协程栈
go 栈的位置
1. Go 协程栈位于 Go-堆内存上
2. Go 堆内存位于操作系统虚拟内存上
go 栈的工作流程

以main.main为出发点
- 要记录runtime.main的栈基地址
- 记录 a 和 b的局部变量值
- 开辟一个空间记录 sum函数的返回值
- 记录 b 和 a的值, 这里是为了方便 sum在执行时候,去找这个传入的参数
- 记录 sum返回后,要执行的指令,就是 print的执行位置.
这里面能有一个重要体现, a 和 b 的值被复制了一份, 一般称为拷贝传递或值传递
传递结构体时:会拷贝结构体中的全部内容.
传递结构体指针时:会拷贝结构体指针
小结 协程栈记录的内容:
协程的执行路径
局部变量
函数传参
函数返回值
问题: 如果协程栈的空间不够大了, 该怎么处理?
本地变量太大:比如有个变量 map 存了特别多的数据.
栈帧太多 :比如 函数a调用函数b, 一层层套,过多了.
栈空间不足
本地变量太大 使用逃逸分析
栈帧太多 使用 栈扩容
逃逸分析
针对变量太大, go的解决办法 在编译阶段进行逃逸分析. 不是所有的变量都能放在协程栈上
需要逃逸的变量:
栈帧回收后,需要继续使用的变量
太大的变量
指针逃逸
好理解, 函数a返回一个局部变量 b的地址给 函数A,
这种情况在很多语言中是会出问题的,返回了一个局部变量地址, 使用时候会发生无法预料的结果.
但是go会做逃逸分析, 会把这个变量放到堆上去.
空接口逃逸
如果函数参数为 interfacef, 函数的实参很可能会逃逸,例如 fmt包中的打印.
因为 interfacef类型的函数往往会使用反射
大变量逃逸
过大的变量会导致栈空间不足
64 位机器中,一般超过 64KB 的变量会逃逸
栈扩容
Go 栈的初始空间为 2KB
在函数调用前判断栈空间(morestack) , 这个方法在讲 切换协程时候, 这个方法也是一个时机
必要时对栈进行扩容
早期使用分段栈,后期使用连续栈
分段栈

每调用一个函数, 就跳转到一块写的栈空间.
连续栈
优点:空间一直连续
缺点:伸缩时的开销大
当空间不足时扩容,变为原来的2倍
当空间使用率不足 1/4 时缩容,变为原来的 1/2
协程栈的工作流程大致如上, 但是, 不管是栈还是堆上, 这些 内存是如何管理, 如何分配给申请的变量的 ?
go 内存管理
操作系统的虚拟内存
不是Win 的"虚拟内存〞, 不是指 操作系统将 硬盘的一块空间 当做虚拟内存使用.
