数据的特征抽取
现实世界中多数特征都不是连续变量,比如分类、文字、图像等,为了对非连续变量做特征表述,需要对这些特征做数学化表述,因此就用到了特征提取. sklearn.feature_extraction提供了特征提取的很多方法
分类特征变量提取
我们将城市和环境作为字典数据,来进行特征的提取。
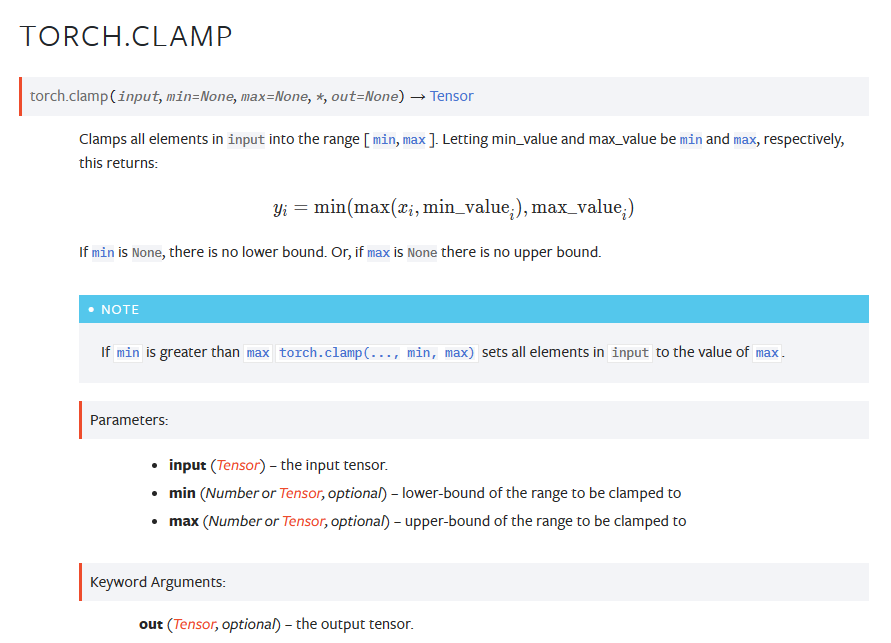
sklearn.feature_extraction.DictVectorizer(sparse = True)
将映射列表转换为Numpy数组或scipy.sparse矩阵
- sparse 是否转换为scipy.sparse矩阵表示,默认开启
方法
fit_transform(X,y)
应用并转化映射列表X,y为目标类型
inverse_transform(X[, dict_type])
将Numpy数组或scipy.sparse矩阵转换为映射列表
from sklearn.feature_extraction import DictVectorizer
onehot = DictVectorizer() # 如果结果不用toarray,请开启sparse=False
instances = [{'city': '北京','temperature':100},{'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]
X = onehot.fit_transform(instances).toarray()
print(onehot.inverse_transform(X))
文本特征提取(只限于英文)
文本的特征提取应用于很多方面,比如说文档分类、垃圾邮件分类和新闻分类。那么文本分类是通过词是否存在、以及词的概率(重要性)来表示。
(1)文档的中词的出现
数值为1表示词表中的这个词出现,为0表示未出现
sklearn.feature_extraction.text.CountVectorizer()
将文本文档的集合转换为计数矩阵(scipy.sparse matrices)
方法
fit_transform(raw_documents,y)
学习词汇词典并返回词汇文档矩阵
from sklearn.feature_extraction.text import CountVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = CountVectorizer()
print(vectorizer.fit_transform(content).toarray())
需要toarray()方法转变为numpy的数组形式
温馨提示:每个文档中的词,只是整个语料库中所有词,的很小的一部分,这样造成特征向量的稀疏性(很多值为0)为了解决存储和运算速度的问题,使用Python的scipy.sparse矩阵结构
(2)TF-IDF表示词的重要性
TfidfVectorizer会根据指定的公式将文档中的词转换为概率表示。(朴素贝叶斯介绍详细的用法)
class sklearn.feature_extraction.text.TfidfVectorizer()
方法
fit_transform(raw_documents,y)
学习词汇和idf,返回术语文档矩阵。
from sklearn.feature_extraction.text import TfidfVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = TfidfVectorizer(stop_words='english')
print(vectorizer.fit_transform(content).toarray())
print(vectorizer.vocabulary_)
数据的特征抽取
分类特征变量提取
In [ ]:
# 导入DictVectorizer类
from sklearn.feature_extraction import DictVectorizer
# 1.实例化
# 如果结果不用toarray,请开启sparse=False
dcitvec = DictVectorizer(sparse=True)
# 准备特征值化的字典,放在一个列表中
dict = [{'city': '北京','temperature':100},{'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]
# 抽取特征
sparse = dcitvec.fit_transform(dict)
print(sparse)
(0, 1) 1.0
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0
In [ ]:
# 1.实例化
# 如果结果不用toarray,请开启sparse=False
dcitvec = DictVectorizer(sparse=False)
# 准备特征值化的字典,放在一个列表中
dict = [{'city': '北京', 'temperature': 100}, {'city': '上海',
'temperature': 60}, {'city': '深圳', 'temperature': 30}]
# 2.抽取特征
feature = dcitvec.fit_transform(dict)
feature
Out[ ]:
array([[ 0., 1., 0., 100.],
[ 1., 0., 0., 60.],
[ 0., 0., 1., 30.]])
In [ ]:
# 获取列别名称
dcitvec.get_feature_names()
Out[ ]:
['city=上海', 'city=北京', 'city=深圳', 'temperature']
In [ ]:
# 将抽取的特征数组转换成列表
dcitvec.inverse_transform(feature)
Out[ ]:
[{'city=北京': 1.0, 'temperature': 100.0},
{'city=上海': 1.0, 'temperature': 60.0},
{'city=深圳': 1.0, 'temperature': 30.0}]
文本特征提取
计数方法
In [ ]:
# 导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# 1.实例化
countvec = CountVectorizer()
# 准备特征值化的文本,放在一个列表中
text = "life is short,i like python","life is too long,i dislike python"
# 2.抽取特征
feature = countvec.fit_transform(text).toarray()
feature
Out[ ]:
array([[0, 1, 1, 1, 0, 1, 1, 0],
[1, 1, 1, 0, 1, 1, 0, 1]], dtype=int64)
In [ ]:
# 获取特证值的名称
countvec.get_feature_names()
Out[ ]:
['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too']
In [ ]:
# 将抽取的特征数组转换成列表
countvec.inverse_transform(feature)
Out[ ]:
[array(['is', 'life', 'like', 'python', 'short'], dtype='<U7'),
array(['dislike', 'is', 'life', 'long', 'python', 'too'], dtype='<U7')]
权重方法
In [ ]:
# 导入
from sklearn.feature_extraction.text import TfidfVectorizer
# 1. 实例化
tfid = TfidfVectorizer()
# 2. 抽取特征值
feature = tfid.fit_transform(text).toarray()
feature
Out[ ]:
array([[0. , 0.37930349, 0.37930349, 0.53309782, 0. ,
0.37930349, 0.53309782, 0. ],
[0.47042643, 0.33471228, 0.33471228, 0. , 0.47042643,
0.33471228, 0. , 0.47042643]])
In [ ]:
# 获取特证值的名称
tfid.get_feature_names()
Out[ ]:
['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too']
In [ ]:
#将抽取的特征数组转换成列表
tfid.inverse_transform(feature)
Out[ ]:
[array(['is', 'life', 'like', 'python', 'short'], dtype='<U7'),
array(['dislike', 'is', 'life', 'long', 'python', 'too'], dtype='<U7')]