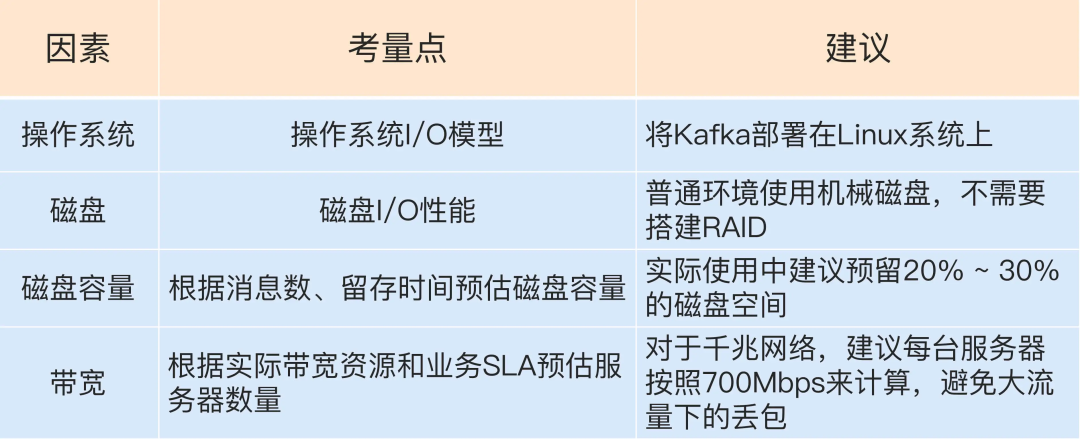
机器学习
数据
- 数据整体叫做数据集(\(Data\ Set\))
- 每一行数据称为一个样本(\(Sample\))
- 表示分类名称的那一列称为标记(\(Label\))
- 标记一般会写作\(y\)。
- 除去标记的那一列,剩下每一列称为样本的一个特征(\(Feature\))
- 数据样本整体(去除标记)一般会写作\(X\),第i行样本一般记作\(X^{(i)}\),第\(i\)个样本的第\(j\)个特征值记作\(X^{(i)}_j\)
特征空间(\(Feature\ space\))
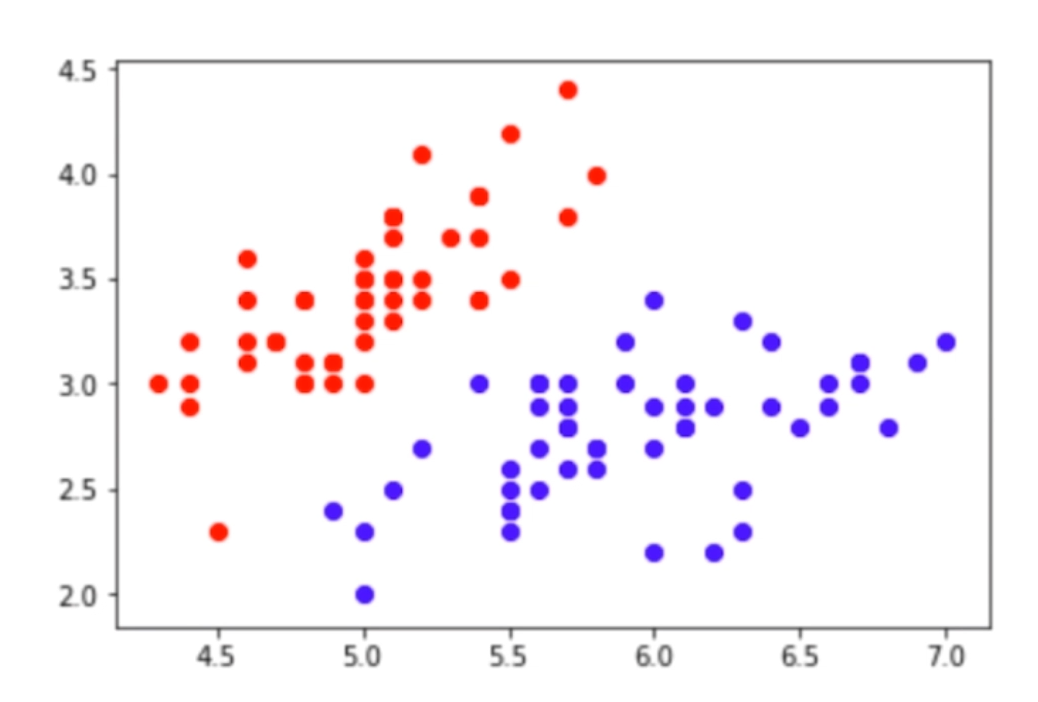
- 每个样本的特征都是在特征空间里面的一个点
- 分类的任务的本质就是将数据在特征空间里面切分
- 多少个特征就可以拓展到多少维,维度越高越精细(在低维空间预处理得到结论,然后再推广到高维空间)
机器学习任务
机器学习解决问题角度分类