操作系统给应用提供的虚拟内存空间
背后是物理内存,也有可能有磁盘
Linux 获取虚拟内存:mmap 或 madvice
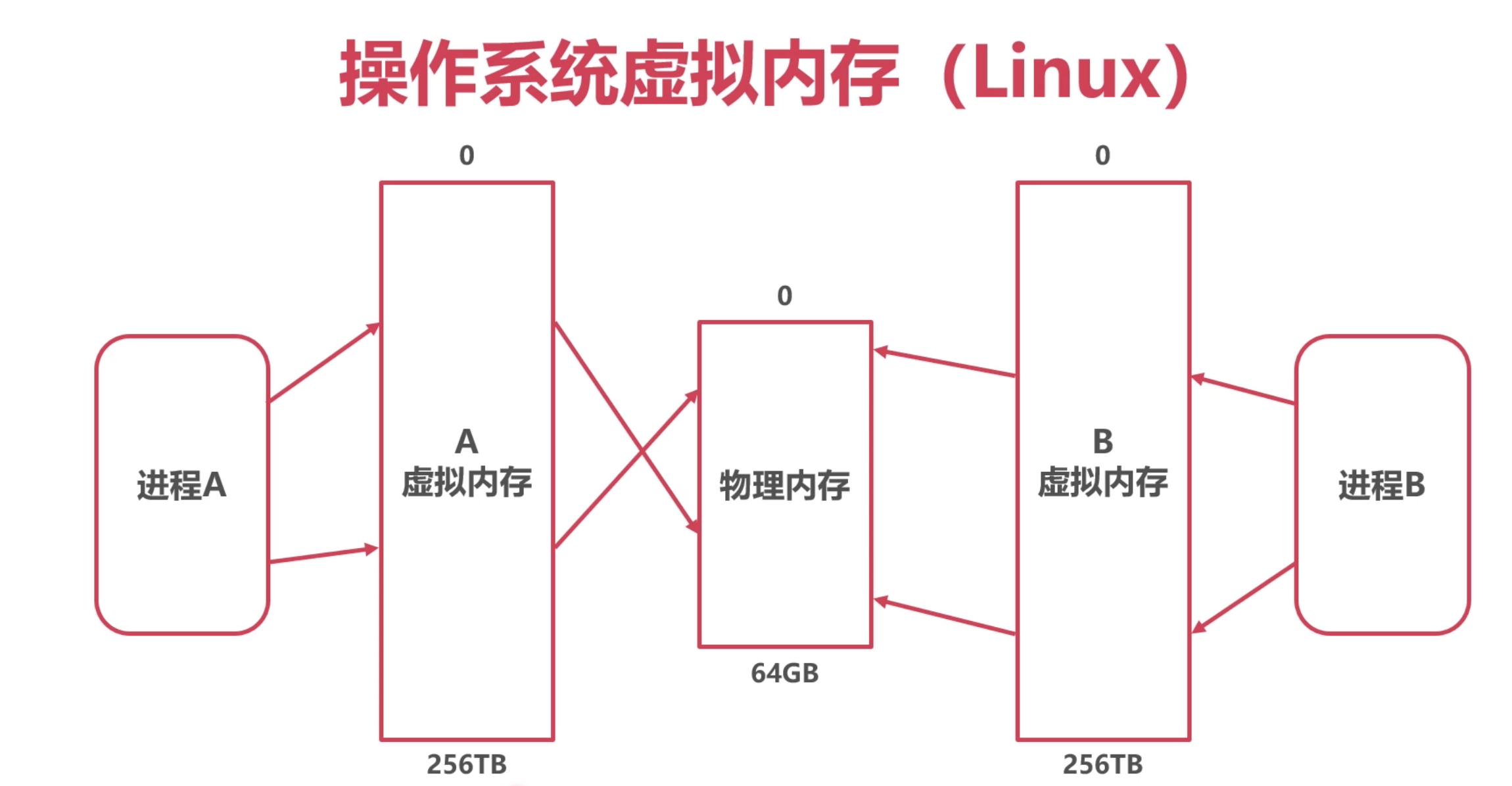
假设机器的物理内存只有64G, 但是通过操作系统的虚拟内存扩大, 所有的进程都会以为拥有了一
块特别大的空间, 256T, 但是不能真正用到这么多, 一旦用太多就会被系统干掉. Linux中的OOM.
这块是操作系统的事, go 只能合理使用操作系统给进程的内存.
