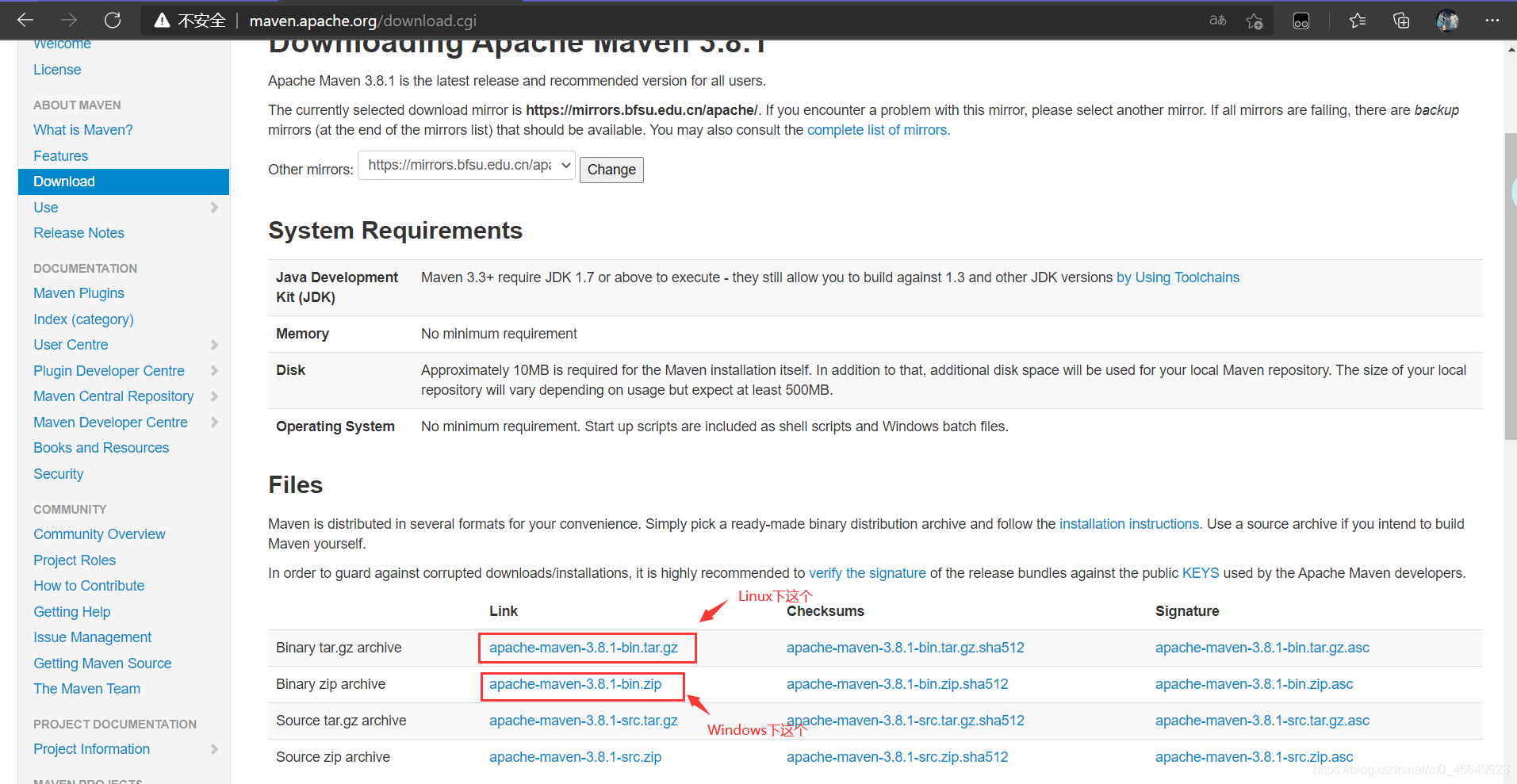
逻辑回归
在线性回归中,我们预测的目标变量取值范围比较广泛,但是在有些问题中,想要预测的结果可能只有两种。例如,我们想要判断一封电子邮件是否为垃圾邮件,又或者是想要预测一场体育比赛是否能取胜。诸如此类问题,我们称之为二分类问题。对于这种类型的问题,如果采用线性回归预测,通常结果是不准确的,特别是在数据集不那么集中的情况下,拟合的曲线可能把分散的样本划分到错误的分类中,如下图。采用逻辑回归模型,会非常好的解决二分类问题。
一、模型
由于在二分类问题中结果只有两种,“是”和“否”,或者“0”和“1”。输出小于0.5的归类到“0”,输出大于0.5的归类到“1”。为此,我们引入Sigmoid函数,这种曲线可以更好的拟合数据集。
那么逻辑回归怎么使用的呢?
我们可以这样理解,逻辑回归的输出其实是目标变量为“1”的概率,概率小于0.5我们就认为目标输出是“0”,概率大于或等于0.5我们就认为目标输出是“1”。
二、决策边界
在Sigmoid函数的图形中,可以观察到,当z大于或等于0的时候 g(z) 大于0.5,也就是预测结果为“1”;当z小于0的时候 g(z) 小于0.5,也就是预测结果为“0”。
由上式可得,w · x + b >= 0 预测为 ”1“ ;w · x + b < 0 预测为 ”0“。z就称之为决策边界。以下是一个非线性的决策边界示例。
通过多项式,逻辑回归可以拟合非常复杂的数据,得到非常复杂的决策边界,而不仅仅是一个少量特征的直线。
三、训练模型
1、代价函数
在线性回归模型中,我们选择使用平方误差代价函数来训练模型,但是这种成本函数在逻辑回归模型中行不通,因为在逻辑回归模型中成本函数存在很多的局部极小点,如下图。
我们定义一个单样本损失,称为L
使用新的损失函数
当真实结果为1时,L的图像如下。由于f是逻辑回归的输出,也就是预测值,是处于0-1之间的,所以只看红色框区域。当真实结果为1,而预测为1时,损失几乎为0。预测值越偏离1而靠近0,损失就越大,靠近0时损失无限大。
当真实结果为0时,L的图像如下。当真实结果为0,而预测结果为0时,损失几乎为0。预测值越偏离0而靠近1,损失就越来越大,靠近1时损失无限大。
使用这样的损失函数可以很好地训练模型,当预测值越接近真实值,就会得到奖赏,损失会越小;当预测值越偏离真实值,就会得到惩罚,损失会越来越大,甚至趋于无穷大。
为什么我们有那么多的代价函数却非要使用这个呢?因为这个特殊的代价函数是从一种叫做极大似然估计的统计原理中推导出来的,它是统计学中关于如何有效的找到不同模型的参数的一种思想,
2、简化的逻辑回归代价函数
由于y只能取0或1,所以我们可以简化代价函数,方便实现。下面的式子与上面未简化的是完全等价的。
3、梯度下降
虽然逻辑回归梯度下降算法的更新表达式和线性回归的看起来一样,但实际上由于假设函数的不同,两者是非常不一样的。
4、向量化与特征缩放
逻辑回归的向量化与特征缩放都是类似的,详细可参考之间的文章。
四、欠拟合问题
当模型对数据集的拟合不足时,我们称之为欠拟合;当模型对数据集过度拟合,而失去了泛化能力,不能推广运用到新的不在训练集中的样本,称之为过拟合问题。
例如,线性回归
逻辑回归
如何解决过拟合问题呢?
以下有三种方法:
一、搜集更多的数据;
二、减少特征数量,选择使用比较合适的特征;
三、正则化;(推荐)
五、正则化
当模型存在过拟合问题,而我们不想抛弃某些特征,因为或许他对预测是有用信息时,可以选择使用正则化。通常,如果模型的特征较多,且某些特征的权重较大,那么就很容易产生过拟合问题。使用正则化可以缩小特征的权重,也就是缩小参数,这样就可以是模型很好的拟合而不至于过拟合。
线性回归正则化
下图是正则化线性回归代价函数表达式
我们都知道,缩小代价函数可以使模型更好的拟合。正则化就是在代价函数中添加正则项,“惩罚”所有特征参数,防止过大。当我们缩小代价函数时,特征参数也会随之缩小。
那为什么缩小代价函数,特征参数也会随之缩小呢?我们在代价函数中添加正则项以后,在梯度下降时,w的更新每次会多减少一些。如下图
正则项系数lambda的选择也是很重要的。当它过小时,例如接近于0,相当于未进行正则化,那么此时模型的特征较多且参数较大,很容易发生过拟合问题;当它过大时,对“参数”的惩罚力度过大,例如使所有参数接近为0,那么此时模型f约等于b,变成了一条直线,此时就产生了欠拟合问题。
逻辑回归正则化
逻辑回归正则化代价函数表达式
六、实现
部分数据及代码
34.62365962451697,78.0246928153624,0
30.28671076822607,43.89499752400101,0
35.84740876993872,72.90219802708364,0
60.18259938620976,86.30855209546826,1
79.0327360507101,75.3443764369103,1
45.08327747668339,56.3163717815305,0
61.10666453684766,96.51142588489624,1
75.02474556738889,46.55401354116538,1
76.09878670226257,87.42056971926803,1
84.43281996120035,43.53339331072109,1
95.86155507093572,38.22527805795094,0
75.01365838958247,30.60326323428011,0
82.30705337399482,76.48196330235604,1
69.36458875970939,97.71869196188608,1
39.53833914367223,76.03681085115882,0
53.9710521485623,89.20735013750205,1
69.07014406283025,52.74046973016765,1
67.94685547711617,46.67857410673128,0
70.66150955499435,92.92713789364831,1
"""
在本部分练习中,你将建立一个逻辑回归模型,以预测学生是否被大学录取假设你是大学部门的管理员,并且您想根据每位申请人的两次考试成绩来确定他们的录取机会。您具有以前申请人的历史数据,可以用作逻辑回归的训练集。对于每个训练示例,您都有两次考试的申请人分数和入学决定。
您的任务是建立一个分类模型,根据这两次考试的分数来估算申请人的录取概率。
"""
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.optimize as opt
