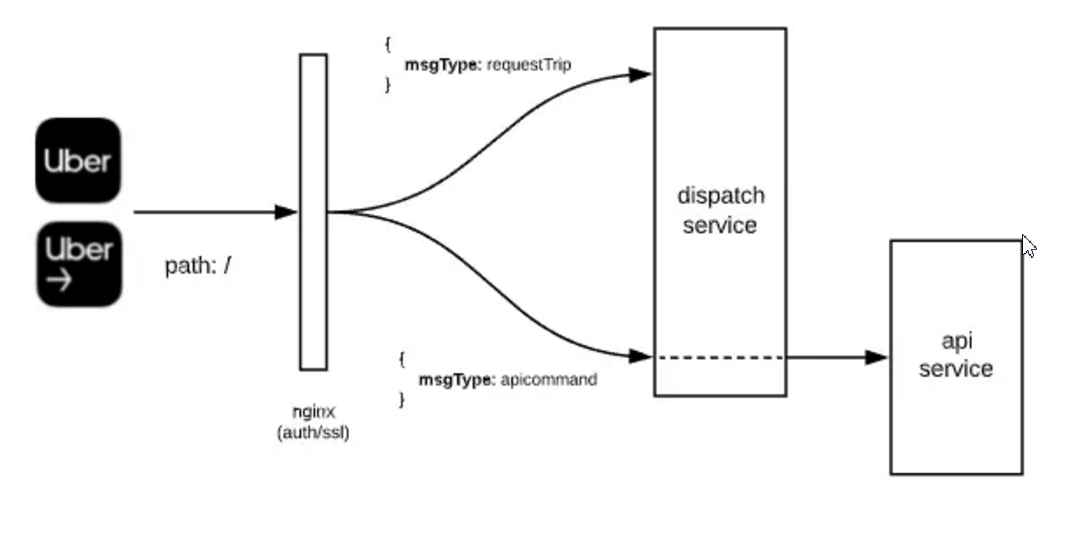
二值化与分段
sklearn.preprocessing.Binarizer
from sklearn.preprocessing import Binarizer
import pandas as pd
data = pd.read_csv("./data_full", index_col=0)
data
| Age | Survived | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | |
|---|---|---|---|---|---|---|---|
| 0 | 22.000000 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 1 | 38.000000 | 2.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 26.000000 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | 35.000000 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 4 | 35.000000 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 884 | 25.000000 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 885 | 39.000000 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 886 | 27.000000 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 887 | 19.000000 | 2.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 |
| 888 | 29.699118 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 |
887 rows × 7 columns
data1 = data.copy()
age = data1.iloc[:,0].values.reshape(-1,1)
result = Binarizer(threshold=30).fit_transform(age)
data1.iloc[:,0] = result
data1
| Age | Survived | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | |
|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 1 | 1.0 | 2.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 0.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | 1.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 4 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 884 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 885 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 886 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 887 | 0.0 | 2.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 |
| 888 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 |
887 rows × 7 columns
preprocessing.KBinsDiscretizer
from sklearn.preprocessing import KBinsDiscretizer
data2 = data.copy()
age = data2.iloc[:,0].values.reshape(-1,1)
result2 = KBinsDiscretizer(n_bins=5,encode="ordinal",strategy="uniform").fit_transform(age)
set(result2.ravel())
{0.0, 1.0, 2.0, 3.0, 4.0}
result3 = KBinsDiscretizer(n_bins=5, encode="onehot",strategy="quantile").fit_transform(age)
result3.toarray()
array([[0., 1., 0., 0., 0.],
[0., 0., 0., 0., 1.],
[0., 1., 0., 0., 0.],
...,
[0., 1., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.]])