分类任务
-
二分类
- 判断是否为垃圾邮件
- 判断信用卡发卡是否有风险
-
多分类
- 数字识别
- 图像识别
- 发卡风险评级
-
多标签分类
- 多标签分类任务中一条数据可能有多个标签,每个标签可能有两个或者多个类别
- 预测给定的图片是狗还是猫,以及它的皮毛是长还是短。
回归任务
结果是一个连续数字的值,而并不是一个类别
- 房屋价格
- 市场分析
- 学生成绩
小总结
- 回归任务可以简化为分类任务
- 多分类任务可以转化为二分类任务
机器学习方法
监督学习
既有特征本身,又有特征所对应的标签。可以说是给了一个带有答案的训练集, 可以处理分类和回归问题。
- 图标有标定的信息
- 市场上的交易基本信息和交易金额
监督学习算法
- k近邻
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
非监督学习
给出的训练集没有答案
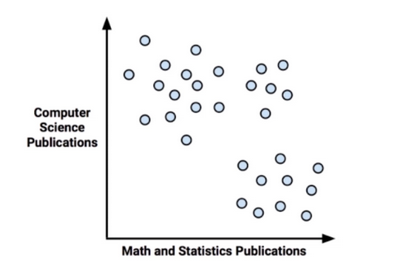
聚类分析
对于没有标记的数据来进行分类
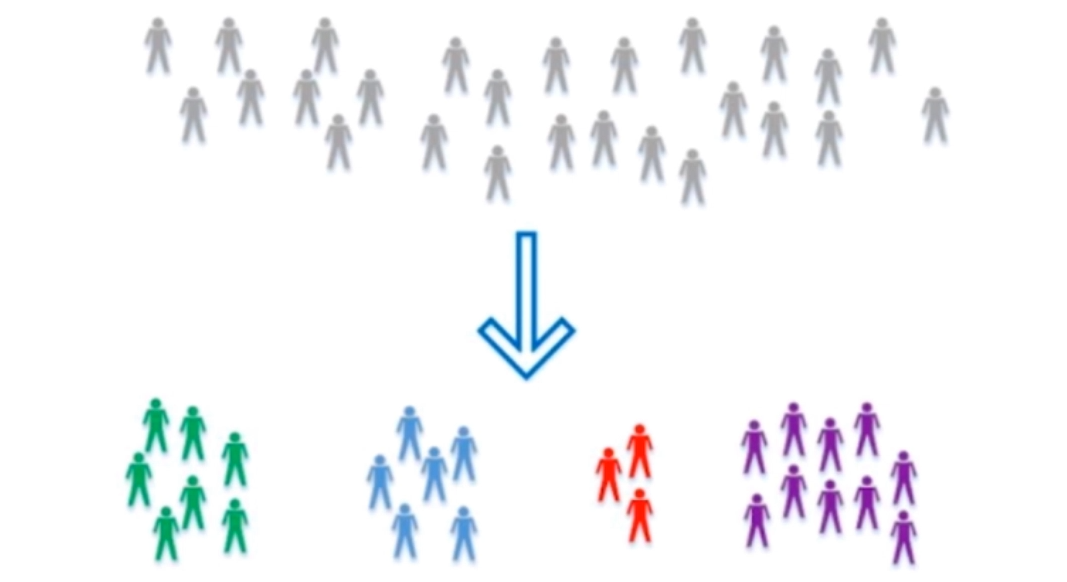
对数据降维处理
-
特征提取
- 去除没有贡献的数据
-
特征压缩
- 尽量少的损失信息的情况下,将高维的特征向量降到低维
- PCA
-
异常检测
红点为异常数据
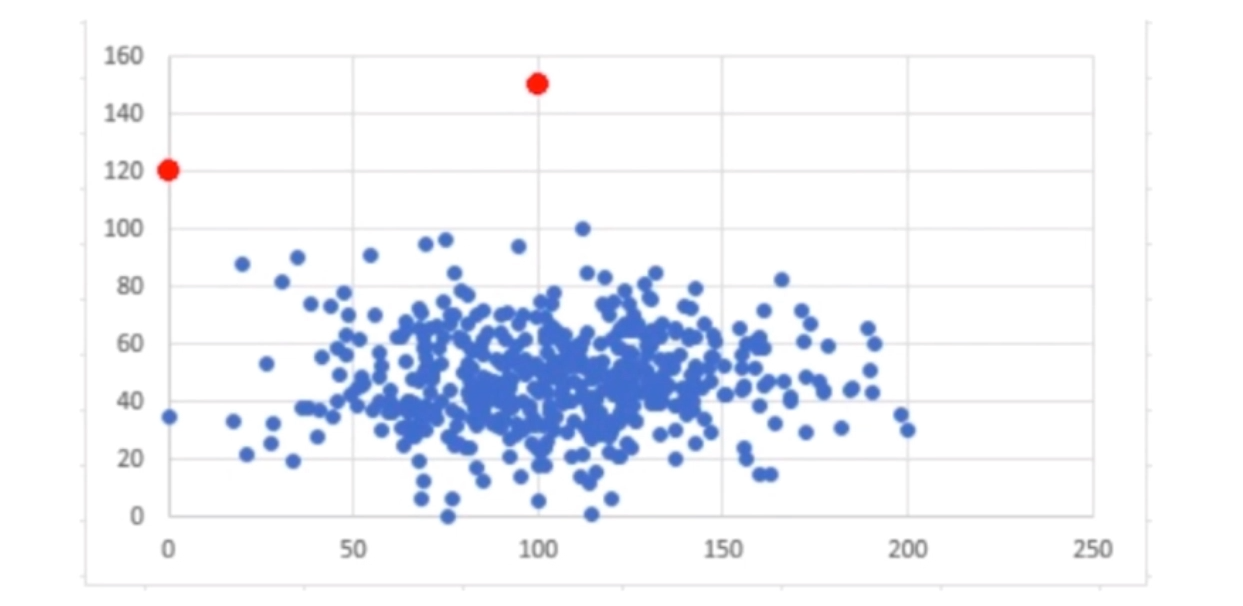
-
方便可视化
半监督学习
一部分标记有答案,一部分没有。
通常就是先使用无监督学习来对于数据进行处理,之后使用监督学习手段来进行训练。
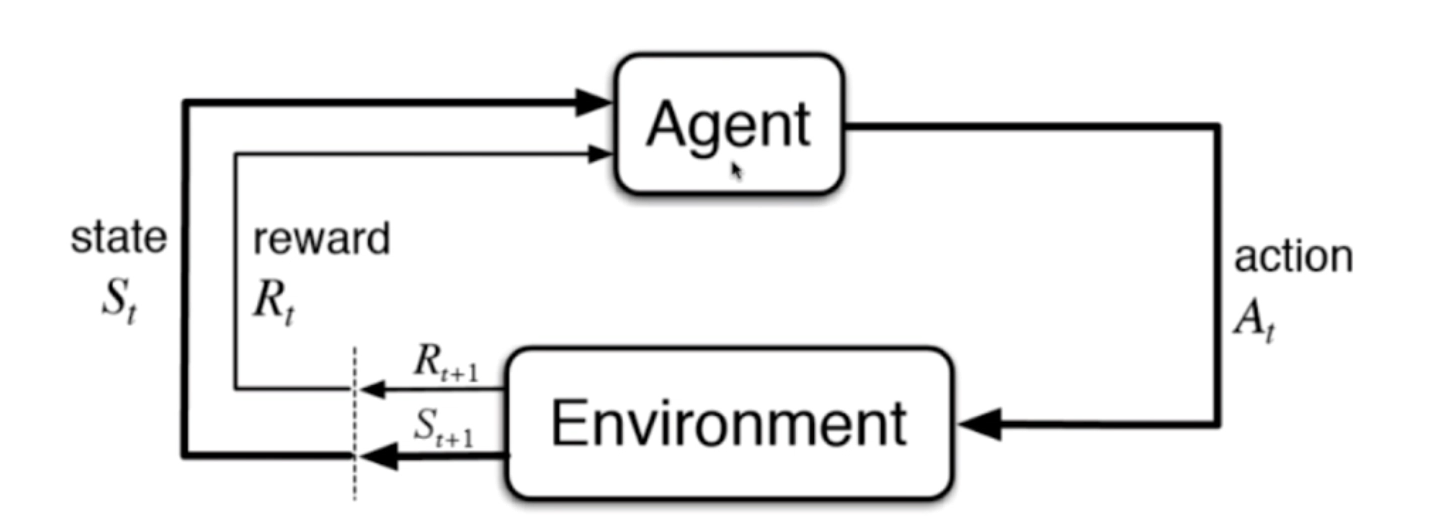
增强学习
根据环境反馈来采取行动,根据行动的结果,根据结果反馈来进行学习。
批量学习(离线学习)
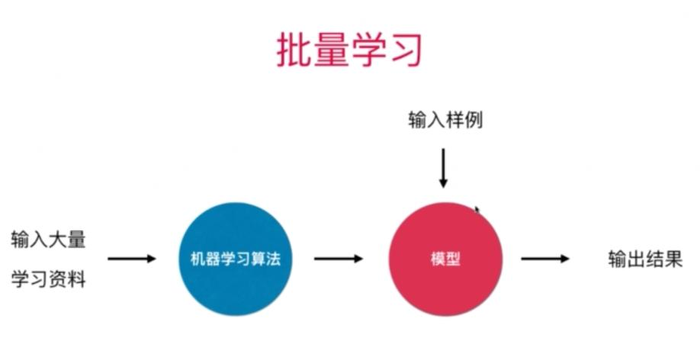
离线学习就是先训练系统,然后将其投入生产环境,这时学习过程停止,机器只是将其所学到的应用出来。
- 优点
- 简单
