前言
本文讲述 ZooKeeper 集群架构特点、数据结构、事务ID、选主和ZAB协议具体执行过程。
服务保证
ZooKeeper 非常快速且非常简单。由于它的目标是构建更复杂的服务(如同步)的基础,因此它提供了一组保证:
【顺序一致性】来自客户端的更新将按发送顺序执行,因为只有唯一的主节点负责写请求,所以很容易保证
【原子性】更新要么成功要么失败,没有部分结果
【单一系统映像】无论连接到集群中哪个服务看到的数据都将是一样的
【可靠性】更新操作应用后,会一直存在直到客户重新这个更新
【及时性】保证系统的客户端视图在一定时间范围内是最新的。写入的数据需要同步给其他节点,最终保持一致状态
集群结构和选主
节点间通信
- 端口说明:2181(对 Client 提供服务);3888(选举 Leader);2888(集群内通讯)
- 后面的节点和前面每一个节点建立长连接,这样每两个节点之间都会有双向通信的通道
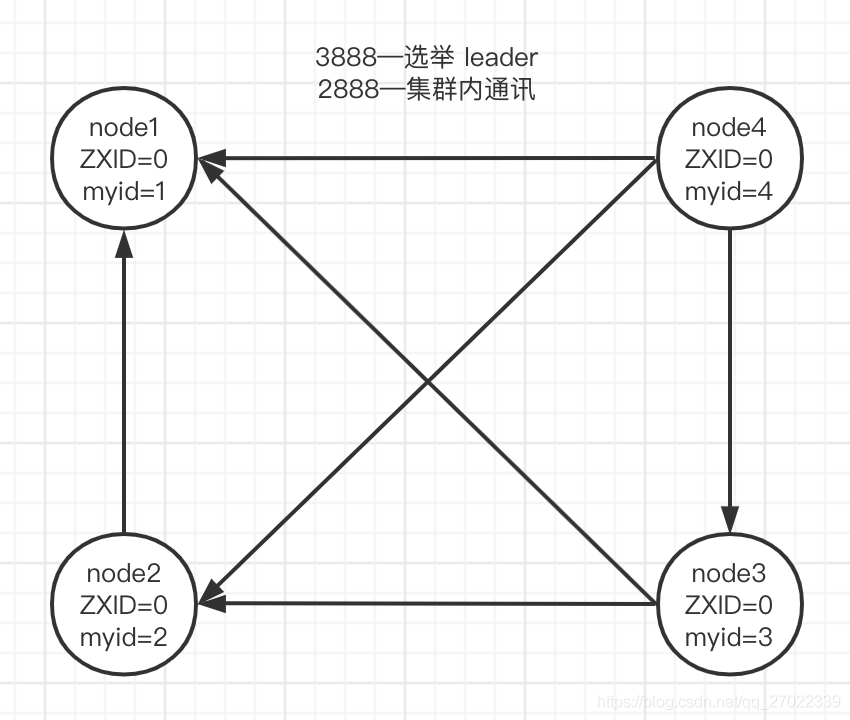
集群结构
- ZK 是一个有主集群架构,集群只有一个主。
- 每个节点都需要配置一个唯一服务 id(myid)。
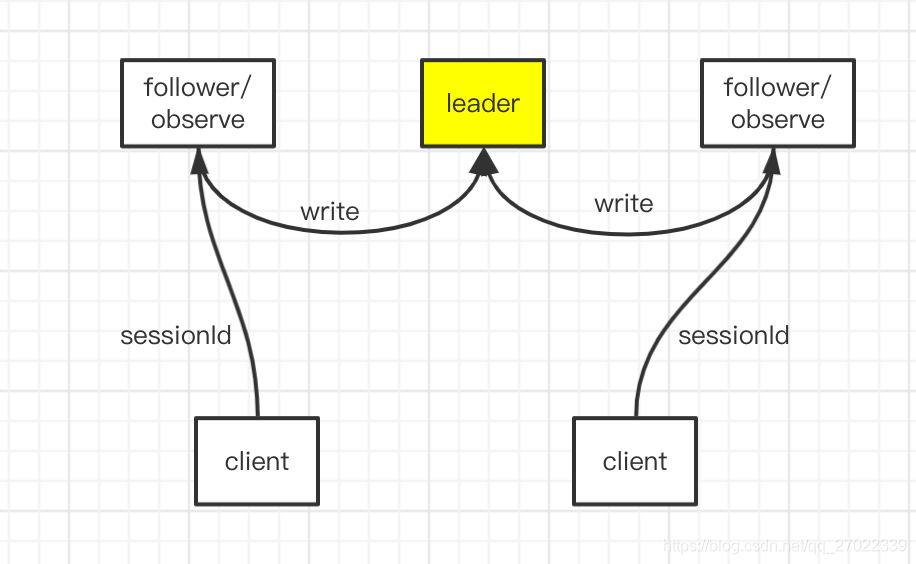
- 集群类服务分主、从、观察者三种角色。只有主节点处理写请求;所有节点都可以处理读请求;客户端通过从、观察者写入的时候,会将请求转发给主节点处理;从负责选举和顶替主节点;观察者只能负责读请求。
