虚假新闻检测(GET)《Evidence-aware Fake News Detection with Graph NeuralNetworks》
论文信息
论文标题:Evidence-aware Fake News Detection with Graph Neural Networks
论文作者:Weizhi Xu, Junfei Wu, Qiang Liu, Shu Wu, Liang Wang
论文来源:2022 WWW
论文地址:download
论文代码:download
1 Introduction
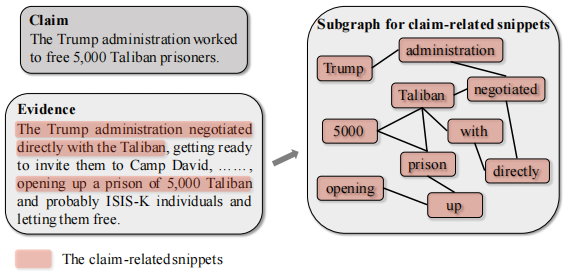
假新闻的流行和危害一直是互联网上的一个关键问题,进而刺激了假新闻自动检测的发展。在本文中,我们关注基于证据的假新闻检测,其中利用几个证据来探测新闻的真实性(即一个 Claim )。以往的方法大多首先采用顺序模型嵌入语义信息,然后基于不同的注意机制捕获 Claim-Evidence 交互。尽管它们很有效,但它们仍然有两个主要的弱点。首先,由于序列模型固有的缺陷,它们无法将分散距离较远的相关信息整合起来,以进行准确性检验。其次,他们忽略了 Evidence 中所包含的许多可能无用甚至有害的冗余信息。
本文将它们建模为图结构的数据,并通过邻域传播捕获分散的相关片段之间的长距离语义依赖关系。在获得上下文语义信息后,我们的模型通过进行图结构学习,减少了信息的冗余性。最后,将细粒度的语义表示输入到下游的 Claim-Evidence 交互模块中进行预测。
2 Task Formulation
Evidence-based fake news detection is a classification task, where the model is required to output the prediction of news veracity. Specifically, the inputs are a claim $c$ , several related evidences $\mathcal{E}=\left\{e_{1}, e_{2}, \ldots, e_{n}\right\}$ , and their corresponding speakers $\mathrm{s} \in \mathbb{R}^{1 \times b}$ or publishers $\mathbf{p} \in \mathbb{R}^{n \times b}$ , where $n$ is the number of evidences and $b$ is the dimension of speaker and publisher embeddings. The output is the predicted probability of veracity $\hat{y}=f(c, \mathcal{E}, \mathbf{s}, \mathbf{p}, \Theta)$ , where $f$ is the verification model and $\Theta$ is its trainable parameters.
3 Method
总体框架:
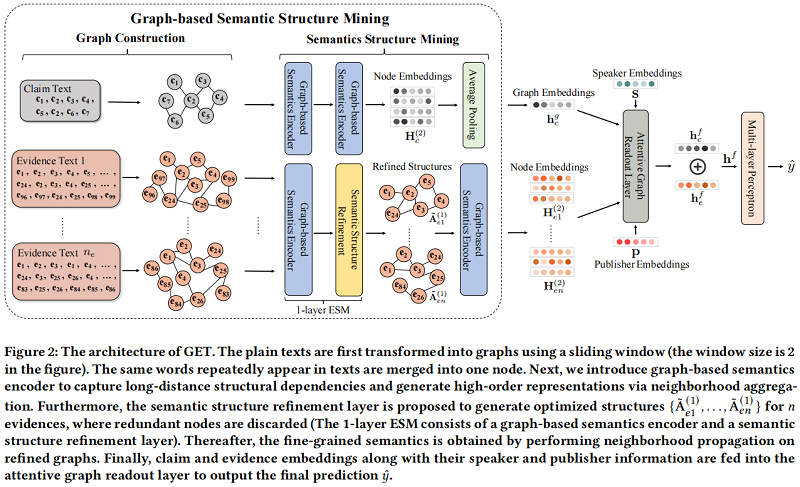
3.1 Graph Construction
对于一个句子中的某个中心词,在窗口内的单词用边相连。
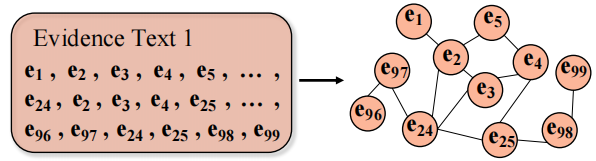
初始节点嵌入是 Glove 词嵌入,本文还尝试使用全连接或者基于相似度的方法构造,但是效果都不好,这可能是由于信息冗余的问题。对于 Claim、Evidence 都是使用上述构建方法。
Claim、Evidence 的节点嵌入矩阵和邻接矩阵:$\tilde{\mathbf{A}}_{c}^{(0)} \in \mathbb{R}^{N_{c} \times N_{c}}$、$\tilde{\mathbf{A}}_{e}^{(0)} \in \mathbb{R}^{N_{e} \times N_{e}}$、$\mathbf{H}_{c}^{(0)} \in \mathbb{R}^{N_{c} \times d}$、$\mathbf{H}_{e}^{(0)} \in \mathbb{R}^{N_{e} \times d}$。
3.2 Graph-based Semantics Encoder