- 适合生产环境,训练完成之后可以直接投入生产。
- 缺点
- 系统无法进行增量学习
- 解决办法
- 定期进行批量学习,但是每次都使用完整的数据集进行训练会消耗大量的计算资源。
在线学习
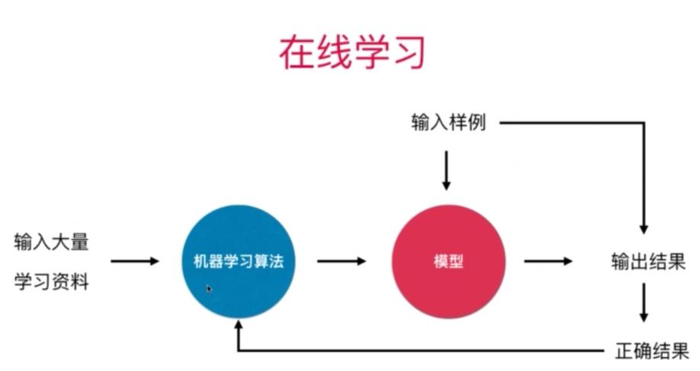
在在线学习系统中,我们可以循序渐进的给系统提供训练数据,逐步积累训练成果。这种提供数据的方式,可以是单独的,也可以采用小批量的小组数据来进行训练,所以系统可以快速的写入最新的数据进行学习。
- 优点
- 可以及时的反应新的环境变化
- 对于批量学习无法解决的大批量数据,可以使用在线学习小批量多批次解决。
- 缺点
- 新的数据可能会带来不好的变化
- 解决方案
- 加强对数据的监控(利用非监督学习检异常数据)
参数学习
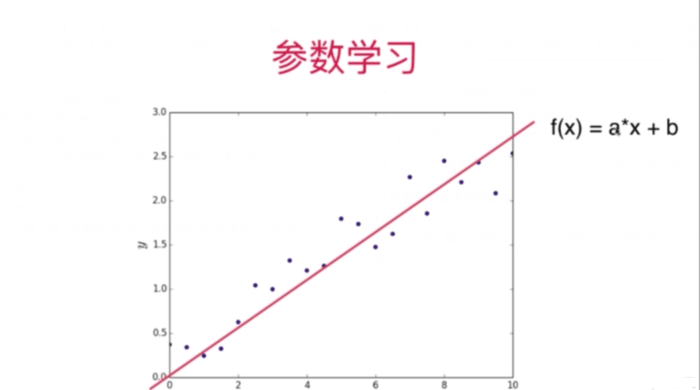
大量数据解出\(a\)和\(b\)的参数值,之后就不需要数据集来进行训练。
非参数学习
- 不对模型进行过多的假设
- 非参数也可能会有参数