- 主节点宕机,集群会进入不可用状态,需要选主成功后才能对外提供服务;选主速度是非常快的,官方说选主时间不到 200 毫秒;需要过半节点参与才能成功。
- 选主的时候优先事务 id(ZXID) 值最大的,值越大就代表数据越新;再而优先服务 id(myid) 最大的。
- 客户端跟集群中节点建立连接会产生唯一 sessionId,通过这个来识别是否同一客户端。
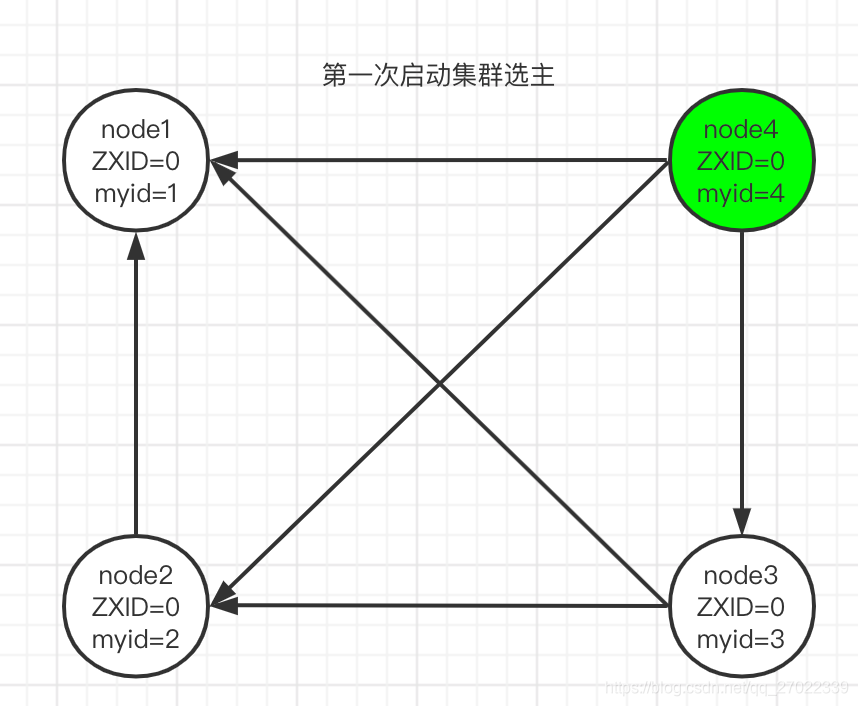
第一次启动集群选主
第一次启动集群所有节点的事务 id(ZXID) 都是 0,所以对比服务 id(myid) 最大的服务 node4 成为主节点。
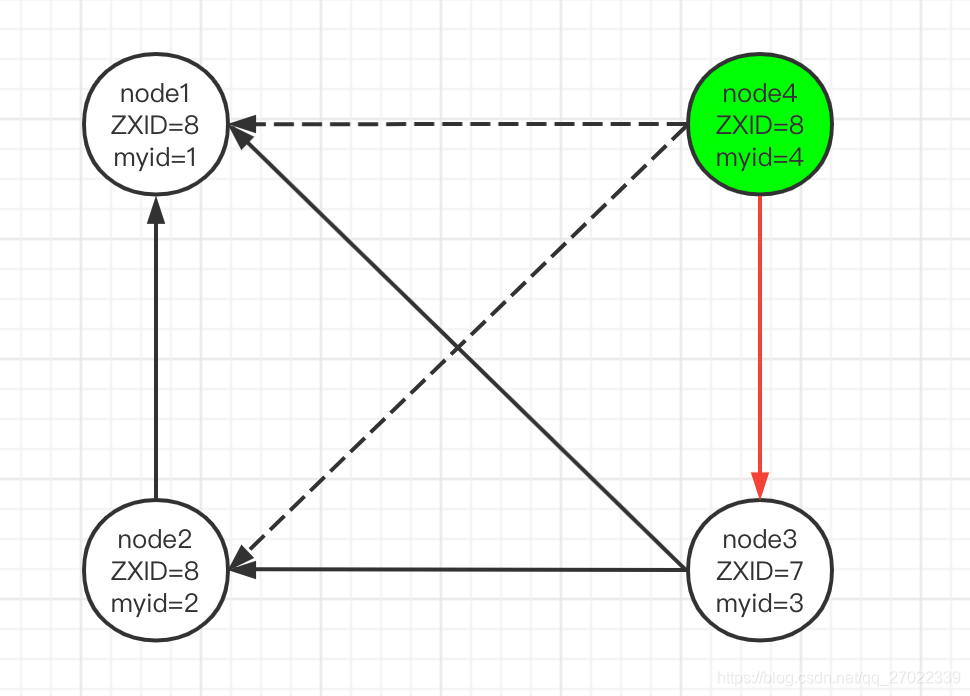
重新选主
- node4 宕机,其他 3 个节点开始选举
- 具体选举过程:
【1】node3 最先发现 node4 宕机,记录投自己 1 票,然后发送选举通知给其他节点
【2】node1 和 node2 收到 node3 的选举消息对比事务ID(ZXID)都比其大,所以否决了 node3 并返回
【3】同时触发 node1 和 node2 选举,各自记录投自己 1 票,然后发送选举通知给其他节点
| 票数/节点 | node1 | node2 | node3 |
