迁移学习(NRC)《Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation》
论文信息
论文标题:Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation
论文作者:Shiqi YangYaxing WangJoost van de WeijerLuis HerranzShangling Jui
论文来源:Neural Information Processing Systems (2021)
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
域适应(DA)旨在减轻源域和目标域之间的域转移。 大多数 DA 方法需要访问源数据,但这通常是不可能的(例如,由于数据隐私或知识产权)。 在本文中,我们解决了具有挑战性的无源域自适应 (SFDA) 问题,其中源预训练模型在没有源数据的情况下适应目标域。 我们的方法基于观察到目标数据可能不再与源域分类器对齐,但仍形成清晰的集群。 我们通过定义目标数据的局部亲和力来捕获这种内在结构,并鼓励具有高局部亲和力的数据之间的标签一致性。 我们观察到更高的亲和力应该分配给互惠的邻居,并提出自正则化损失以减少嘈杂邻居的负面影响。 此外,为了聚合具有更多上下文的信息,我们考虑具有小亲和力值的扩展邻域。 在实验结果中,我们验证了目标特征的固有结构是域适应的重要信息来源。 我们证明,通过考虑局部邻居、互惠邻居和扩展邻域,可以有效地捕获这种局部结构。 最后,我们在几个 2D 图像和 3D 点云识别数据集上实现了最先进的性能。
2 背景及出发点
相关工作:
-
- 现有的 DA 方法在域适应训练期间依然需要源域数据,但实际上源域数据始终可以访问是不切实际的,例如当应用于具有隐私或财产限制的数据时;
问题:
-
- 不管开放集和封闭集的最近 DA 工作,它们都忽略了特征空间中目标数据的内在邻域结构,这对于解决 SFDA 非常有价值;
-
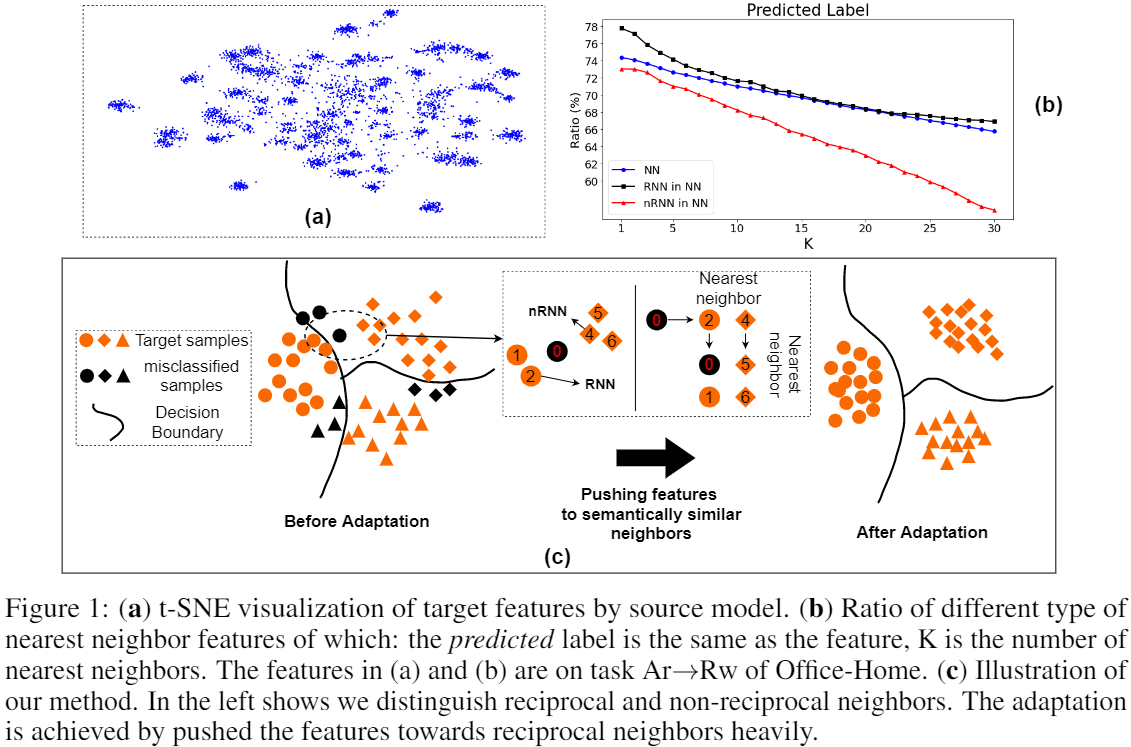
- 事实1:即使目标数据可能已经在特征空间中移动(协方差移动),但同一类的目标数据仍有望在嵌入空间中形成一个集群;Fig.1(a)
- 想法1:评估高维空间中点结构的一种行之有效的方法是考虑点的最近邻,这些点预计属于同一类;
- 事实2:Fig.1(b) 蓝色曲线表明,大约 75% 的最近邻居具有正确的标签;互惠邻居确实比非互惠最近邻居 (nRNN) 有更多机会预测真实标签;
- 想法2:使用 k 互近邻缓解最近邻部分预测错误的问题;
3 方法
使用源域数据训练好的源模型来生成目标域的簇结构,使用邻域信息来体现这种内在结构,并通过以下目标实现自适应:
$\mathcal{L}=-\frac{1}{n_{t}} \sum\limits _{x_{i} \in \mathcal{D}_{t}} \sum\limits_{x_{j} \in \operatorname{Neigh}\left(x_{i}\right)} \frac{D_{\text {sim }}\left(p_{i}, p_{j}\right)}{D_{d i s}\left(x_{i}, x_{j}\right)} \quad\quad\quad(1)$
其中:
-
- $\text{Neigh} \left(x_{i}\right)$ 为 $x_{i}$ 的最近邻集合;
- $D_{\text {sim }}$ 计算 $x_{i}$ 和其近邻之间的类分布相似性;
- $D_{d i s}$ 计算 $x_{i}$ 和其近邻之间的特征分布之间的距离;
如上述,最近邻并不一定都能带来有效监督信号,为减少这些邻居带来的潜在负面影响,本文使用连通性来权衡来自邻居的监督,即上述 $1/D_{d i s}(x_{i}, x_{j})$。
为实现 基于 batch 的最近邻训练,本文构建了两个 $\text{memory banks}$:$\mathcal{F}$ 存储所有目标特征,$\mathcal{S}$ 存储相应的预测分数:
$\mathcal{F}=\left[\boldsymbol{z}_{1}, \boldsymbol{z}_{2}, \ldots, \boldsymbol{z}_{n_{t}}\right] \text { and } \mathcal{S}=\left[p_{1}, p_{2}, \ldots, p_{n_{t}}\right]$
$\text{Note}$:简单地更新 $\text{memory bank}$ 中对应于当前 $\text{mini-batch}$ 的旧项;
对于每个样本 $x_{i}$,在 $\text{feature bank}$ 中找到它的 $k$ 个最近邻(余弦相似度),最大化它们 $\text{score}$ 的加权点积,即,使它们的输出相似或者说具有一致性。
$\mathcal{L}_{\mathcal{N}}=-\frac{1}{n_{t}} \sum\limits _{i} \sum\limits_{k \in \mathcal{N}_{K}^{i}} A_{i k} \mathcal{S}_{k}^{\top} p_{i}$
$A_{i, j}=\left\{\begin{array}{ll}1 & \text { if } j \in \mathcal{N}_{K}^{i} \wedge i \in \mathcal{N}_{M}^{j} \\r & \text { otherwise. }\end{array}\right.$
同样可以扩展到其高阶邻居:
$\mathcal{L}_{E}=-\frac{1}{n_{t}} \sum\limits_{i} \sum\limits _{k \in \mathcal{N}_{K}^{i}} \sum\limits_{m \in E_{M}^{k}} r \mathcal{S}_{m}^{\top} p_{i}$
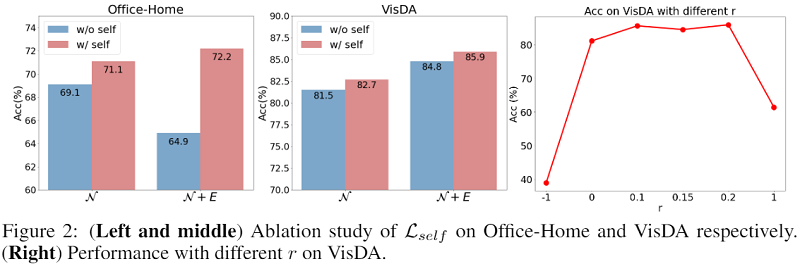
作者没有直接使用 $\text{minimize entropy}$,而是用了一种称为 $\text{self-regularization}$ 的方法,简单来说就是最大化每个样本输出 $\text{score}$ 自己与自己的点积。不难看出当 $\text{score}$ 为 $\text{one-hot}$ 向量时点积最大,所以效果上可能和 $\text{minimize entropy}$ 差不多。
$\mathcal{L}_{\text {self }}=-\frac{1}{n_{t}} \sum\limits _{i}^{n_{t}} \mathcal{S}_{i}^{\top} p_{i}$
为了避免模型将所有数据预测为某些特定类(并且不预测任何目标数据的其他类)的退化解决方案 [8, 39],鼓励预测是平衡的。 本文采用广泛用于聚类 [8、9、13] 以及多个领域适应工作 [21、39、42] 的预测多样性损失:
$\mathcal{L}_{d i v}=\sum\limits _{c=1}^{C} \operatorname{KL}\left(\bar{p}_{c} \| q_{c}\right), \text { with } \bar{p}_{c}=\frac{1}{n_{t}} \sum\limits_{i} p_{i}^{(c)}, \text { and } q_{\{c=1, . . C\}}=\frac{1}{C}$
训练目标
$\mathcal{L}=\mathcal{L}_{\text {div }}+\mathcal{L}_{\mathcal{N}}+\mathcal{L}_{E}+\mathcal{L}_{\text {self }}$
4 实验
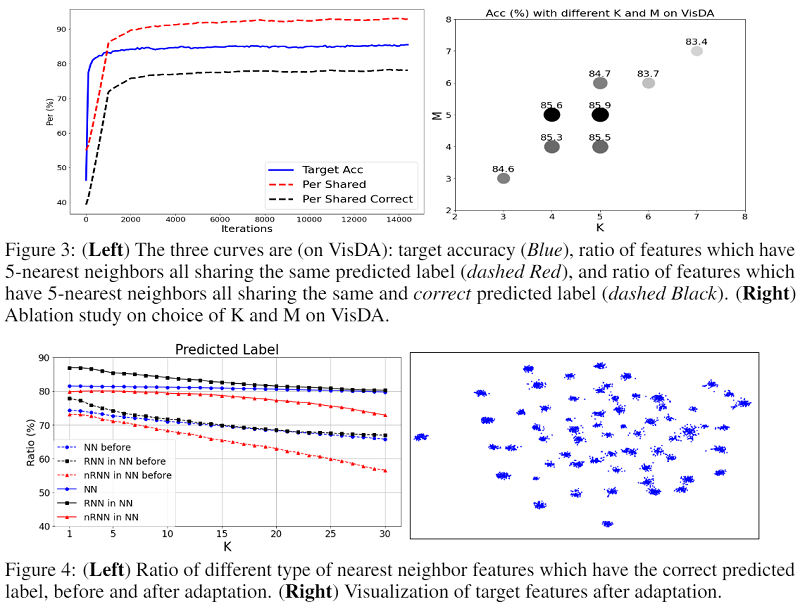
消融实验

A:删除亲和力 $A$ 意味着平等对待所有这些邻居;
$\mathcal{L}_{\hat{E}}$:意味着我们删除了方程式中扩展邻居的重复;












![原来你是这样的JAVA–[07]聊聊Integer和BigDecimal](https://img2024.cnblogs.com/blog/37001/202402/37001-20240224171021931-593439949.png)



![[Vue] CSS中的v-bind](https://fox-blog-image-1312870245.cos.ap-guangzhou.myqcloud.com/202402161730758.png)