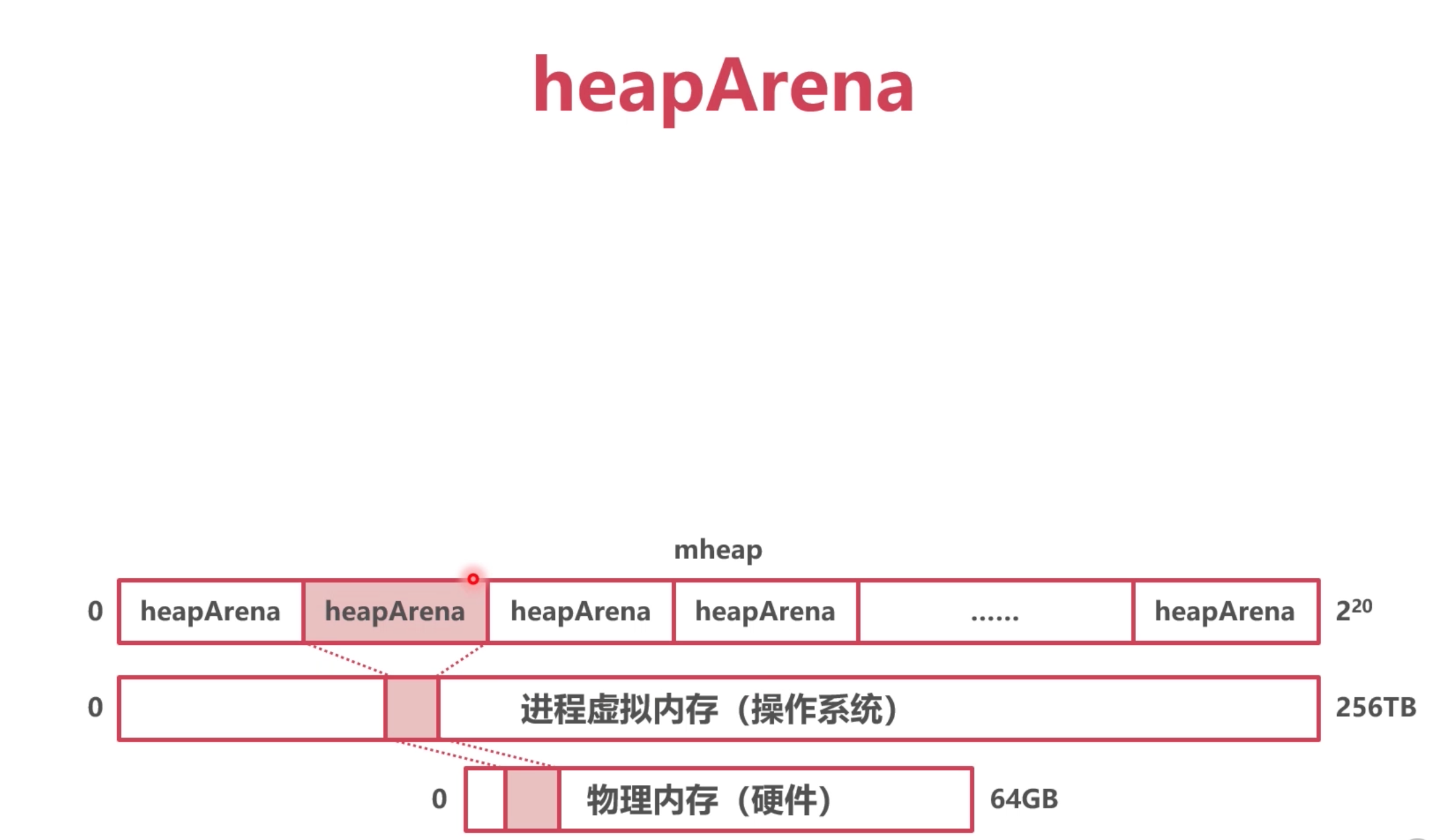
heapArena
Go 每次申请的虚拟内存单元为 64MB , 就是 heapArena, 如果每次拿的太小, 会多次去申请, 影响效率.