|---|---|---|---|
| n1票数 | 1 | 0 | 0 |
| n2票数 | 0 | 1 | 0 |
| n3票数 | 0 | 0 | 1 |
【4】node3 收到 node1 和 node2 的选举通知,对比发现自己的事务ID比两者都小,所以同意了这两票并记录
【5】同时 node3 反投两者一票,自己记录,并通知他们
| 票数/节点 | node1 | node2 | node3 |
|---|---|---|---|
| n1票数 | 2 | 1 | 2 |
| n2票数 | 1 | 2 | 2 |
| n3票数 | 0 | 0 | 1 |
【5】node1 收到 node2 的选举通知,对比事务ID一样大,但是 node2 服务ID(myid) 更大,所以同意这 1 票
【6】同时 node1 反投 node2,自己记录,并通知他们
| 票数/节点 | node1 | node2 | node3 |
|---|---|---|---|
| n1票数 | 2 | 1 | 2 |
| n2票数 | 3 | 3 | 3 |
| n3票数 | 0 | 0 | 1 |
【6】node2 收到 node1 的选举通知,对比事务ID一样大,但是自己的服务ID(myid) 更大,所以否决了 node1 并返回,各自记录票数不变
【7】最终三个节点记录 node2 票数一致且最高,新主选为 node2。事务ID 代表纪元(epoch)的高 32 位值 +1,代表事务递增序号的低 32 位清零
数据节点
类型
ZK 是一个目录树结构,每一层目录可称之为节点。节点可以存储对应的数据,但是大小不能超过 1M,所以 ZK 适合作协调服务而不适合作数据库。
节点有三种类型(持久、临时、序列),一个节点只能持久、临时二选一,但是可以兼具序列节点的特点。临时 + 序列适合做分布式锁。不用担心锁过期、续期问题,只要保持连接就行。
【持久节点】会写到磁盘,重启可恢复
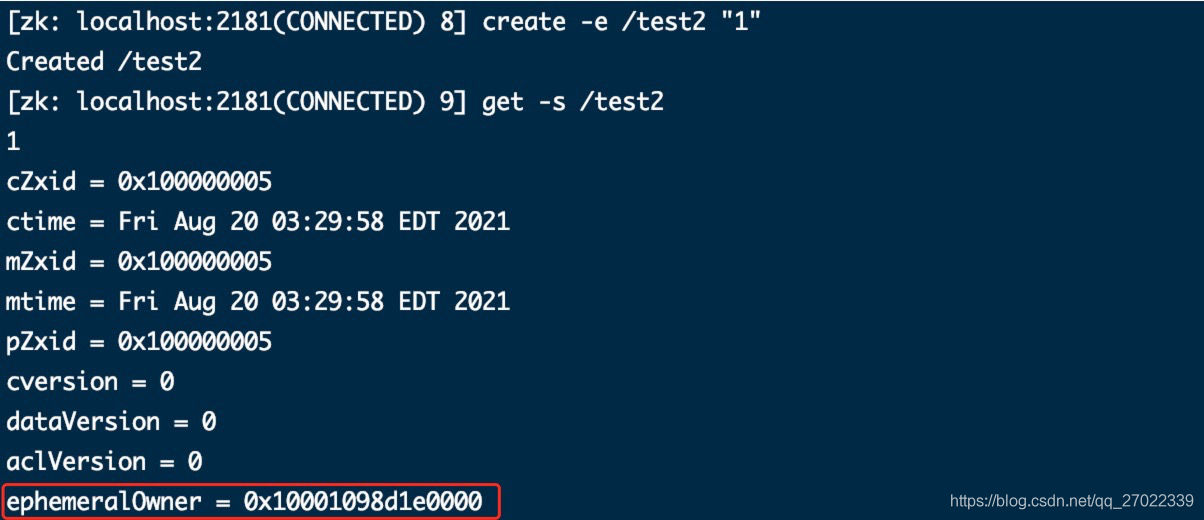
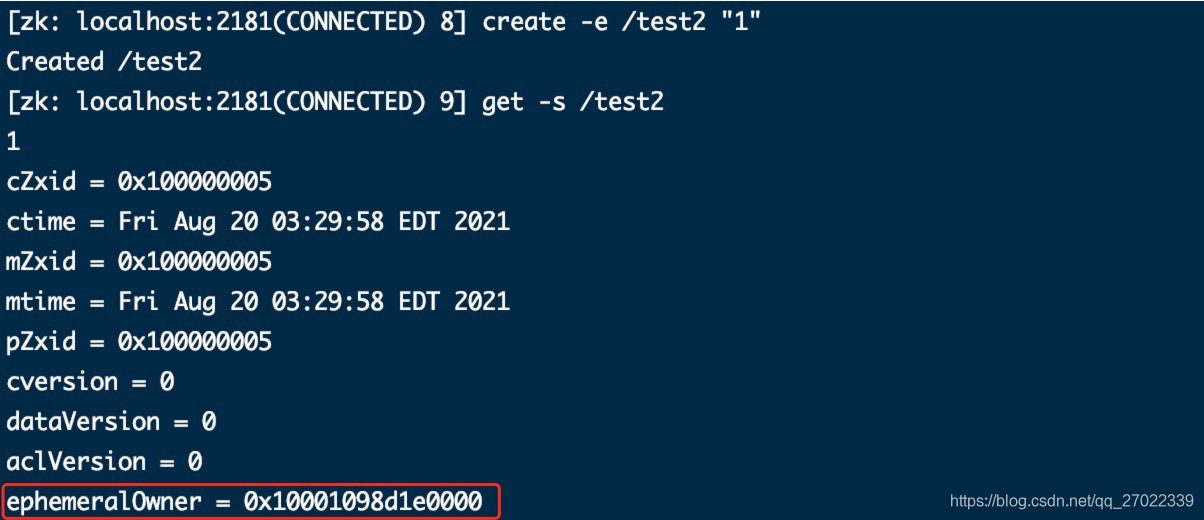
【临时节点】会和连接的 sessionId 绑定,连接断开一定时间后节点消失;且所有服务会同步这个 sessionId 绑定信息,一定时间内客户端通过相同的 sessionId 重新连接或者切换到其他服务临时节点不会消失。
【序列节点】多个请求创建同一个目录会按统一规范命名(名称 + 序号)保证唯一性。
节点信息
节点包含下列关键信息:
【cZxid】创建事务 id
【ctime】创建时间
【mZxid 】修改事务 id。开始和 cZxid 一致,如果修改了节点的数据会变成新的事务 id
【mtime】最后修改时间
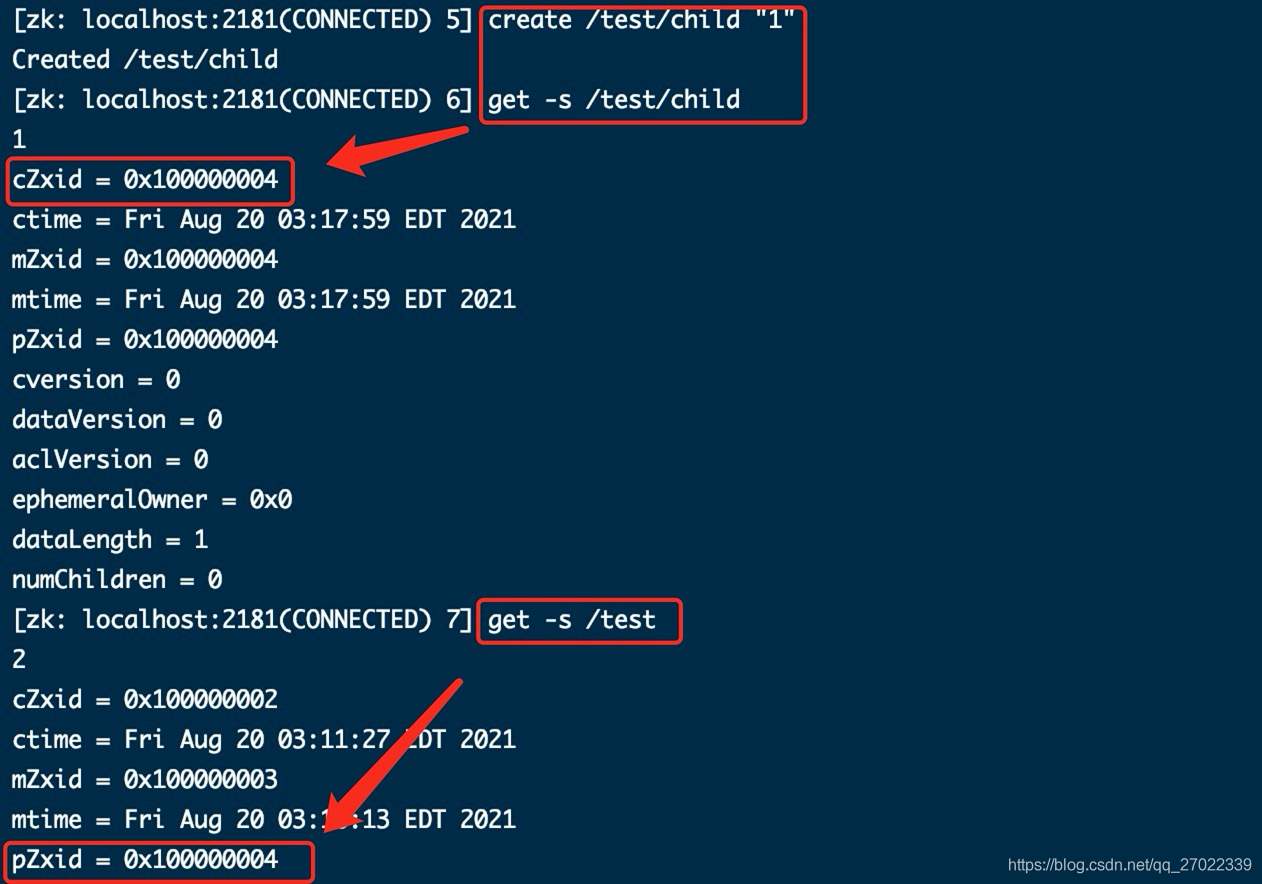
