参考:
(1)linux性能优化实战
(2)Linux Load Averages: Solving the Mystery
一、平均负载介绍
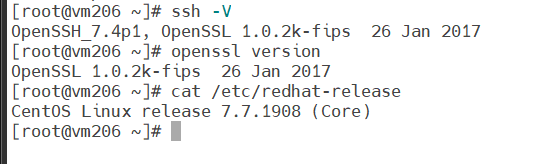
(1)查看linux系统的平均负载,可以使用命令uptime,查询结果分别表示当前时间、系统运行时间、当前登录用户数、平均负载(最近1min、5min、15min)。
# uptime
10:37:17 up 2 days, 14:49, 4 users, load average: 0.00, 0.01, 0.18
(2)使用man查看uptime的详细解释如下:
DESCRIPTION
uptime gives a one line display of the following information. The current time, how long the system has been running, how many users are cur‐rently logged on, and the system load averages for the past 1, 5, and 15 minutes.
System load averages is the average number of processes that are either in a runnable or uninterruptable state. A process in a runnable state is either using the CPU or waiting to use the CPU. A process in uninterruptable state is waiting for some I/O access, eg waiting for disk.
The averages are taken over the three time intervals. Load averages are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75% of the time.
翻译:
平均负载表示在运行状态或者不可中断状态的进程平均数量。
处于运行状态的进程,可能是在占用CPU,也可能是在等待CPU资源。
处于不可中断状态的进程,通常是在等待IO资源,如磁盘。
平均负载是取三个时间段的平均值。
平均负载针对不同数量cpu的系统,不是一个标准值,比如平均值为1时,如果在1个CPU的系统上表明该系统CPU一直处于运行状态,
如果在4个cpu的系统上表明cpu的空闲时间为75%(占用时间为20%,1/4)。
runnable状态:R, 运行状态,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。
uninterruptable状态:D,Disk Sleep,又称不可中断状态睡眠(Uninterruptible Sleep)。睡眠状态的进程,处于等待队列中,但是不允许被中断打断,通常产生在进程与跟硬件交互阶段;仅当IO资源恢复时,该进程才能正常运行。
(3)个人理解
平均负载是一段时间内的特定进程数量平均值,这些特定的进程是包括R状态和D状态;
R状态是容易理解的,包括就绪状态和运行状态的进程;
难点在与D状态进程的理解:长时间等待不到IO资源的进程,通常意味着IO资源或者外设有故障。
平均负载在最近1min、5min、15min的值,可以估计系统负载的趋势;
平均负载需要结合CPU数量来评估,系统合理的平均负载为CPU数量*70%;
平均负载出现异时,通常有三种场景:
- CPU密集型,即进程的运算量较大,导致其他很多进程处于就绪队列中,此时CPU资源成为瓶颈;
- io密集型,即大量的进程处于不可中断睡眠状态,等待IO资源,此时IO资源成为瓶颈;
- 多进程,即进程的数量较多,进程调度耗费时间较长,成为瓶颈。
二、工具说明
(1)压测工具:stress
stress 是一个 Linux 系统压力测试工具,可以对CPU、Memory、IO、磁盘进行压力测试。
-t, --timeout <N>
Timeout after N seconds. This option is ignored by -n.
在N秒后结束压力测试程序。
-c, --cpu <N>
Spawn N workers spinning on sqrt().
拉起N个进程,循环计算sqrt(),以产生CPU压力。
-i, --io <N>
Spawn N workers spinning on sync().
拉起N个进程,循环调用sync将内存缓冲区内容写到磁盘上,以产生io压力。
-m, --vm <N>
Spawn N workers spinning on malloc()/free().
拉起N个进程,循环调用malloc/free函数分配和释放内存,以产生内存压力。
-d, --hdd <N>
Spawn N workers spinning on write()/unlink().
