- 超参数:在算法运行前需要决定的参数
- 模型参数:算法过程中学习的参数
KNN算法没有模型参数,里面的\(k\)是典型的超参数
KNN的超参数
超参数_\(k\)
\(tips\):
- 若是所搜结果为边界则应该拓宽边界继续搜索
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
digits = datasets.load_digits()
x = digits.data
y = digits.target
x1, x2, y1, y2 = train_test_split(x, y)
best_score = 0.0
best_k = -1
for k in range(1, 100):
clf = KNeighborsClassifier(k)
clf.fit(x1, y1)
score = clf.score(x2, y2)
# print(score)
if score > best_score:
best_k = k
best_score = score
print(best_k, best_score)
超参数_权重\(weight\)
将距离的倒数作为权重,当分为\(k\)类,可能会出现平票的现象,使用权重可以有效避免。
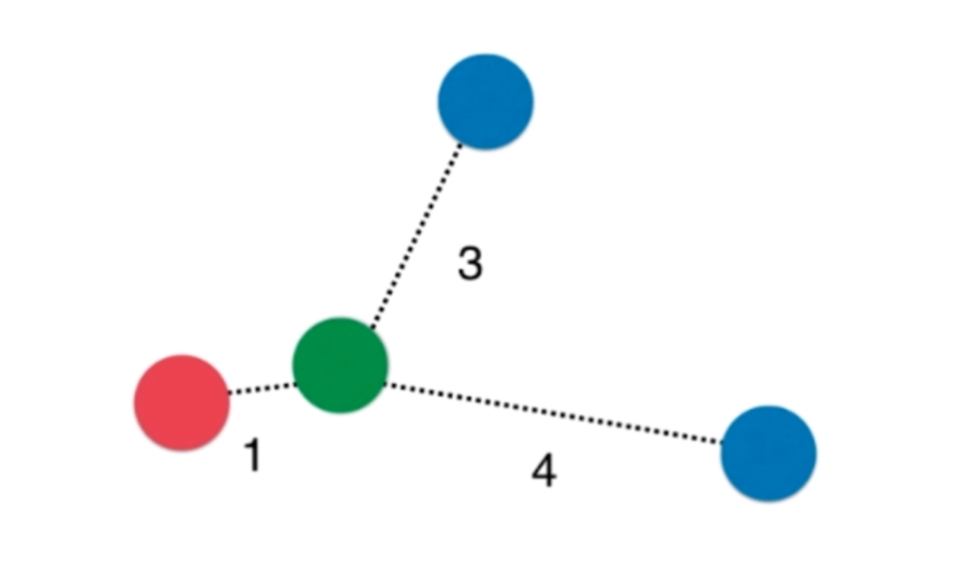
如图所示
\[\color{red}{red} = 1
\]
\]
\[ \color{blue}{blue} = \frac{7}{12}= \frac{1}{3} + \frac{1}{4}
\]
\]
这样的情况下红色胜出
\(weights\)的参数
- \(uniform\): 不考虑权重
- \(distance\): 距离的倒数的和作为权重
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
digits = datasets.load_digits()
x = digits.data
y = digits.target
x1, x2, y1, y2 = train_test_split(x, y)
best_score = 0.0
best_k = -1
best_method = ""
for method in ["uniform", "distance"]:
for k in range(1, 20):
clf = KNeighborsClassifier(k, weights=method)
clf.fit(x1, y1)
score = clf.score(x2, y2)
# print(score)
if score > best_score:
best_k = k
best_score = score
best_method = method
print(best_k, best_score,best_method)
超参数_\(p\)
明可夫斯基距离对应的\(p\)
\[(\sum_{i=1}^{n} |x_{(i)}^{(a)} - x_{(i)}^{(b)}|^{p})^{(\frac{1}{p})}
\]
\]
#将前面几个综合起来了
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
digits = datasets.load_digits()
x = digits.data
y = digits.target
x1, x2, y1, y2 = train_test_split(x, y)
best_score = 0.0
best_k = -1
best_method = ""
best_p = -1
for method in ["uniform", "distance"]:
for k in range(1, 20):
for p in range(1, 6):
clf = KNeighborsClassifier(k, weights=method, p=p)
clf.fit(x1, y1)
score = clf.score(x2, y2)
if score > best_score:
best_k = k
best_score = score
best_method = method
best_p = p
print(best_k, best_score, best_method, best_p)
#输出结果
1 0.9955555555555555 uniform 4
网格搜索
直接使用\(sklearn\)里面的内置函数来进行测试
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
digits = datasets.load_digits()
x = digits.data
y = digits.target
x1, x2, y1, y2 = train_test_split(x, y)
param_grid = [
{
'weights': ['uniform'],
'n_neighbors': [i for i in range(1,11)]
},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 11)],
'p': [i for i in range(1, 6)]
}
]
clf = KNeighborsClassifier()
# 可选 n_jobs 调用多少核去计算, verbose 计算的时候展示信息
grid_search = GridSearchCV(clf, param_grid, n_jobs=-1, verbose=2)
grid_search.fit(x1, y1)
print(grid_search.best_score_)
print(grid_search.best_params_)
print(grid_search.best_estimator_)
# 测试结果
# 过程的一部分
[CV] END ..............n_neighbors=10, p=4, weights=distance; total time= 0.3s
[CV] END ..............n_neighbors=10, p=4, weights=distance; total time= 0.3s
[CV] END ..............n_neighbors=10, p=4, weights=distance; total time= 0.3s
[CV] END ..............n_neighbors=10, p=5, weights=distance; total time= 0.3s
[CV] END ..............n_neighbors=10, p=5, weights=distance; total time= 0.3s
[CV] END ..............n_neighbors=10, p=5, weights=distance; total time= 0.3s
[CV] END ..............n_neighbors=10, p=5, weights=distance; total time= 0.3s
[CV] END ..............n_neighbors=10, p=5, weights=distance; total time= 0.3s
0.989607600165221
{'n_neighbors': 1, 'weights': 'uniform'}
KNeighborsClassifier(n_neighbors=1)