最多有4,194,304 个虛拟内存单元 (2的20次方) 刚好256T
所有的 heapArena 组成了mheap(Go 堆内存)
抽象出了两个概念 :
整个go的堆内存 mheap , 包含了很多 heapArena
代码定义:
// 代表着 整个go的内存空间
type mheap struct {
_ sys.NotInHeap
lock mutex
pages pageAlloc // page allocation data structure
sweepgen uint32
allspans []*mspan // all spans out there
pagesInUse atomic.Uintptr // pages of spans in stats mSpanInUse
pagesSwept atomic.Uint64 // pages swept this cycle
pagesSweptBasis atomic.Uint64 // pagesSwept to use as the origin of the sweep ratio
sweepHeapLiveBasis uint64 // value of gcController.heapLive to use as the origin of sweep ratio; written with lock, read without
sweepPagesPerByte float64 // proportional sweep ratio; written with lock, read without
reclaimIndex atomic.Uint64
reclaimCredit atomic.Uintptr
// 包含 最多 2的20次方个 heapArena
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
arenasHugePages bool
heapArenaAlloc linearAlloc
arenaHints *arenaHint
arena linearAlloc
allArenas []arenaIdx
sweepArenas []arenaIdx
markArenas []arenaIdx
curArena struct {
base, end uintptr
}
central [numSpanClasses]struct {
mcentral mcentral
pad [(cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte
}
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
specialprofilealloc fixalloc // allocator for specialprofile*
specialReachableAlloc fixalloc // allocator for specialReachable