【pZxid】节点下创建最后节点 id。开始和 cZxid 一致,每当在该节点下创建新节点,会变成最新创建节点的 cZxid
【ephemeralOwner】创建该临时节点的客户端 sessionId
事务ID
ZK 集群只有主节点负责写操作,它维护一个递增的事务ID。前 32 位是 Leader 纪元(epoch),从 1 开始,每选举一次新主 +1;后 32 位是事务递增序号,从 1 开始,每个写操作(增/删/改节点、客户端建立连接产生 sessionId)都会 +1。
日志解读
通过 zkCli.sh 连接 ZK 服务。
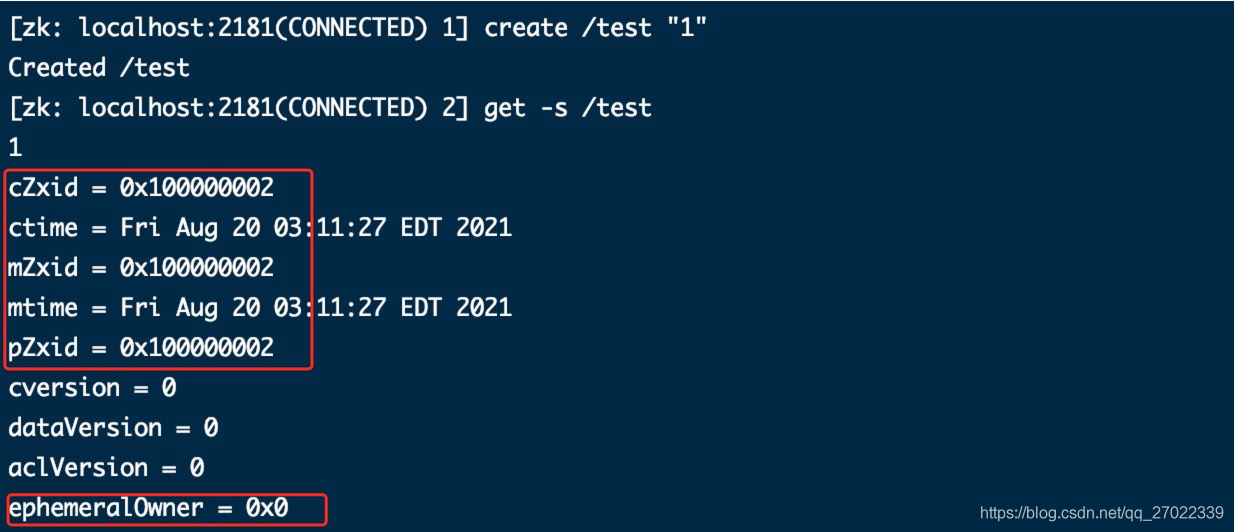
创建第一个节点 /test 同时赋值。
【cZxid = 0x100000002】产生了两个事务(产生连接并生成了 sessionId;创建了 /test 节点同时赋值),所以事务 id 递增到了 2;
【mZxid = 0x100000002】未修改 /test 节点,初始值和 cZxid 一致;
【pZxid = 0x100000002】/test 未创建子节点,初始值和 cZxid 一致;
【ephemeralOwner = 0x0】因为默认创建的不是临时节点,所以没绑定 sessionId。
修改 /test,mZxid 变成了修改事务的 id 0x100000003。