拉起N个进程,循环调用write/unlink函数进程文件创建删除(创建文件,写入内容,删除文件)。
(2)uptime
获取主机运行时间和查询系统平均负载。
(3)mpstat
sysstat工具的一个命令,用于多CPU环境下,显示各个可用CPU的状态信息,存放在/proc/stat文件。
命令格式:
mpstat [选项] [<间隔时间> [<次数>]]
-P参数,可以指定CPU编号。
显示字段说明:
%user:表示处理用户进程所使用CPU的百分比。
%nice:表示在用户级别处理经nice降级的程序所使用CPU的百分比。
%system:表示内核进程使用的CPU百分比。
%iowait:表示等待进行I/O所占用CPU时间百分比。
%irq:表示用于处理系统中断的CPU百分比。
%soft:表示用于处理软件中断的CPU百分比。
%steal:在管理程序为另一个虚拟处理器服务时,显示虚拟的一个或多个CPU在非自愿等待中花费的时间的百分比。
%guest:表示一个或多个CPU在运行虚拟处理器时所花费的时间百分比。
%gnice:表示一个或多个CPU在运行经nice降级后的虚拟处理器时所花费的时间百分比。
%idle:CPU的空闲时间百分比。
示例:
// 监控所有CPU,每个5秒打印一次,持续打印
# mpstat -P ALL 5
Linux 5.15.0-46-generic (iZbp1b6ydbgiddbdhj5p1zZ) 11/08/2022 _x86_64_ (2 CPU)
02:31:25 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:31:30 PM all 6.57 0.00 3.13 0.00 0.00 0.10 0.00 0.00 0.00 90.20
02:31:30 PM 0 8.48 0.00 3.23 0.00 0.00 0.20 0.00 0.00 0.00 88.08
02:31:30 PM 1 4.65 0.00 3.03 0.00 0.00 0.00 0.00 0.00 0.00 92.32
02:31:30 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:31:35 PM all 0.30 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.49
02:31:35 PM 0 0.40 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.39
02:31:35 PM 1 0.20 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.59
02:31:35 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:31:40 PM all 0.30 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 99.19
02:31:40 PM 0 0.20 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 99.39
02:31:40 PM 1 0.40 0.00 0.60 0.00 0.00 0.00 0.00 0.00 0.00 99.00
02:31:40 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:31:45 PM all 0.30 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00 99.60
02:31:45 PM 0 0.40 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.39
02:31:45 PM 1 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.80
(4)pidstat
sysstat工具的一个命令,用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况。
pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息
命令格式:
pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]
-u:默认的参数,显示各个进程的cpu使用统计
-r:显示各个进程的内存使用统计
-d:显示各个进程的IO使用情况
-p:指定进程号
-w:显示每个进程的上下文切换情况
-t:显示选择任务的线程的统计信息外的额外信息
-T { TASK | CHILD | ALL } 指定pidstat监控对象。TASK表示报告独立的task,CHILD关键字表示报告进程下所有线程统计信息。
ALL表示报告独立的task和task下面的所有线程。
-V:版本号
-h:在一行上显示了所有活动,这样其他程序可以容易解析。
-I:在SMP环境,表示任务的CPU使用率/内核数量
-l:显示命令名和所有参数
显示字段说明:
PID:进程ID
%usr:进程在用户空间占用cpu的百分比
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令
示例:
// 监控各个进程的cpu使用情况,间隔5秒,打印一次
# pidstat -u 5 1
Linux 5.15.0-46-generic (iZbp1b6ydbgiddbdhj5p1zZ) 11/08/2022 _x86_64_ (2 CPU)
02:43:43 PM UID PID %usr %system %guest %wait %CPU CPU Command
02:43:48 PM 0 1 0.20 0.00 0.00 0.00 0.20 0 systemd
02:43:48 PM 103 778 0.20 0.20 0.00 0.20 0.40 1 dbus-daemon
02:43:48 PM 0 1089 2.79 1.60 0.00 0.00 4.39 1 AliYunDun
02:43:48 PM 0 1461 0.20 0.00 0.00 0.00 0.20 0 aliyun-service
02:43:48 PM 0 57210 0.20 0.20 0.00 0.20 0.40 1 systemd-journal
02:43:48 PM 0 69572 0.00 0.20 0.00 0.00 0.20 1 pidstat
三、典型场景分析
1、CPU密集型
(1)模拟CPU压力:当前测试环境有2个CPU,因此拉起两个进程,使得两个CPU使用率达到100%,其平均负载趋近于2;
