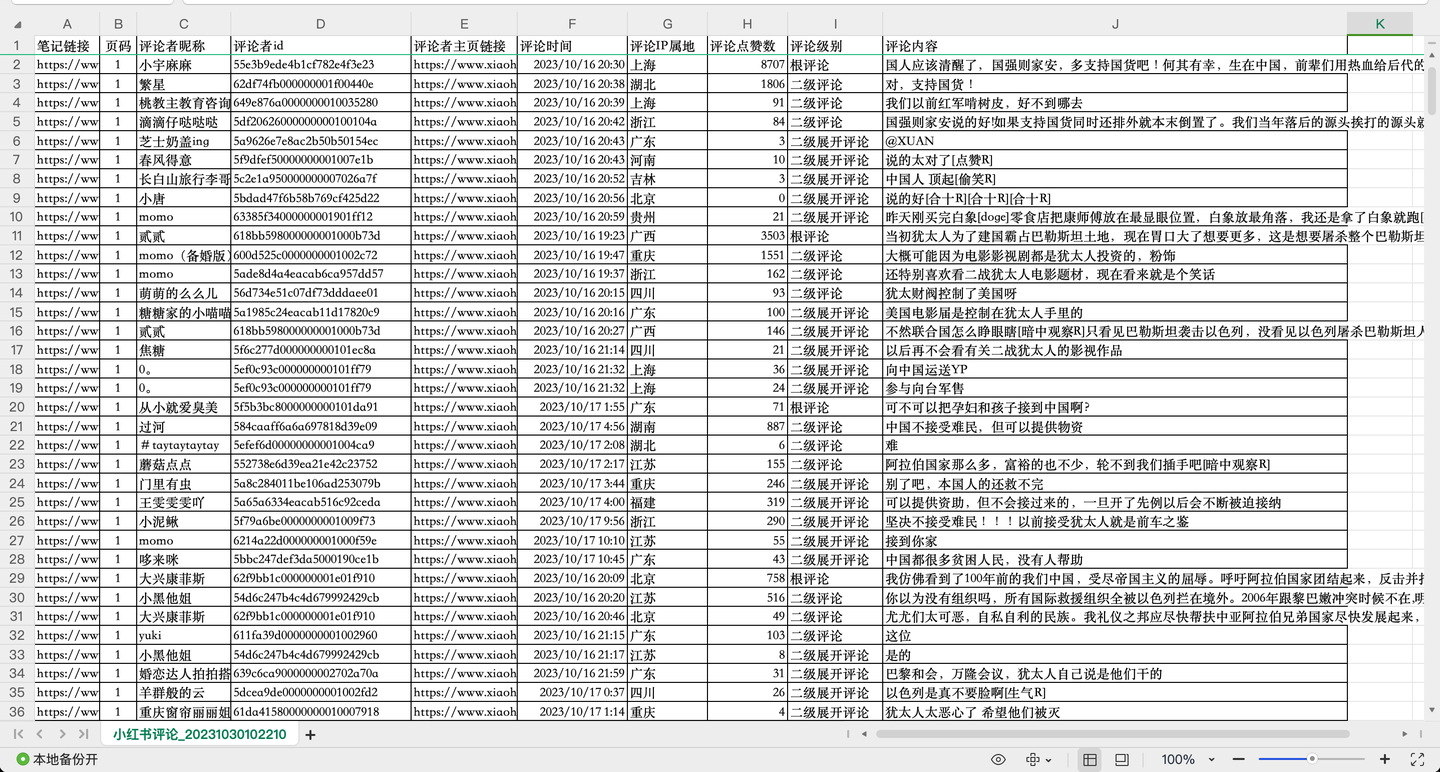
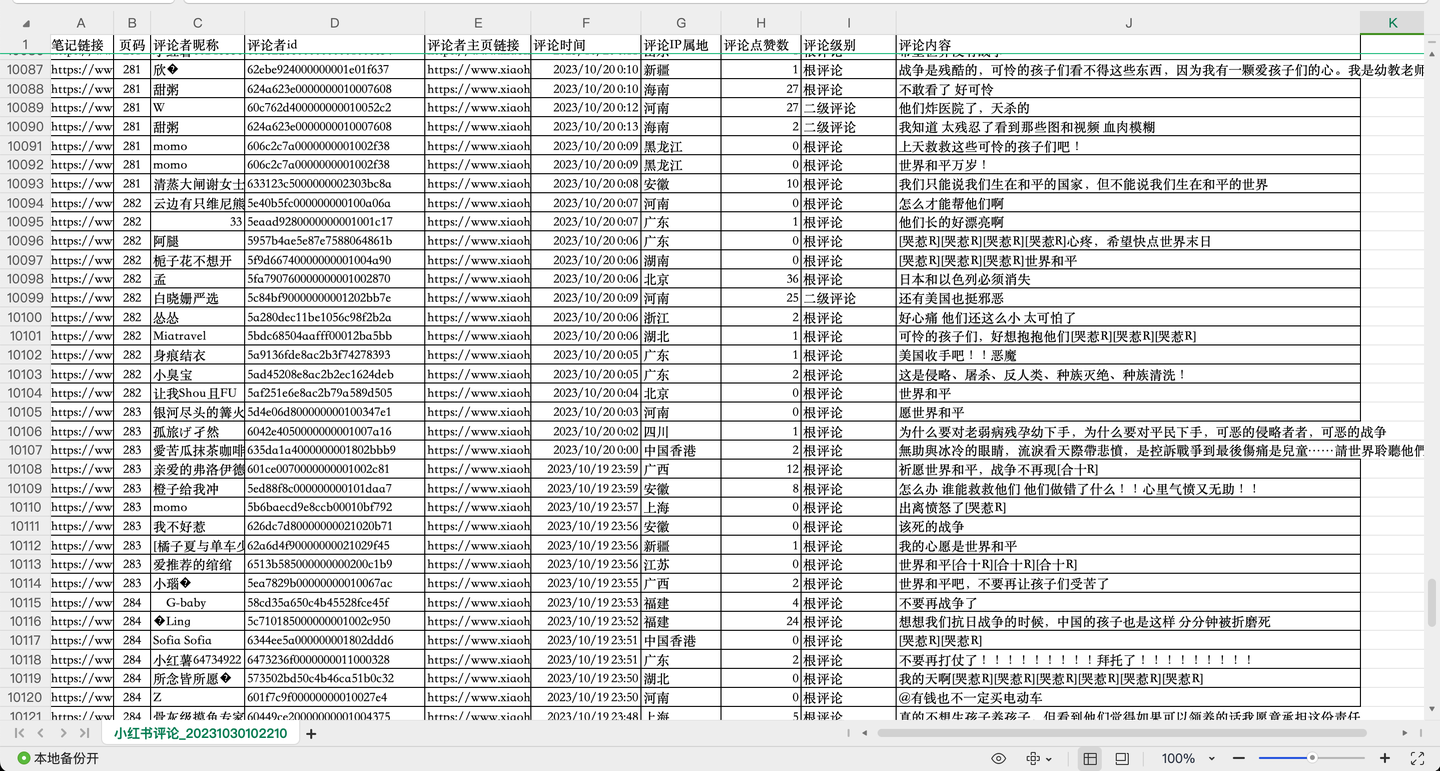
结果截图1:
结果截图2:
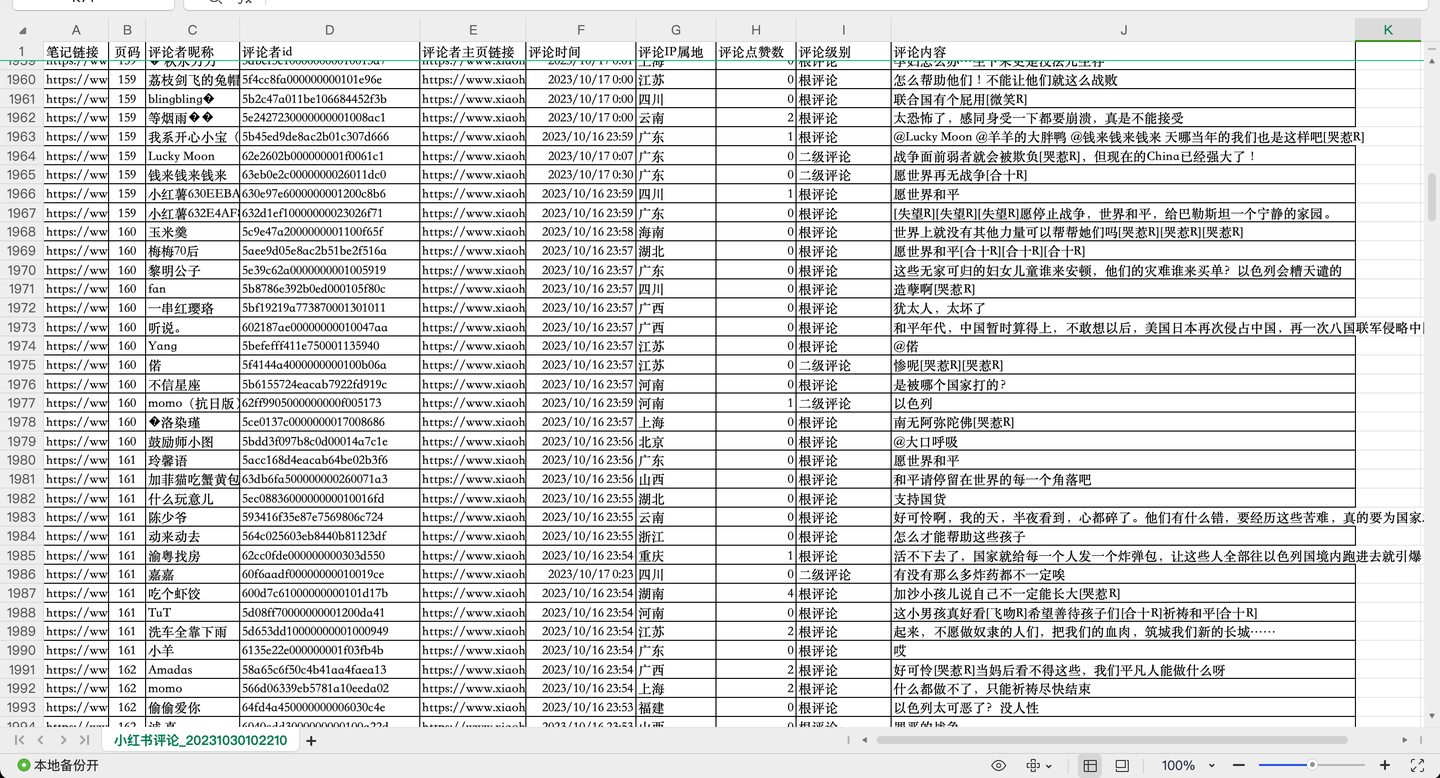
结果截图3:
1.2 演示视频
软件运行演示:【软件演示】小红书评论采集工具,可爬取上万条,含二级评论!
不懂编程代码的小白可直接看演示视频,忽略代码部分!
1.3 软件说明
几点重要说明:
二、代码讲解
2.1 爬虫采集模块
通过把已有代码部分封装成class类,供tkinter界面调用。
详细爬虫实现逻辑,请见:
【爬虫实战】用Python采集任意小红书笔记下的评论,爬了10000多条,含二级评论!
