一、文件操作补充
(1)、文件二进制读操作
with open('a.txt', 'rb') as f:
print(f.read(3).decode('utf-8'))
"""
1. r模式
read()里面的数字代表的是一个字符
2. b模式
read()里面的数字代表的是一个字节
"""
(2)、文件的移动光标(了解)
with open('a.txt', 'rb') as f:
print(f.read(12).decode('utf-8'))
# f.seek(3,0) # 控制指针的移动
# f.seek(3,1) # 控制指针的移动
f.seek(-3,1) # 控制指针的移动
print(f.read().decode('utf-8'))
"""
f.seek总共有3种模式
1. offset参数
偏移量,移动的位置
如果是整数,从左往右读取
如果是负数,从右往左读取
2. whence参数
# 0: 默认的模式,该模式代表指针移动的字节数是以文件开头为参照的
# 1: 该模式代表指针移动的字节数是以当前所在的位置为参照的
# 2: 该模式代表指针移动的字节数是以文件末尾的位置为参照的
"""
(3)、文件的修改(了解)
方式一:
# 1. 读取b.txt文件数据
with open('b.txt', 'r', encoding='utf-8') as f:
data = f.read()
print(data) # kevin kevin kevin kevin say hello world
new_data = data.replace('kevin', 'jack')
# 2. 把新的数据再次写入文件
with open('b.txt', 'w', encoding='utf-8') as f1:
f1.write(new_data)
方式二:
# 修改文件内容的方式2:换地写
'''先在另外一个地方写入内容 然后将源文件删除 将新文件命名成源文件'''
import os
# 调用了一个名叫os的方法库,方便后续使用内置方法操作
with open('a.txt', 'r', encoding='utf8') as read_f, open('.a.txt.swap', 'w', encoding='utf-8') as write_f:
for line in read_f:
write_f.write(line.replace('tony', 'kevinSB'))
# 从文件中读取内容然后遍历进行对比替换,并把替换后的内容写入到另一个文件中,最后我们会在另一个文件中得到修改后的结果
os.remove('a.txt') # 删除原来的文件
os.rename('.a.txt.swap', 'a.txt') # 把另一个文件命名成原来文件的名字,就当作把他替换了
二、函数前戏
- 当我们在编写代码实现功能的时候,比如验证用户的登陆状态(确认用户的用户名和密码),一些情况下需要反复验证,这种时候就会反复套用一段一样的代码来检验。仔细想想这些地方其实进行了重复操作,因此我们引入了函数进行简化。这就相当于一个工人去干活,在最初的时候需要一次次的制造工具再去干活,后来他发现这挺蠢的。就做了工具之后保存好,每次干活的时候拿出来使用一下就可以快速完成工作了
代码重复性比较多
代码兼容性不好
自己写的这个函数没有返回值(就是函数执行之后,没有返回结果)
函数:类似于工具,提前准备好,方便后续使用
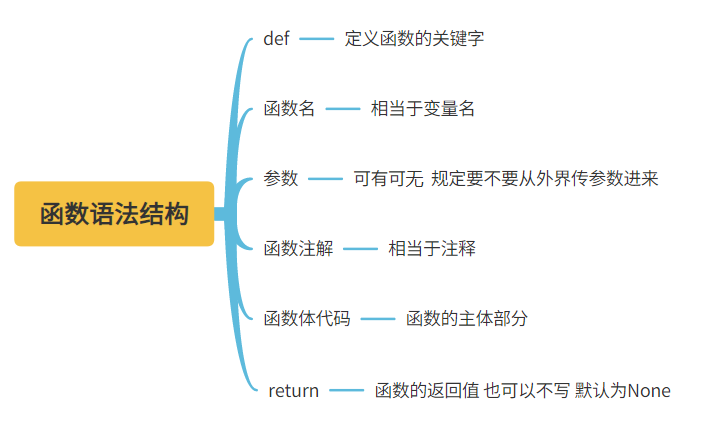
三、函数的语法结构
def 函数名(参数(可以有多个,后续会讲):
'''函数注释(解释函数功能)'''
函数体代码
return 返回值
# 1.def
定义函数的关键字
# 2.函数名
相当于变量名,命名遵循变量的命名规范,做到见名知意
# 3.参数
可有可无,主要是在使用函数的时候规定要不要外界传数据进来
# 4.函数注释
主要写一些函数功能的介绍,和一些参数的解释
# 5.函数体代码
是整个函数的核心,主要取决于程序员的编写
# 6.return(返回值)
使用函数之后可以返回给使用者的数据,可有可无
当我们给返回值的时候可以写多个,甚至是不同数据类型的多个数据值,他们会被封装到一个元组中一次性输出
当我们使用return的时候,意味着函数运行到这里就停止了,如果下方还有代码将不会运行
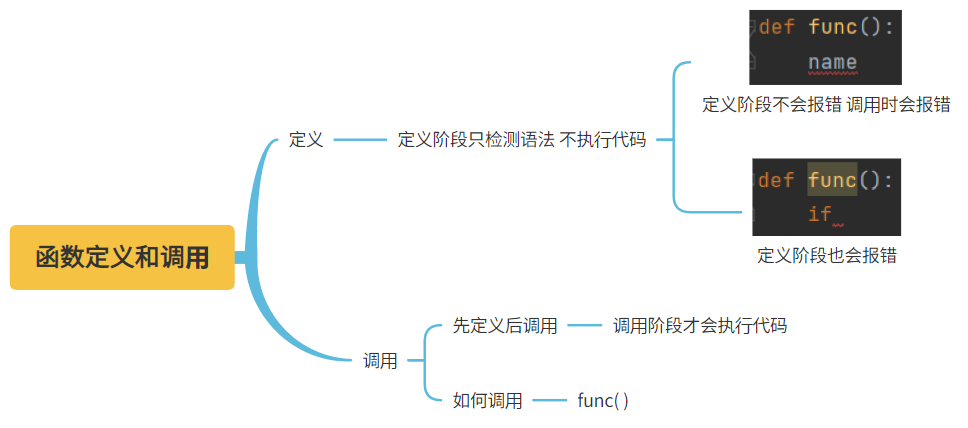
四、函数的定义与调用
# 函数一共是两个阶段:定义,调用
#####################必须掌握###########################################
1. 函数必须先定义,后调用
2. 函数在定义阶段,如果有参数,调用阶段也需要给对应的参数
3. 函数在定义阶段只检测语法是否正确,不执行具体的代码功能
4. 函数在调用阶段会执行具体的函数体代码
5. 如何调用函数?# 函数名加括号
#####################必须掌握###########################################
函数的底层原理
1. 申请一块内存空间,存储函数体代码
2. 把函数体代码绑定给函数名
3. 通过调用函数(函数名())来执行函数体代码
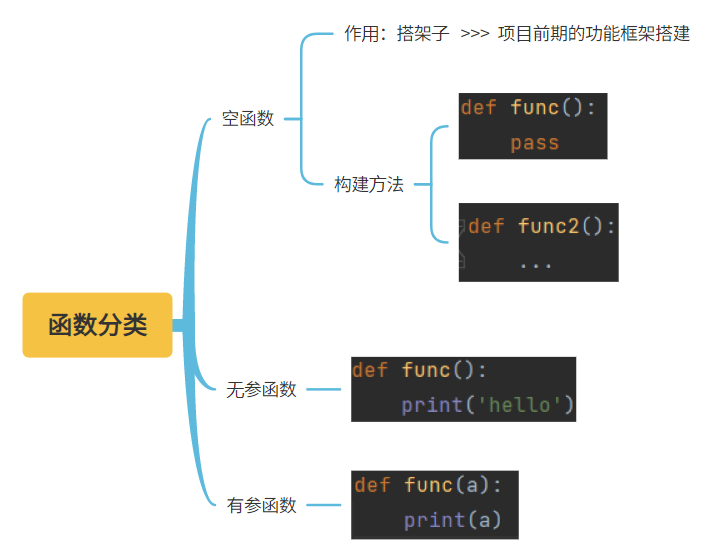
五、函数的分类
# 1. 内置函数
在python解释器中提前存在的,我们可以直接使用
eg:input, print,之前学习的数据类型的内置方法都是内置函数
# 2. 自定义函数
# 我们自己写的函数
2.1. 无参函数:定义函数的时候括号内没有参数
2.2. 有参函数:定义函数的时候括号内写参数,调用函数的时候括号传参数
2.3. 空函数:主要用于项目前期功能框架搭建
# 1.无参函数
# def my_len():
# print(123)
# my_len()
# 2. 有参函数
def my_len(a,b):
print('hello')
print(a,b)
# my_len(1,2)
my_len('a','b')
# 3. 空函数
def my_func():
# 1. 注册
pass
...
def login():
# 2.登录功能
pass
def chongqian():
# 3.这里是充值的逻辑
pass
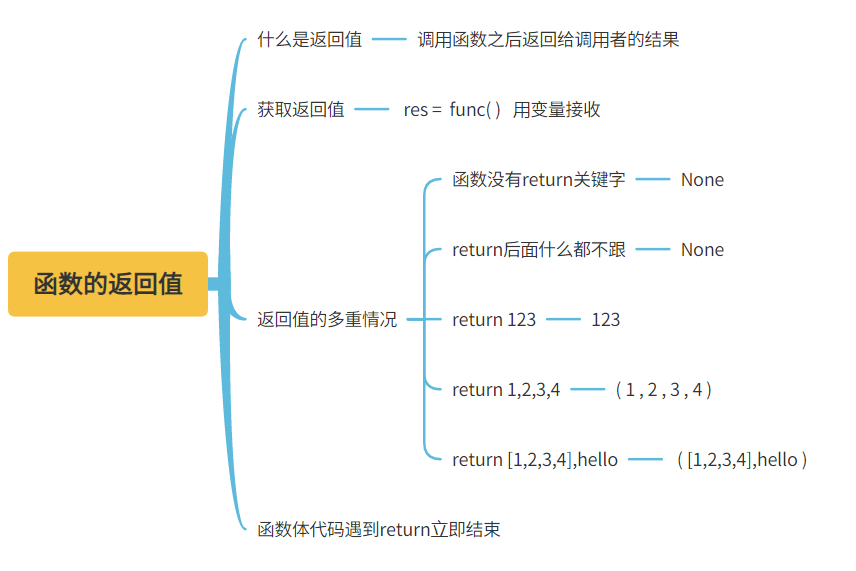
六、函数的返回值
1.什么是返回值
调用函数之后返回给调用者的结果
2.如何获取返回值
变量名 赋值符号 函数的调用
res = func() # 先执行func函数 然后将返回值赋值给变量res
3.函数返回值的多种情况
3.1.函数体代码中没有return关键字 默认返回None
3.2.函数体代码有return 如果后面没有写任何东西还是返回None
3.3.函数体代码有return 后面写什么就返回什么
3.4.函数体代码有return并且后面有多个数据值 则自动组织成元组返回
3.5.函数体代码遇到return会立刻结束