背景
某医院信息科接到CIS系统磁盘空间不足告警,通过排查发现tempdb的日志文件暴增,已经涨到了130G左右,并且还在持续增长中。需要我们紧急排查原因。
现象
登陆到服务器里,确实看到了如上所说,D盘空间仅剩14.5G,并且tempdb的日志文件已经达到了130G

登录到SQL专家云,通过趋势分析进行回溯,在1月22日上午8点40分之前,tempdb日志文件的总大小(蓝线)一直保持在500M,使用空间(黄线)也能被重用。从这个时间点之后,总空间和使用空间一直增长。

分析
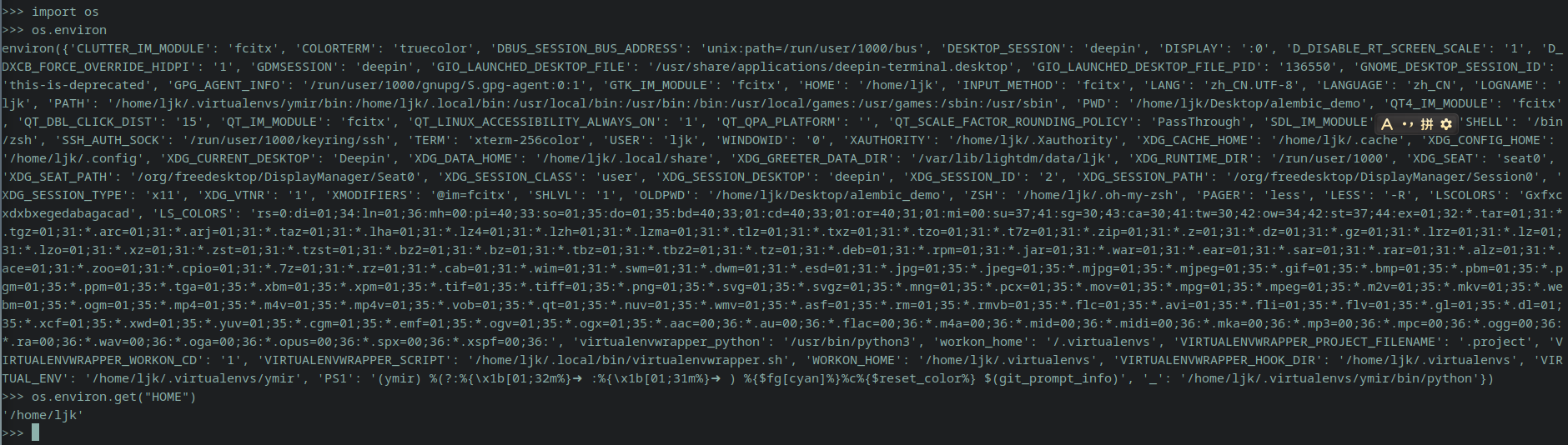
首先要了解一下tempdb日志文件重用的原理,因为tempdb的恢复模式是简单的,所以只要对tempdb做完了checkpoint后,这个时间点之前的空间就可以重复使用了。在SQL Server里面,所有的日志记录都有严格顺序,中间不可以有任何跳跃,如果某个时间点存在没有提交的事务,因为事务可能会回滚,这些日志记录都有可能需要被用来做回滚,因此SQL Server会标记从这个事务开始的所有日志记录(不管和这个事务有没有关系)为活动事务日志,导致日志文件不会被重用,只能是一直增长。据此推测在1月22日上午8点40分左右有一个或者多个会话有没有提交的事务,并且一直到现在为止都没有提交。进入SQL专家云的空闲会话页面,点击有未提交事务选项卡,开始查找这个时间段内的空闲会话,找到了ID为667的会话,空闲时间为16185分钟,语句最后请求结束时间正好对应上Tempdb开始增长的时间点。

点击进入完整信息,可以看到该会话在1月22日8点29分08秒建立的,在1月22日8点29分10秒开始了一个事务,在1月22日8点40分11秒后执行最后一条语句后不再执行语句,到目前为止该事务已经开了11天的时间。

解决
KILL掉这个会话,过几分钟后观察日志文件的使用空间已经下降。

但是日志文件的总大小是不变的,再执行收缩tempdb日志文件的命令即可释放掉磁盘的空间。

总结
这类问题的大多数原因是应用程序实现不严谨造成的,正常的流程下会提交事务,关闭数据库连接,但是如果中间某个步骤出错了,因为没有异常处理,在这个出错步骤后面的提交事务和关闭连接的代码都没有执行到,最终导致事务和连接的泄露。

所以根本的解决办法是修改程序,因为客观原因无法修改的,只能通过变通的方法来解决,例如在数据库中创建一个定期运行的作业,杀掉空闲时间长的会话。或者在SQL专家云中启用查杀会话的任务。


其它
很多客户也碰到过这样的现象,日志文件使用空间一直增长,很长时间内都不会下降,确认过肯定没有未提交的事务。这是因为tempdb的特殊性,日志文件使用率超过70%才会触发checkpoint,重用的快慢取决于tempdb日志文件的大小。例如日志文件的总大小为100GB, 使用空间只有增长到70GB才会checkpoint,然后使用空间才会下降。所以不要把日志文件设置的太大。