Hadoop完全分布式集群安装
使用版本: hadoop-3.2.0
安装VMware
看一下这张图,图里面表示是三个节点,左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。
不同节点上面启动的进程默认是不一样的。
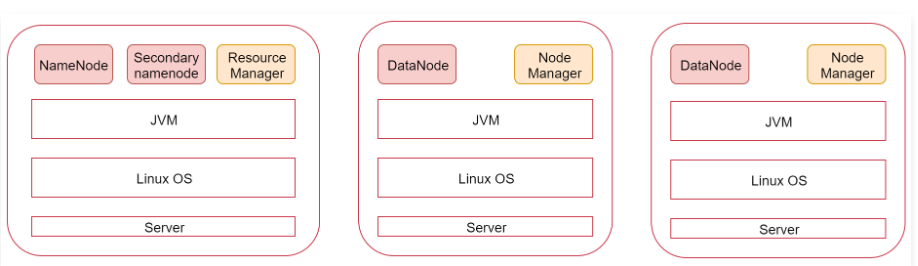
下面我们就根据图中的规划实现一个一主两从的hadoop集群
安装hadoop
三个节点
bigdata01 192.168.182.100
bigdata02 192.168.182.101
bigdata03 192.168.182.102
环境准备
ip:
设置静态ip
[root@bigdata01 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
首先修改BOOTPROTO参数,将之前的dhcp改为static
BOOTPROTO="static"
然后在文件末尾增加三行内容【注意,我现在使用的是nat网络模式,不同的网络模式在这里填写的ip信息是不一样的】
IPADDR=192.168.182.100
GATEWAY=192.168.182.2
DNS1=192.168.182.2
注意三台主机都需要修改,除了IPADDR的端口(第四位)不一样外,其他的信息都一样
hostname
[root@bigdata01 ~]# hostname bigdata01
[root@bigdata01 ~]# vi /etc/hostname
bigdata01
其他两台节点上分别修改主机名为bigdata02、bigdata03
firewalld
关闭并停止防火墙服务
[root@bigdata01 ~]# systemctl stop firewalld
[root@bigdata01 ~]# systemctl disable firewalld
其他两台节点执行相同操作
配置/etc/hosts
节点间默认情况下只能使用ip远程访问,想要使用主机名远程访问的话需要在节点的/etc/hosts文件中配置对应机器的ip和主机名信息。
在bigdata01节点上添加三个节点的ip和主机名信息,并拷贝给bigdata02、bigdata03
[root@bigdata01 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
[root@bigdata01 ~]#scp /etc/hosts bigdata02:/etc/hosts
[root@bigdata01 ~]#scp /etc/hosts bigdata03:/etc/hosts
ssh免密登录
ssh的加密方式为非对称加密,要实现A远程登录B,步骤如下:
首先A要把他的公钥发给B
当A和B建立通信时,会发给B一个字符串
B用公钥对字符串加密
A同时将用私钥加密后的字符串发送给B
B对比两份加密内容如果匹配就允许A登录
首先在bigdata01上执行 ssh-keygen -t rsa,采用rsa加密算法生成密钥,连按4次回车后完成
[root@bigdata01 ~]# ssh-keygen -t rsa
执行以后会在~/.ssh目录下生产对应的公钥和私钥文件,.pub结尾的就是公钥
[root@bigdata01 ~]# ll ~/.ssh/
total 12
-rw-------. 1 root root 1679 Apr 7 16:39 id_rsa
-rw-r--r--. 1 root root 396 Apr 7 16:39 id_rsa.pub
需要加密的公钥默认放入~/.ssh/authorized_keys文件中才能被识别
加入自己的公钥,允许自己登录自己
[root@bigdata01 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
执行下面命令,将公钥信息拷贝到两个从节点
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata02:~/
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata03:~/
将bigdata01的公钥加入到bigdata02、bigdata03中
[root@bigdata02 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
`[root@bigdata03 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
验证一下效果
[root@bigdata01 ~]# ssh bigdata02
Last login: Tue Apr 7 21:33:58 2020 from bigdata01
[root@bigdata02 ~]# exit
logout
Connection to bigdata02 closed.
[root@bigdata01 ~]# ssh bigdata03
Last login: Tue Apr 7 21:17:30 2020 from 192.168.182.1
[root@bigdata03 ~]# exit
logout
Connection to bigdata03 closed.
[root@bigdata01 ~]#
JDK配置
集群间时间同步
集群只要涉及到多个节点的就需要对这些节点做时间同步
首先在bigdata01节点上操作
使用ntpdate -u ntp.sjtu.edu.cn实现时间同步,但是执行的时候提示找不到ntpdata命令
默认是没有ntpdate命令的,需要使用yum在线安装,执行命令 yum install -y ntpdate
[root@bigdata01 ~]# yum install -y ntpdate
然后手动执行ntpdate -u ntp.sjtu.edu.cn 确认是否可以正常执行
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn
7 Apr 21:21:01 ntpdate[5447]: step time server 185.255.55.20 offset 6.252298 sec
建议把这个同步时间的操作添加到linux的crontab定时器中,每分钟执行一次
[root@bigdata01 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn