一、开箱即用的相似度配置
Elasticsearch允许您配置文本评分算法或每个字段的相似度。相似度设置提供了一种选择缺省BM25之外的文本相似度算法的简单方法,例如:boolean
只有基于文本的字段类型(如文本和关键字)支持此配置。
唯一可以开箱即用的相似之处,无需任何进一步 配置包括:
-
BM25
Okapi BM25 algorithm,在 Elasticsearch 和 Lucene 中默认使用的算法。 -
boolean
一个简单的布尔相似性,在不需要全文排名时使用 并且分数应仅基于查询词是否匹配。 布尔相似性为术语提供与其查询提升相等的分数。
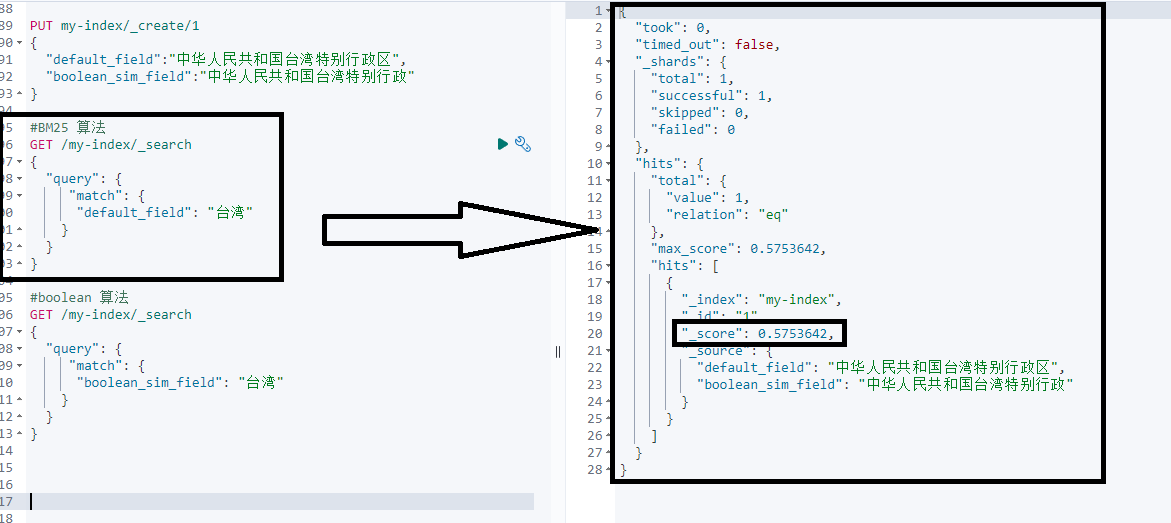
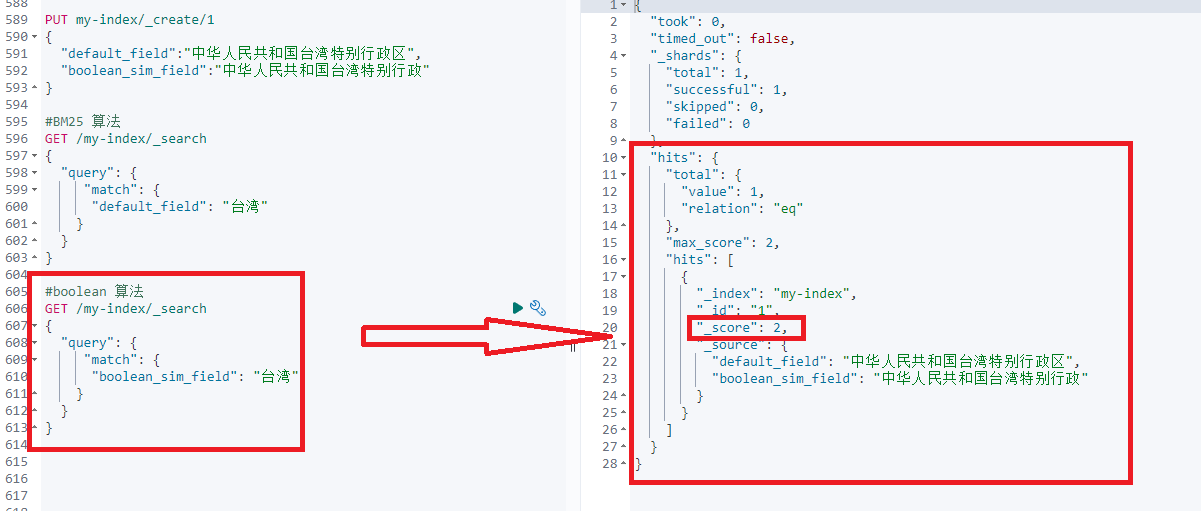
首次创建字段时可以在字段级别设置, 如下:similarity
PUT my-index-000001
{
"mappings": {
"properties": {
"default_field": { //default_field BM25
"type": "text"
},
"boolean_sim_field": {
"type": "text",
"similarity": "boolean" // boolean_sim_field boolean
}
}
}
}
二、自定义相似度配置
创建方法
PUT /index
{
"settings": {
"index": {
"similarity": {
"my_similarity": {
"type": "DFR",
"basic_model": "g",
"after_effect": "l",
"normalization": "h2",
"normalization.h2.c": "3.0"
}
}
}
}
}
创建映射
PUT /index/_mapping
{
"properties" : {
"title" : { "type" : "text", "similarity" : "my_similarity" }
}
}
已存在的相似度算法
BM25、DFR、DFI、IB、LM Dirichlet 可根据相关参数进行配置
如BM25:
| 参数 | 说明 |
|---|---|
| k1 | 控制非线性项频归一化(饱和)。缺省值为1.2。 |
| b | 控制文档长度规范化tf值的程度。缺省值为0.75。 |
| discount_overlaps | 确定计算范数时是否忽略重叠令牌(位置增量为0的令牌)。默认情况下,这是真的,这意味着在计算规范时不计算重叠令牌。 |
还可通过脚本方式指定算法
PUT /index
{
"settings": {
"number_of_shards": 1,
"similarity": {
"scripted_tfidf": {
"type": "scripted",
"script": {
"source": "double tf = Math.sqrt(doc.freq); double idf = Math.log((field.docCount+1.0)/(term.docFreq+1.0)) + 1.0; double norm = 1/Math.sqrt(doc.length); return query.boost * tf * idf * norm;"
}
}
}
},
"mappings": {
"properties": {
"field": {
"type": "text",
"similarity": "scripted_tfidf"
}
}
}
}