specialPinCounterAlloc fixalloc // allocator for specialPinCounter
speciallock mutex // lock for special record allocators.
arenaHintAlloc fixalloc // allocator for arenaHints
// User arena state.
// Protected by mheap_.lock.
userArena struct {
arenaHints *arenaHint
quarantineList mSpanList
readyList mSpanList
}
unused *specialfinalizer // never set, just here to force the specialfinalizer type into DWARF
}
// 代表64M的内存空间
type heapArena struct {
_ sys.NotInHeap
bitmap [heapArenaBitmapWords]uintptr
noMorePtrs [heapArenaBitmapWords / 8]uint8
spans [pagesPerArena]*mspan // mspan 下面会出现
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
pageSpecials [pagesPerArena / 8]uint8
checkmarks *checkmarksMap
zeroedBase uintptr
}
heapArena 分配方式
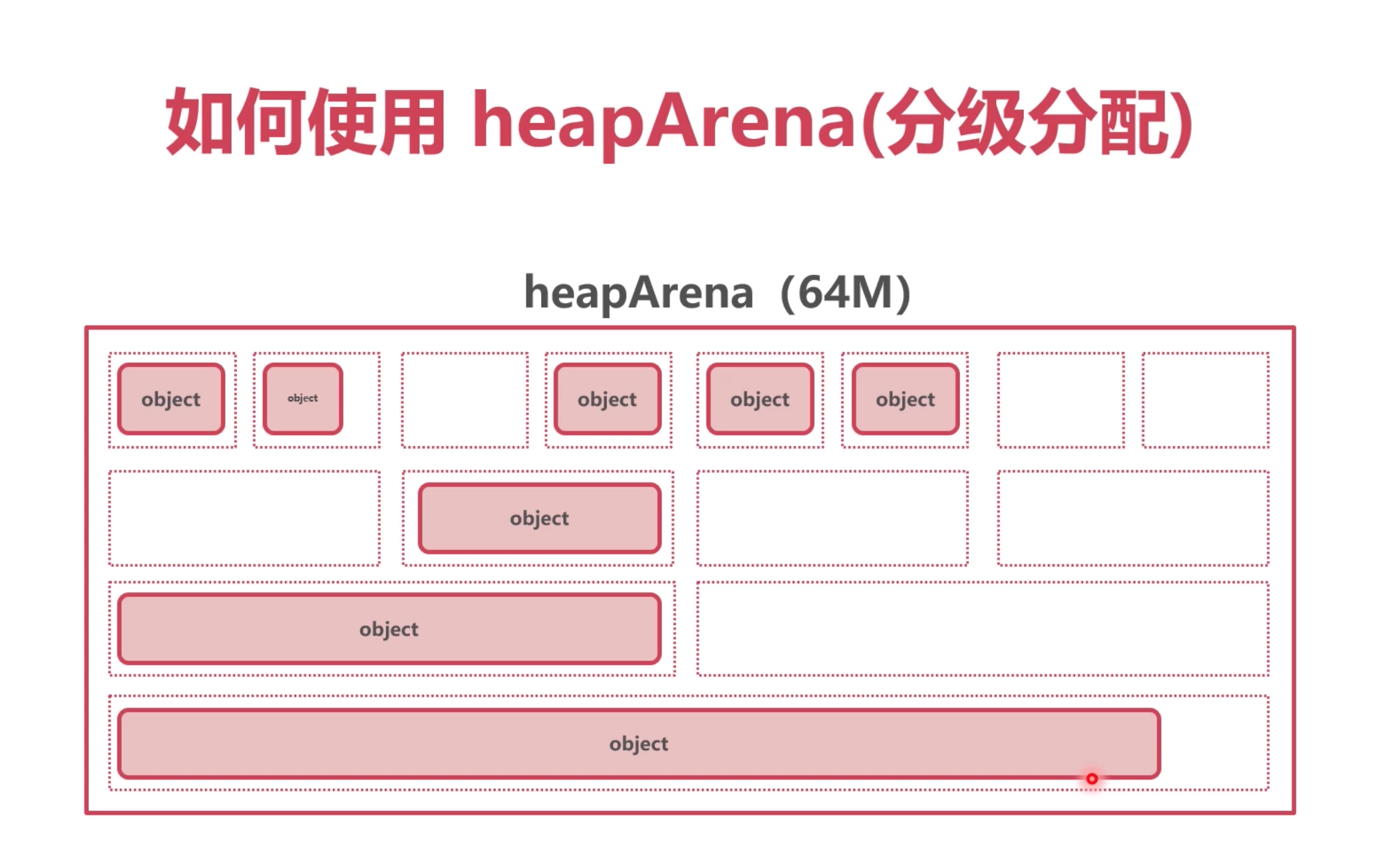
为了更好的管理这些申请的内存空间, heapArena会把这些空间 分成 大小不一的内存块,进行管理. 一共 67种. 这些同级别的 一组内存块就是
mspan大小8k.
因此,go里面一共有 67种 mspan.
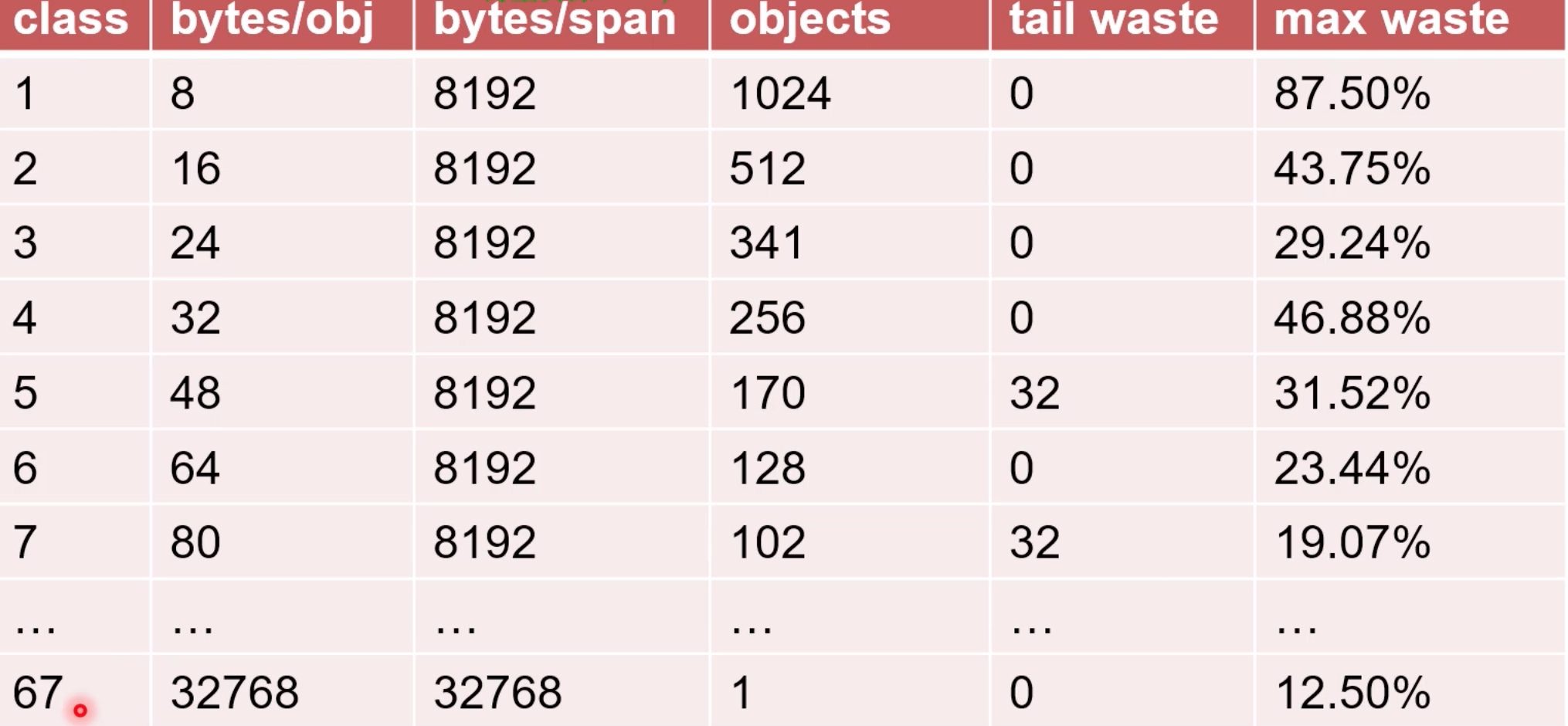
每组 都是 8K, 因为 单个的大小不同,所以 分配的个数也不同.
所以, 协程在申请空间时候, 分配的是mspan中的一个对象, 一个对象代表着一个级别的内存大小,比如1级的8个字节的空间
申请完64M的空间后,也不是马上把给个级别都分配一次,而是按需分配,比如现在需要1级的,那就只分配一组一级的, 可能最后这64M里面只有一级的
type mspan struct {
_ sys.NotInHeap
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
list *mSpanList // For debugging. TODO: Remove.
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