// 拉起2个进程,循环计算sqrt(),持续时间为600s;
stress --cpu 2 --timeout 600
(2)持续观测平均负载:
# watch -d uptime
15:04:29 up 2 days, 19:16, 6 users, load average: 0.82, 1.05, 0.71
15:04:49 up 2 days, 19:17, 6 users, load average: 1.15, 1.11, 0.74
15:05:58 up 2 days, 19:18, 6 users, load average: 1.74, 1.30, 0.83
15:06:48 up 2 days, 19:19, 6 users, load average: 2.26, 1.49, 0.92
(3)查看CPU总体信息:
# mpstat -P ALL 5
03:06:38 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
03:06:43 PM all 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:06:43 PM 0 99.20 0.00 0.80 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:06:43 PM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
(4)查看各进程的CPU占用信息:pidstat -u 5 1
# pidstat -u 5 1
Linux 5.15.0-46-generic (iZbp1b6ydbgiddbdhj5p1zZ) 11/08/2022 _x86_64_ (2 CPU)
03:07:40 PM UID PID %usr %system %guest %wait %CPU CPU Command
03:07:45 PM 0 1 0.20 0.00 0.00 0.20 0.20 0 systemd
03:07:45 PM 0 14 0.00 0.20 0.00 0.00 0.20 1 rcu_sched
03:07:45 PM 0 20 0.00 0.20 0.00 0.00 0.20 1 migration/1
03:07:45 PM 0 21 0.00 0.20 0.00 0.00 0.20 1 ksoftirqd/1
03:07:45 PM 103 778 0.20 0.20 0.00 0.20 0.40 0 dbus-daemon
03:07:45 PM 0 1089 3.79 0.60 0.00 0.00 4.39 0 AliYunDun
03:07:45 PM 0 1461 0.00 0.20 0.00 0.00 0.20 0 aliyun-service
03:07:45 PM 0 57210 0.20 0.00 0.00 0.00 0.20 1 systemd-journal
03:07:45 PM 0 57235 0.20 0.00 0.00 0.00 0.20 0 ModemManager
03:07:45 PM 0 69194 0.00 0.20 0.00 0.00 0.20 0 kworker/0:1-events
03:07:45 PM 0 72385 93.41 0.00 0.00 6.19 93.41 1 stress
03:07:45 PM 0 72386 94.21 0.00 0.00 5.59 94.21 0 stress
(5)数据分析
通过uptime可以看到,系统的平均负载逐步增加到2.0;
通过mpstat查询可知,两个CPU的占用率接近100%,且均为用户进程占用,iowait占用率为0;
使用pidstat确认,两个stress用户进程,CPU占用率接近100%;
至此,可以确定:两个用户进程stress,占用CPU过多,导致平均负载过大。
2、IO密集型
(1)模拟IO压力,循环调用sync将内存缓冲区内容写到磁盘上,持续时间600s:stress -i 2 --timeout 600
(2)持续观测平均负载:
# watch -d uptime
15:22:30 up 2 days, 19:34, 6 users, load average: 0.76, 0.79, 0.97
15:22:48 up 2 days, 19:35, 6 users, load average: 1.11, 0.87, 1.00
15:23:33 up 2 days, 19:35, 6 users, load average: 1.61, 1.03, 1.05
15:24:43 up 2 days, 19:37, 6 users, load average: 2.24, 1.32, 1.15
(3)查看CPU总体信息:
# mpstat -P ALL 5
03:28:18 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
03:28:23 PM all 1.33 0.00 30.63 28.75 0.00 2.22 0.00 0.00 0.00 37.07
03:28:23 PM 0 1.05 0.00 29.98 29.35 0.00 0.00 0.00 0.00 0.00 39.62
03:28:23 PM 1 1.65 0.00 31.37 28.07 0.00 4.72 0.00 0.00 0.00 34.20
(4)查看各进程的CPU占用信息:pidstat -u 5 1
# pidstat -u 5 1
Linux 5.15.0-46-generic (iZbp1b6ydbgiddbdhj5p1zZ) 11/08/2022 _x86_64_ (2 CPU)
03:25:31 PM UID PID %usr %system %guest %wait %CPU CPU Command
03:25:36 PM 0 1 0.20 0.00 0.00 0.00 0.20 0 systemd
03:25:36 PM 0 14 0.00 0.20 0.00 0.00 0.20 0 rcu_sched
03:25:36 PM 0 21 0.00 0.20 0.00 0.00 0.20 1 ksoftirqd/1
03:25:36 PM 0 89 0.00 0.80 0.00 0.00 0.80 0 kworker/0:1H-kblockd
03:25:36 PM 0 169 0.00 13.57 0.00 0.40 13.57 1 kworker/1:1H-kblockd
03:25:36 PM 0 305 0.00 0.20 0.00 0.00 0.20 0 jbd2/vda3-8