在 /test 下创建子节点 /child,可以看到 /test 节点的 pZxid 和 子节点的 cZxid 保持一致。因为 pZxid 记录的是最后创建的子节点的 cZxid。
创建临时节点,ephemeralOwner 和当前客户端 sessionId 绑定。
Paxos
Paxos 是分布式计算中消息传递的一致性算法理论,可参考这篇 《Paxos 算法理论》 。而 Raft、ZAB 等算法都是在 Paxos 基础上的进行改进或简化而生,都应用在有主集群架构。
ZAB
ZAB(Zookeeper Atomic Broadcast) 协议有崩溃恢复和消息广播两种基本的模式。
消息广播
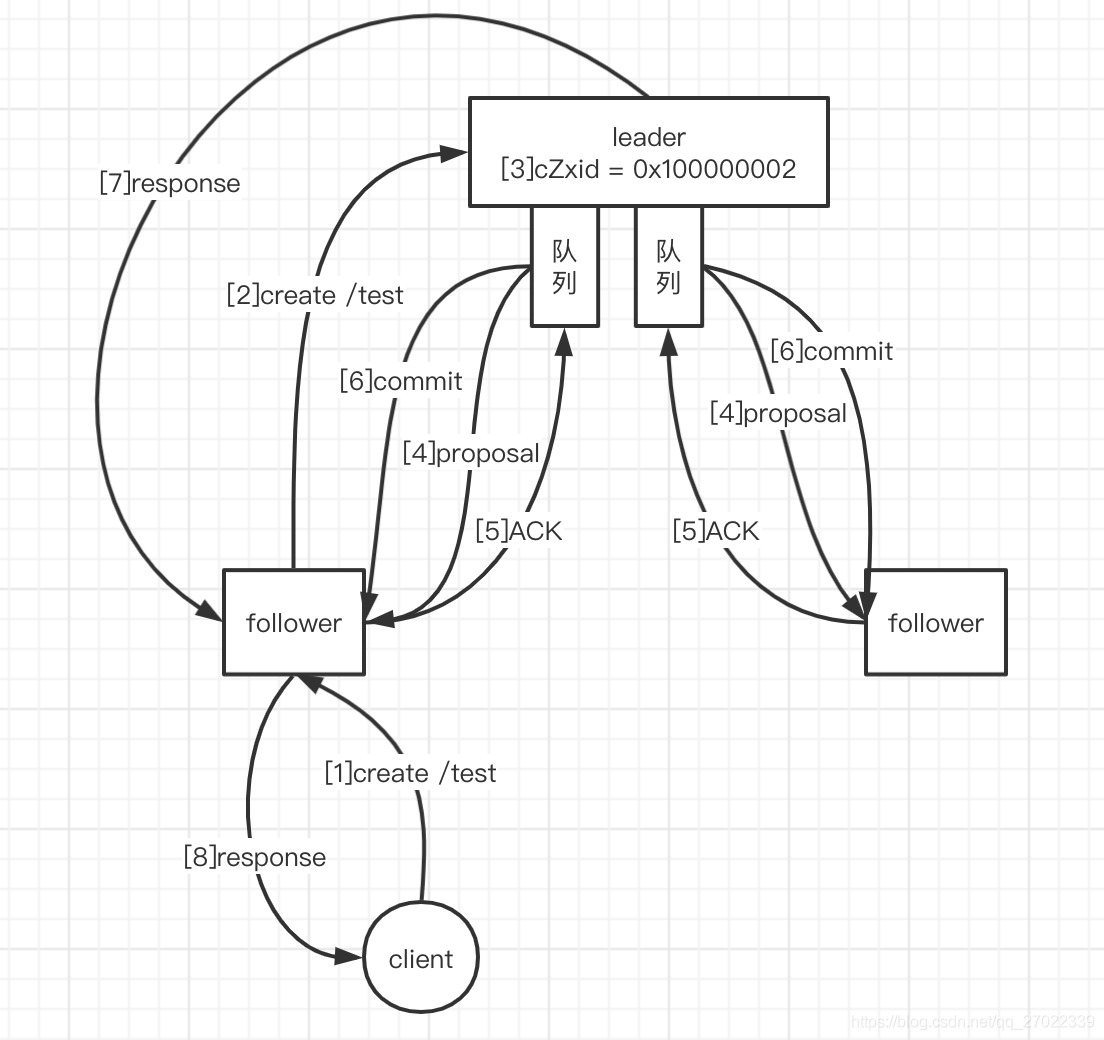
消息广播整体是一个两阶段提交过程。主节点处理更新事务后广播给从节点预提交,从节点写事务日志并反馈给主节点;主节点只要收到过半反馈再广播从节点提交更改到内存或持久化。
【1】—客户端通过从节点服务提交了写请求
【2】—从节点不能执行写操作,将操作提交给主节点
【3】—主节点生成唯一事务 id(cZxid)
【4】—主节点通过与每个从节点建立的单独队列提交提案(proposal)
【5】—从节点收到提案后,写日志,向主节点返回确认提案(ACK)
【6】—主节点收到过半节点确认提案后,自己提交(commit)并通过队列广播给从节点,如果未过半则操作无效。从节点收到提交消息会将数据写入内存,或者持久化