2.2 软件界面模块
软件界面采用tkinter开发。
主窗口部分:
# 创建日志目录
work_path = os.getcwd()
if not os.path.exists(work_path + "/logs"):
os.makedirs(work_path + "/logs")
# 创建主窗口
root = tk.Tk()
root.title('小红书评论采集软件 | 马哥python说')
# 设置窗口大小
root.minsize(width=850, height=650)
填写cookie控件:
# 【填入Cookie】
tk.Label(root, justify='left', font=('微软', 14), text='个人Cookie:').place(x=30, y=75)
entry_ck = tk.Text(root, bg='#ffffff', width=110, height=2, )
entry_ck.place(x=30, y=100, anchor='nw') # 摆放位置
填写笔记链接控件:
# 【笔记链接】
tk.Label(root, justify='left', font=('微软', 14), text='笔记链接:').place(x=30, y=145)
note_ids = tk.StringVar()
note_ids.set('')
entry_nt = tk.Text(root, bg='#ffffff', width=110, height=14, )
entry_nt.place(x=30, y=170, anchor='nw') # 摆放位置
底部软件版权说明:
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)
以上。
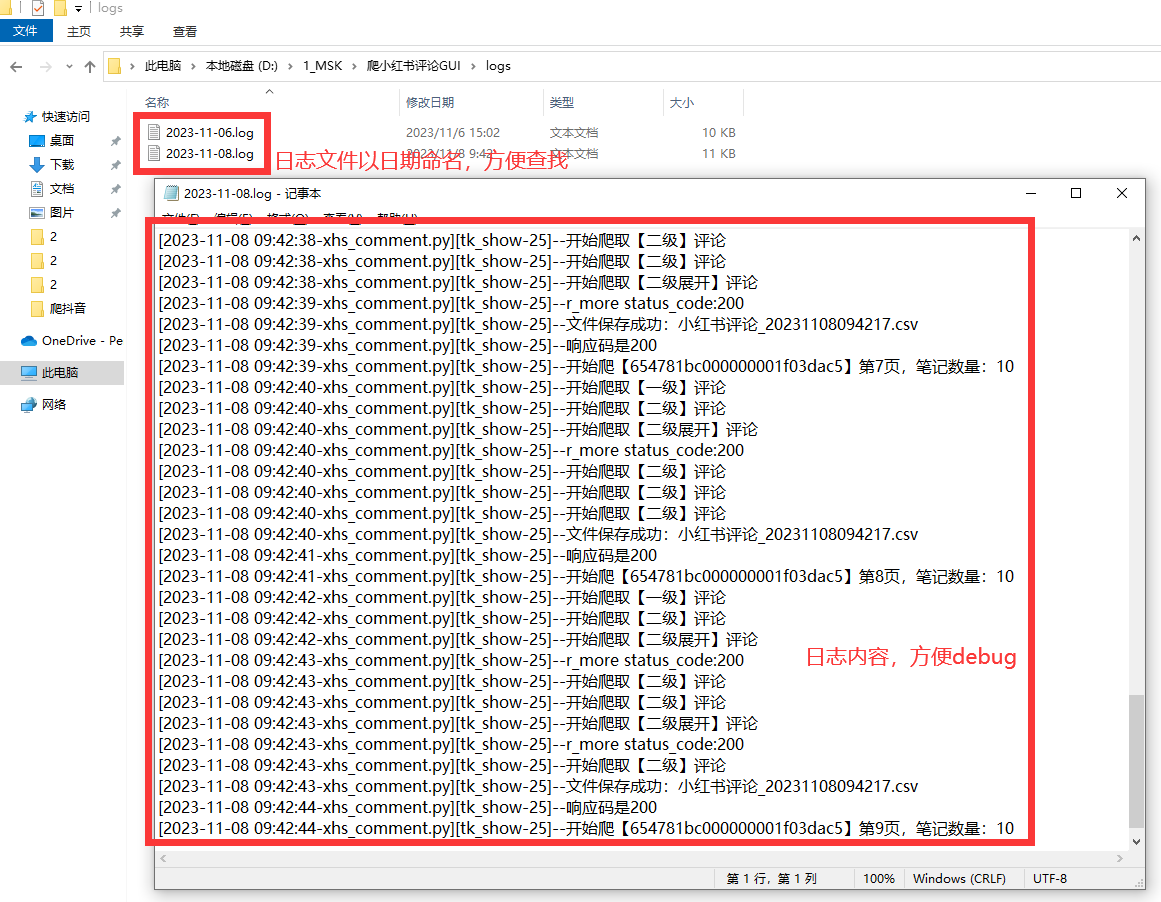
2.3 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
日志文件截图:
三、转载声明
转载已获原作者 @马哥python说 授权:
10年Python程序员,持续分享源码干货!