03:25:36 PM 103 778 0.20 0.20 0.00 0.40 0.40 1 dbus-daemon
03:25:36 PM 0 1050 0.00 0.20 0.00 0.00 0.20 0 AliYunDunUpdate
03:25:36 PM 0 1089 3.79 2.40 0.00 0.00 6.19 1 AliYunDun
03:25:36 PM 0 1461 0.20 0.00 0.00 0.00 0.20 0 aliyun-service
03:25:36 PM 0 57210 0.20 0.00 0.00 0.20 0.20 1 systemd-journal
03:25:36 PM 0 75259 0.40 26.75 0.00 6.99 27.15 0 stress
03:25:36 PM 0 75260 0.60 26.15 0.00 7.39 26.75 0 stress
03:25:36 PM 0 75310 0.00 0.20 0.00 0.00 0.20 1 kworker/u4:2-events_unbound
(5)数据分析
通过uptime可以看到,压力加载后,系统的平均负载逐步增加到2.0;
通过mpstat查询可知,用户进程CPU占用率不到2%,内核进程CPU占用率约30%,iowait也近30%,说明平均负载是由于iowait升高引起;
使用pidstat确认,两个stress进程引起iowait升高,从而导致平均负载异常。
3、多进程
(1)模拟多进程调度压力,出现大量进程等待CPU的场景;stress -c 8 --timeout 600
(2)持续观测平均负载:
# watch -d uptime
15:44:44 up 2 days, 19:57, 6 users, load average: 1.13, 1.13, 1.10
15:45:14 up 2 days, 19:57, 6 users, load average: 2.53, 1.43, 1.20
15:45:49 up 2 days, 19:58, 6 users, load average: 4.95, 2.16, 1.45
15:47:51 up 2 days, 20:00, 6 users, load average: 7.62, 4.11, 2.26
(3)查看CPU总体信息:
# mpstat -P ALL 5
03:46:23 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
03:46:28 PM all 99.40 0.00 0.60 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:46:28 PM 0 99.20 0.00 0.80 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:46:28 PM 1 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00
(4)查看各进程的CPU占用信息:pidstat -u 5 1
# pidstat -u 5 1
Linux 5.15.0-46-generic (iZbp1b6ydbgiddbdhj5p1zZ) 11/08/2022 _x86_64_ (2 CPU)
03:48:07 PM UID PID %usr %system %guest %wait %CPU CPU Command
03:48:12 PM 0 1 0.20 0.00 0.00 0.00 0.20 0 systemd
03:48:12 PM 0 14 0.00 0.20 0.00 0.00 0.20 1 rcu_sched
03:48:12 PM 103 778 0.20 0.00 0.00 0.20 0.20 0 dbus-daemon
03:48:12 PM 0 812 0.20 0.00 0.00 0.20 0.20 0 systemd-logind
03:48:12 PM 0 1050 0.00 0.20 0.00 0.00 0.20 1 AliYunDunUpdate
03:48:12 PM 0 1089 2.98 1.59 0.00 0.00 4.57 0 AliYunDun
03:48:12 PM 0 57210 0.20 0.00 0.00 0.00 0.20 1 systemd-journal
03:48:12 PM 0 57223 0.20 0.00 0.00 0.00 0.20 0 polkitd
03:48:12 PM 0 78006 24.45 0.20 0.00 75.35 24.65 1 stress
03:48:12 PM 0 78007 22.66 0.00 0.00 76.94 22.66 1 stress
03:48:12 PM 0 78008 22.86 0.00 0.00 76.74 22.86 0 stress
03:48:12 PM 0 78009 23.66 0.20 0.00 75.94 23.86 1 stress
03:48:12 PM 0 78010 22.47 0.00 0.00 76.94 22.47 1 stress
03:48:12 PM 0 78011 23.66 0.00 0.00 75.75 23.66 0 stress
03:48:12 PM 0 78012 23.86 0.00 0.00 75.94 23.86 0 stress
03:48:12 PM 0 78013 22.66 0.20 0.00 76.54 22.86 0 stress
03:48:12 PM 0 78667 0.00 0.20 0.00 0.00 0.20 0 pidstat
(5)数据分析
通过uptime可以看到,系统的平均负载迅速增加,到达7.x;
通过mpstat查询可知,两个CPU的占用率接近100%,iowait占用率为0;
使用pidstat查看,显然8个stress进程,等待CPU的时间(%wait 列)高达75%,最终导致CPU过载。
四、思考
(1)平均负载在统计进程数量时,为什么要统计D状态的进程数量?
D状态进程数量主要体现了系统的IO负载,当平均负载引入D状态进程数量后,就表明平均负载不仅关心CPU的占用率,更一般的,还包括IO负载。
(2)已知CPU个数和平均负载,是否可以判断系统的运行状态是否正常,或者是否需要调整?
平均负载的参考价值优先,也需要同步参考其他指标,Linux Load Averages: Solving the Mystery有详细说明。
(3)为什么在典型场景3中,大量进程占用CPU时,系统仍然能够正常运行,包括各个查询指令的运行?
CPU调度策略强大,使一些查询类命令延迟较低,整体感觉不到系统的卡顿。