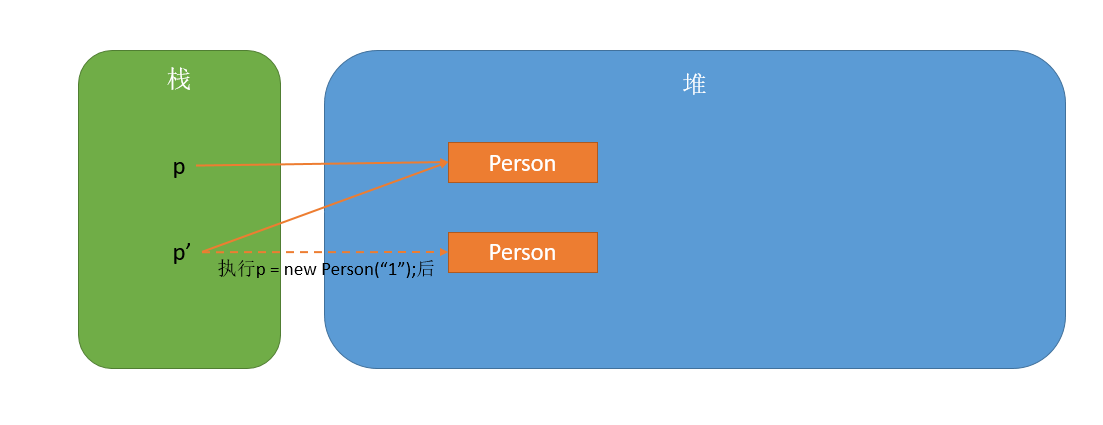
1:时间相关
时间的变化。
select sysdate +1 from dual ; //表示当前的时间加1天。
select sysdate + 1/24 from dual //加1个小时
select sysdate +1/24/60 from dual ; 加一分
select sysdate + 1/24/60/60 from dual 加一秒。
select add_months(sysdate,1) from dual ; 加一个月 。
-- 向下取整数
select ceil(sysdate - to_date('20190701','yyyymmdd')) from dual ;
--向上取整数
select round(sysdate - to_date('20190701','yyyymmdd')) from dual ;
2:字符相关函数
--截取当前的字符
select substr('helloworld',0,5) from dual
--去空格
select trim(' hel lo') from dual ;
--数字函数 四舍五入
select round(3.14159,3) from dual ;
select round(3.1415926) from dual ;
--转换函数
--数字转换为字符串
select trim(to_char()12345.15,'$9999999.99')) from dual ;
将日期转换为字符串
select to_char(sysdate,'yyyy-mm-dd') from dual ;
select to_char(sysdate,'yyyy-mm-dd hh:mi:ss') from dual ;
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual ;
3:instr函数的使用方法
在Oracle中,instr函数返回要截取的字符串在源字符串中的位置,只检索一次,就是说从字符的开始到字符的结尾就结束了
INSTR(源字符串,目标字符串,起始位置,匹配序号)。
INSTR方法的格式
INSTR(src,subStr,startIndex,count) 。
src:源字符串。
subStr:要查找的子串。
startIndex:从第几个字符开始,负数表示从右往左查找(此参数可选,默认为1).
count:要找到第几个匹配的序号(此参数可选,默认为1).
返回值:子串在字符串中的位置,第一个为1 ,不存在为0的。
4:PIVOT函数用法
pivot函数:行转列函数
语法:pivot(任一聚合的函数 for 需转列的值所在的列名 in(需转为行的列名)):
select * from t_pivot_test_1 :如下图。
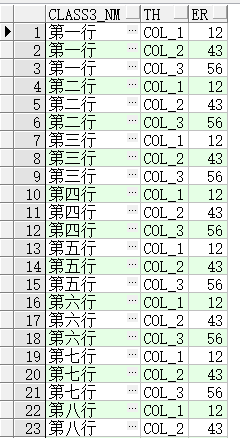
用pivot函数进行行转列。其中用聚合函数对数据列进行求值,将th列中的值’COL_1‘,’COL_2‘,‘COL_3’转化为列名,并为其加上别名。
sql语句:select * from T_PIVOT_TEST_1pivot (sum(er) for th in ('COL_1' as 第一列,'COL_2'as 第二列 ,'COL_3' as 第三列));
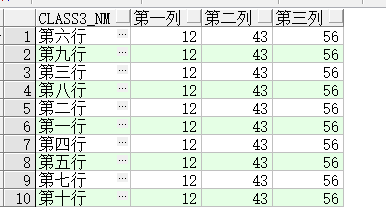
用pivot函数进行行转列。其中用聚合函数对数据列进行求值,将th列中的值’COL_1‘,’COL_2‘,‘COL_3’转化为列名,并为其加上别名。
sql语句:select * from T_PIVOT_TEST_1pivot (sum(er) for th in ('COL_1' as 第一列,'COL_2'as 第二列 ,'COL_3' as 第三列));
5:分析函数的应用
分析函数是oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于分组的某种统计值,并且每一组的每一行都可以返回一个统计值。
分析函数和聚合函数的不同。
普通的聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition分组,并且每组每行都可以返回一个统计值。
分析函数的形式
分析函数带有一个开窗函数over(),包含三个分析子句。分组(partition by),排序(order by),窗口(rows)他们的使用形式如下:over( partition by xxx order by yyy rows between zzz) .分析函数(以及与其配合的开窗函数over()是在整个sql查询结束后(sql语句中order by的执行比较特殊)
也就是说sql语句中的order by也会影响分析函数的执行结果
两者一致:如果sql语句中的order by 满足于分析函数配合的开窗函数over()分析时要求的排序,即Sql语句中的order by 子句里的内容和开窗函数over()中的order by子句里的内容一样。那么SQL语句中的排序先执行,分析函数在分析时就不必排序。
两者不一致:如果SQL语句中的order by 不满足与分析函数配合的开窗函数over()分析时要求的排序即SQL语句中的order by子句里的内容和开窗函数over()中的order by子句里的内容不一样;那么SQL语句中的排序将最后在分析函数结束后执行。开窗函数over() 包含三个分析子句,分组子句 (partition by),排序子句(order by),窗口子句(rows)窗口就是分析函数分析时要处理的数据范围,就拿sum()来说,它是sum窗口中的记录而不是整个分组中的记录,因此我们在想得到某个栏位的累计值时,我们需要把窗口指定到该分组中的第一行数据到
当前行,如果指定该窗口从该分组中的第一行到最后一行,那么该组中的每一个sum值都会一样。
6:Merge语法解析
merge语法是根据源表对目标表进行匹配,匹配成功时候更新,不成功时候插入
基本语法:
merge into 目标表 a
using 源表 b
on(a.条件字段1=b.条件字段2 and a.条件字段2=b.条件字段2....)
when matched then update set a.更新字段=b.字段
when not matched then insert into a (字段1,字段2,字字段3)values(值1,值2.。)
变种的写法:只更新
merge into 目标表 a
using 源表 b
on(a.条件字段1=b.条件字段1 and a.条件字段2=b.条件字段2....)
when matched then update set a.更新字段 = b.字段,set a.更新字段 = b.字段
变种写法 :只插入
merge into 目标表 a
using 源表 b
on(a.条件字段1=b.条件字段2 and a.条件字段2=b.条件字段2....)
when not matched then insert into a (字段1,字段2,字字段3)values(值1,值2.。)
注:条件字段不可更新。
删除操作:
merge into 目标表 a
using 源表 b
on(a.条件字段1 = b.条件字段1 and a.条件字段2=b.条件字段2.....)
when matched then update set a.更新字段=b.字段
delete where b.字段=xxx
merge into test_merge a
using test b
on(a.no=b.no)
when matched then update set a.no2=b.no2 where a.no<>1
delete where b.no = 14
删除动作针对的是目标表,并且必须在语句最后。
merge into 比单独使用update + insert 的方式效率要更高,尤其是on条件下有唯一索引的时候,效率更高。
7:for update的理解
1:for update 和 for update nowait的区别:
通常情况下,select 语句是不会对数据进行加锁的,不会妨碍影响其他的DML和DDL操作。借助 . forupdate子句,我们可以在应用程序的层面手工实现数据加锁保护操作,当只允许一个 Session进行update的时候,for uodate十分有用。
select * from test for update ;会对 table test 进行加锁,此时只允许对当前的session对已存在的数据更新,但是其他的session仍然可以进行 insert的操作。
加入 fro update之后,oracle就要求启动一个新的事物,尝试对数据进行加锁,如果当前已经被加锁,默认的行为必然是 block等待,使用 nowati子句的作用就是避免进行等待,当发现请求加锁资源被锁定未释放当然是时候,直接报错返回。如果不使用 nowait或wait子句,新的加锁请求会一直hang住,直到原来的 commit 或rollback .
首先一点,如果是select的话,Oracle是不会加任何锁的,也就是Oracle对查询到的数据不会有任何的限制虽然这时候有可能另外一个进程正在修改表中的数据,并且修改的结果可能影响到你目前的select语句的结果但是因为没有锁,所以select结果为当前时刻记录的状态。如果加入了 for update则Oracle一旦发现(符合查询条件)这批数据正在被修改,则不会发出该查询语句,直到数据修改commit,马上执行该查询语句。同样,如果查询语句发出后,有人需要修改这批数据中的一条或者几条,它也必须等到查询结束后,才能修改for update nowait 和for update都会对所查询的结果集进行加锁,所不同的是,如果另外一个线程正在修改结果集中的数据,for update nowait不会进行资源的等待,只要发现结果集中有些数据被加锁,立刻返回“ORA-00054”,内容是资源正忙。
2:for update nowait 和 for update的目的
锁定表中的所有的行,排斥其他针对这个表的操作。确保只有当前事物对指定的表进行写的操作。
3:对比mysql中的for update :
对于需要数值的操作比如金额,个数
记住一个原则,一锁,二判,三更新。
如果select 后面要update同一个表单,最好使用,select ...for update。