from sklearn.metrics import classification_report # 这个包是评价报告
#导入数据
path = './data/ex2data1.txt'
data = pd.read_csv(path, names=['exam1', 'exam2', 'admitted']) # exam1:成绩1 exam2:成绩2 admitted: 录取率
data.head()
# 绘制训练集散点图
sns.lmplot(x='exam1', y='exam2', hue='admitted', data=data,
height=6,
fit_reg=False,
scatter_kws={"s": 50}
)
plt.show()
# 函数部分
def get_X(df):
"""获取特征集"""
# 创建1列“1”,命名为“ones”
ones = pd.DataFrame({'ones': np.ones(len(df))})
# 把ones这一列和data合并
data = pd.concat([ones, df], axis=1) # 根据列合并。参数axis:要合并的轴,0是行,1是列
# 提取第一至倒数第二列所有数
value = data.iloc[:, :-1].values
return value # 返回的ndarray格式
def get_y(df):
"""获取输出"""
# 提取出最后一列,转换成numpy的形式
value = np.array(df.iloc[:, -1])
return value
def normalize_feature(df):
"""特征缩放"""
value = df.apply(lambda column: (column - column.mean()) / column.std()) # 零均值标准化
return value
def sigmoid(z):
"""逻辑回归模型的假设函数"""
return 1 / (1 + np.exp(-z)) # g(z)=1/( 1+e**(-z) )
def cost(theta, X, y):
"""逻辑回归代价函数"""
return np.mean(-y * np.log(sigmoid(X @ theta)) - (1 - y) * np.log(1 - sigmoid(X @ theta)))
def gradient(theta, X, y):
"""梯度下降"""
return (1 / len(X)) * X.T @ (sigmoid(X @ theta) - y)
def predict(x, theta):
"""用训练集预测和验证"""
h = sigmoid(x @ theta)
return (h >= 0.5).astype(int)
# 获取数据
X = get_X(data) # 100x3
y = get_y(data) # 100x1
# theta是特征参数,初始化为[0 0 0]
theta = np.zeros(3) # 3x1
print("未训练时的的损失值:", cost(theta, X, y))
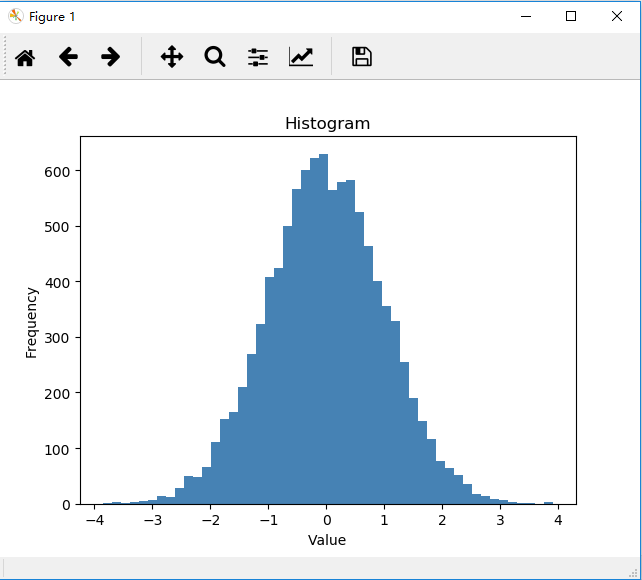
# 绘制sigmoid函数图像
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(np.arange(-10, 10, step=0.01), sigmoid(np.arange(-10, 10, step=0.01)))
ax.set_ylim((-0.1, 1.1))
ax.set_xlabel('z', fontsize=18)
ax.set_ylabel('g(z)', fontsize=18)
ax.set_title('sigmoid funcion', fontsize=18)
plt.show()
# 使用scipy.optimize.minimize去寻找最优参数
res = opt.minimize(fun=cost, x0=theta, args=(X, y), method='Newton-CG', jac=gradient)
final_theta = res.x
y_pred = predict(X, final_theta)
# 打印评价报告
print("评价报告:",classification_report(y, y_pred))
# 寻找决策边界
# theta存放的是[b w1 w2]
# z = theta_0 + theta_1 * x1 + theta_2 * x2
# 决策边界,令z = 0
# theta_0 + theta_1 * x1 + theta_2 * x2 = 0
# 在数据集上,横轴是exam1,纵轴是exam2
# x2 = -(theta_0 / theta2) -(theta_1 / theta_2) * x1
# 得到直线的系数
coef = -(res.x / res.x[2])
# 根据直线的参数即可绘制直线
x = np.arange(130, step=0.1)
y = coef[0] + coef[1] * x
# 绘制数据集散点图
sns.set(context="notebook", style="ticks", font_scale=1.5)
sns.lmplot(x='exam1', y='exam2', hue='admitted', data=data, height=6, fit_reg=False, scatter_kws={"s": 25})
# 绘制决策边界
plt.plot(x, y, 'grey')
plt.xlim(0, 130)
plt.ylim(0, 130)
plt.title('Decision Boundary')
plt.show()