【7】—主节点向从节点返回操作结果
【8】—从节点将结果返回给客户端
崩溃恢复
Leader 宕机后进入崩溃恢复,先通过选举产生新主,再进入同步过程。
旧主如果在广播 proposal 之前宕机,那不会有从节点收到这个事务消息,新主自然也不会有,这个事务就丢失了。后面旧主再次加入集群会成为 Follwer 因为集群事务ID已经进入了新的纪元,旧主的事务ID小于当前,旧主之前的 proposal 也会因为数据同步回滚掉。
如果新主有之前收到的预提交(proposal) ,则会继续完成这个事务。
其他特点
- ZK 保证 CAP 中的 C(一致性)和 P(分区容错性)。
一致性体现在客户端访问任何服务节点数据都是一致的,但是这种是最终一致,因为更新广播给其他节点有两阶段(proposal、commit)提交过程。如果主广播 commit 之后,其他节点处理完成,但是客户端通过还未处理或收到 commit 的节点访问这个数据,是访问不到的。虽然它最终会和整个集群保持一致状态,但并不是那种强一致。不过可以通过客户端发起 sync 操作让该节点同步,回调后再发送读取操作来保证数据是最新的。
- ZK 保存的数据是二进制安全的
它不管客户端使用何种编码,都按二进制存储。客户端自己处理编解码过程,只要编解码一致,数据就不会有问题,这一点和 Redis 一致。