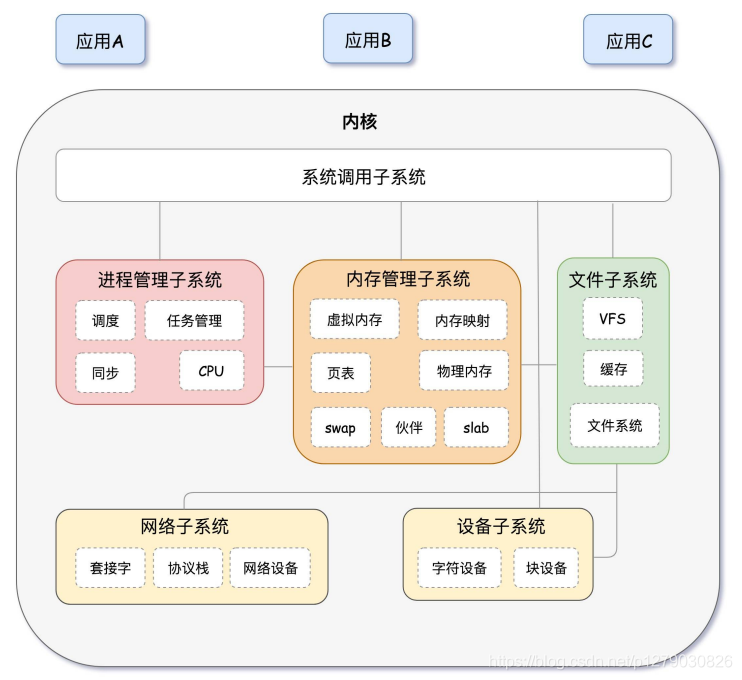
一、矩阵的范数




二、矩阵的谱半径

虽然,谱半径小于等于任意矩阵范数。
但是,也必存在一个算子范数,小于等于谱半径+一个小的正数
从线性方程组的迭代法的收敛性到矩阵的幂的收敛。



谱半径小于1,也必存在一个算子范数,小于1;
若矩阵的范数小于1, 当k趋于无穷时,矩阵任意范数的k次幂肯定趋近于0,这就使x(k)逼近其解。也就是说,矩阵的幂趋近于0矩阵。
三、深度神经网络的梯度消失
在训练深层的神经网络时,例如MLP或RNN,由于反向传播的链路过长,从而涉及到多次的矩阵的连乘(激活函数关于净输入的偏导数矩阵、当前层输入关于净输入的偏导数矩阵,可以视为一个矩阵)。
如果这个矩阵的谱半径小于一,那么随着反向传播的进行,回传的梯度信号衰减地越厉害,这使得越是网络浅层的参数地梯度越微弱,那么其越难得到很好地更新。
参考: 数值分析ppt