为了挖掘长距离语义依赖关系,我们建议利用 GNN 作为语义编码器。特别是,由于我们期望自适应地保持节点自身特征和相邻节点信息之间的平衡,我们使用图门控神经网络(GGNN)在声明图和证据图上进行邻域传播,使节点能够捕获它们的上下文信息,这对于学习高级语义具有重要意义。形式上,可以写如下:
3.3 Semantic Structure Refinement
由于证据总是包含冗余信息,可能会误导模型关注不重要的特征,因此发现和过滤掉冗余信息可以获得精细的语义结构。为此,在我们的基于图的框架中,我们将冗余缓解视为一个图结构学习过程,其目的是学习优化的图拓扑以及更好的节点表示。以往的 GSL 方法通常通过三种方式来优化拓扑结构,即删除节点、删除边和调整边的权值。由于冗余信息主要涉及证据图中节点的词,我们尝试通过丢弃冗余节点来细化证据图的结构。
特别地,我们建议为每个节点计算一个冗余分数,在此基础上我们得到一个排名列表,具有 $\text{top-k}$ 冗余分数的节点将被丢弃。冗余不仅与每个节点中包含的自信息有关,而且是由图上的邻域所涉及的上下文信息引起的。例如,如果一个声明可以通过证据中的一个片段来验证,那么其余的段(包括片段的上下文)将是多余的。因此,我们使用 1 层 GGNN 来计算冗余分数,这考虑了自我信息以及上下文计算分数。在数学上,它可以表述为:
$\begin{array}{l}\mathbf{s}_{r}=\mathbf{G G N N}\left(\tilde{\mathbf{A}}, \hat{\mathbf{H}}_{\mathrm{e}} \mathbf{W}_{s}\right) \quad\quad(6) \\i d x=\operatorname{top} k_{-} \operatorname{index}\left(\mathbf{s}_{r}\right)\quad\quad(7) \\\tilde{\mathbf{A}}_{i d x,:}=\tilde{\mathbf{A}}_{:, i d x}=0 \quad\quad(8)\end{array}$
其中,$\mathbf{W}_{s} \in \mathbb{R}^{d \times 1}$ 是将节点表示投影到一维分数空间中的可训练权值。$\text{idx}$ 表示具有 $\text{top-????}$ 冗余分数的节点的指数,通过将其度掩盖为 $0$ 。请注意,在$\text{Eq.6}$ 中的 GGNN 由于目标不同,不与语义编码器共享参数。此外,我们只对证据进行语义结构的细化,因为 Claim 通常很短,因此语义结构很简单,没有必要进行细化。
最后,我们将 semantic structure refinement layer 堆叠在一个 semantics encoder 上,形成一个统一的模块,即 evidence semantics miner(简称ESM),其中捕获长距离语义依赖性,减少冗余信息。一般来说,我们可以堆叠 ESM 的 $T_R$ 层来细化语义结构 $T_R$ 次,最后再使用语义编码器在细化的语义图上执行邻域传播,获得细粒度的表示。
3.4 Attentive Graph Readout Layer
然后得到每个 evidence 的细粒度精细结构 $\tilde{\mathrm{A}}_{e}^{\left(T_{R}\right)}$,以及 claim 和 eviedence 的节点嵌入 $\mathbf{H}_{c}^{\left(T_{E}\right)}$, $\mathbf{H}_{e}^{\left(T_{R}+1\right)}$,其中 $T_{R}=1$,$T_{E}=2$。
然后进行 Claim-Evidence 之间的交互,通过计算细化后的 evidence 图中第 $j$ 个词 $\mathbf{H}_{e j}$ 和 claim 的表示 $\mathbf{h}_{c}^{g}$ 之间注意力得分,然后加权求和得到证据表示 $\mathbf{h}_{e}^{g}$:
$\begin{aligned}\mathbf{h}_{c}^{g} & =\frac{1}{l_{c}} \sum_{i=1}^{l_{c}} \mathbf{H}_{c i} \quad \quad (9)\\\mathbf{p}_{j} & =\tanh \left(\left[\mathbf{H}_{e j} ; \mathbf{h}_{c}^{g}\right] \mathbf{W}_{c}\right) \quad \quad (10)\\\alpha_{j} & =\frac{\exp \left(\mathbf{p}_{j} \mathbf{W}_{p}\right)}{\sum_{i=1}^{l_{e}} \exp \left(\mathbf{p}_{i} \mathbf{W}_{p}\right)} \quad \quad (11)\\\mathbf{h}_{e}^{g} & =\sum_{j=1}^{l_{e}} \alpha_{j} \mathbf{H}_{e j} \quad \quad (12)\end{aligned}$
其中,$[\cdot ; \cdot]$ 代表着 concat ,$\mathbf{W}_{c} \in \mathbb{R}^{2 d \times d}$、$\mathbf{W}_{p} \in \mathbb{R}^{d \times 1}$ 代表着可学习的参数,$l_{c}$、$l_{e}$ 分别代表着 claim、evidence 的长度。上述 $\text{Eq.10}$~$\text{Eq.12}$ 记作 $\operatorname{ATTN}\left(\mathbf{H}_{\mathbf{e}}, \mathbf{h}_{c}^{g}\right)$
正如 [37] 的经验证明,claim speaker 和 evidence publisher 信息对于验证是重要的,我们通过将 claim 和 evidence 表示与相应的信息向量连接,即 $\mathbf{h}_{c}^{f}=\left[\mathbf{h}_{c}^{g} ; \mathbf{s}\right]$ 和 $\mathbf{h}_{e}^{r}=\left[\mathbf{h}_{e}^{g} ; \mathbf{p}\right]$ 来扩展声明和证据声明;
在获得 claim 和 evidence 陈述后,我们进一步使用另一个与上述结构相同的关注网络,来捕获一个 claim 和几个 evidence 之间的文档级交互:
$\begin{aligned}\mathbf{H}_{e}^{r} & =\left[\mathbf{h}_{e 1}^{r} ; \mathbf{h}_{e 2}^{r} ; \ldots ; \mathbf{h}_{e n}^{r}\right] \quad\quad(13) \\\mathbf{h}_{e}^{f} & =\mathbf{A T T N}\left(\mathbf{H}_{e}^{r}, \mathbf{h}_{c}^{f}\right)\quad\quad(14)\end{aligned}$
其中,$\mathbf{H}_{e}^{r}$ 代表 $n$ 个 evidence 的拼接。
最后,我们通过连接将 claim 和 evidence 嵌入集成到一个统一的表示中,然后通过一个多层感知器输出准确性预测 $\hat{y}$。
$\begin{array}{l}\mathbf{h}^{f} =\left[\mathbf{h}_{c}^{f} ; \mathbf{h}_{e}^{f}\right] \quad\quad (15)\\\hat{y} =\operatorname{Softmax}\left(\mathbf{W}_{f} \mathbf{h}^{f}+\mathbf{b}_{f}\right)\quad\quad (16)\end{array}$
3.5 Training Objective
本质上是一个分类任务,利用标准的交叉熵损失作为目标函数:
$\mathcal{L}_{\Theta}(y, \hat{y})=-(y \log \hat{y}+(1-y) \log (1-\hat{y})) \quad\quad (17)$
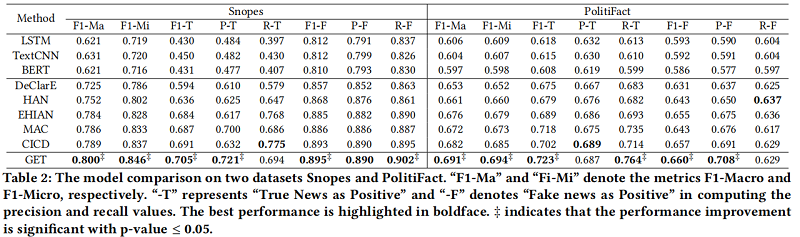
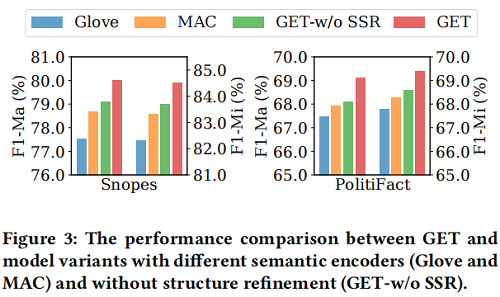
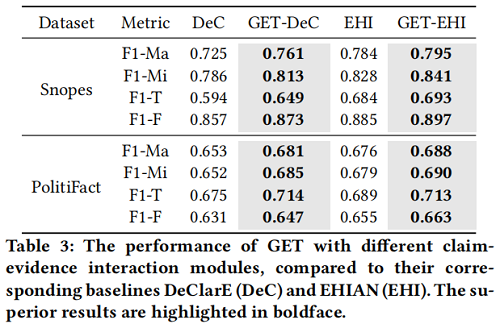
4 Experiments
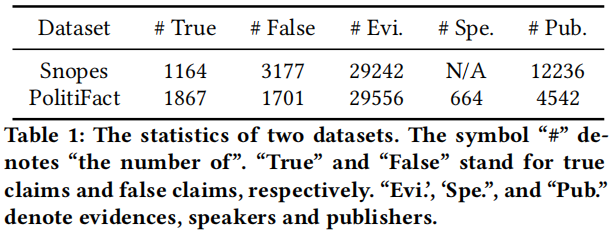
数据集
-
- LSTM
- TextCNN
- BERT
Evidence-based methods
-
- DeClarE
- EHIAN
- HAN
- MAC
- CICD