manualFreeList gclinkptr // list of free objects in mSpanManual spans
freeindex uintptr
nelems uintptr // number of object in the span.
allocCache uint64
allocBits *gcBits
gcmarkBits *gcBits
pinnerBits *gcBits // bitmap for pinned objects; accessed atomically
sweepgen uint32
divMul uint32 // for divide by elemsize
allocCount uint16 // number of allocated objects
spanclass spanClass // size class and noscan (uint8)
state mSpanStateBox // mSpanInUse etc; accessed atomically (get/set methods)
needzero uint8 // needs to be zeroed before allocation
isUserArenaChunk bool // whether or not this span represents a user arena
allocCountBeforeCache uint16 // a copy of allocCount that is stored just before this span is cached
elemsize uintptr // computed from sizeclass or from npages
limit uintptr // end of data in span
speciallock mutex // guards specials list and changes to pinnerBits
specials *special // linked list of special records sorted by offset.
userArenaChunkFree addrRange // interval for managing chunk allocation
freeIndexForScan uintptr
}
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
这两个字段说明,mspan 可以形成一个链表.
spanclass spanClass // 是pan的级别 1到67
这样的结构,导致一个问题, 很多不同级别的mspan在不同的 heapArena中, 当去协程去申请时候, 比如申请一个 一级的 span, 如何去寻找 ?
需要一个 索引管理 .
中心索引mcentral
136个
mcentral结构体,其中 68个组需要GC扫描的mspan, 68个组不需要GC扫描的mspan(例如存放一些常量)
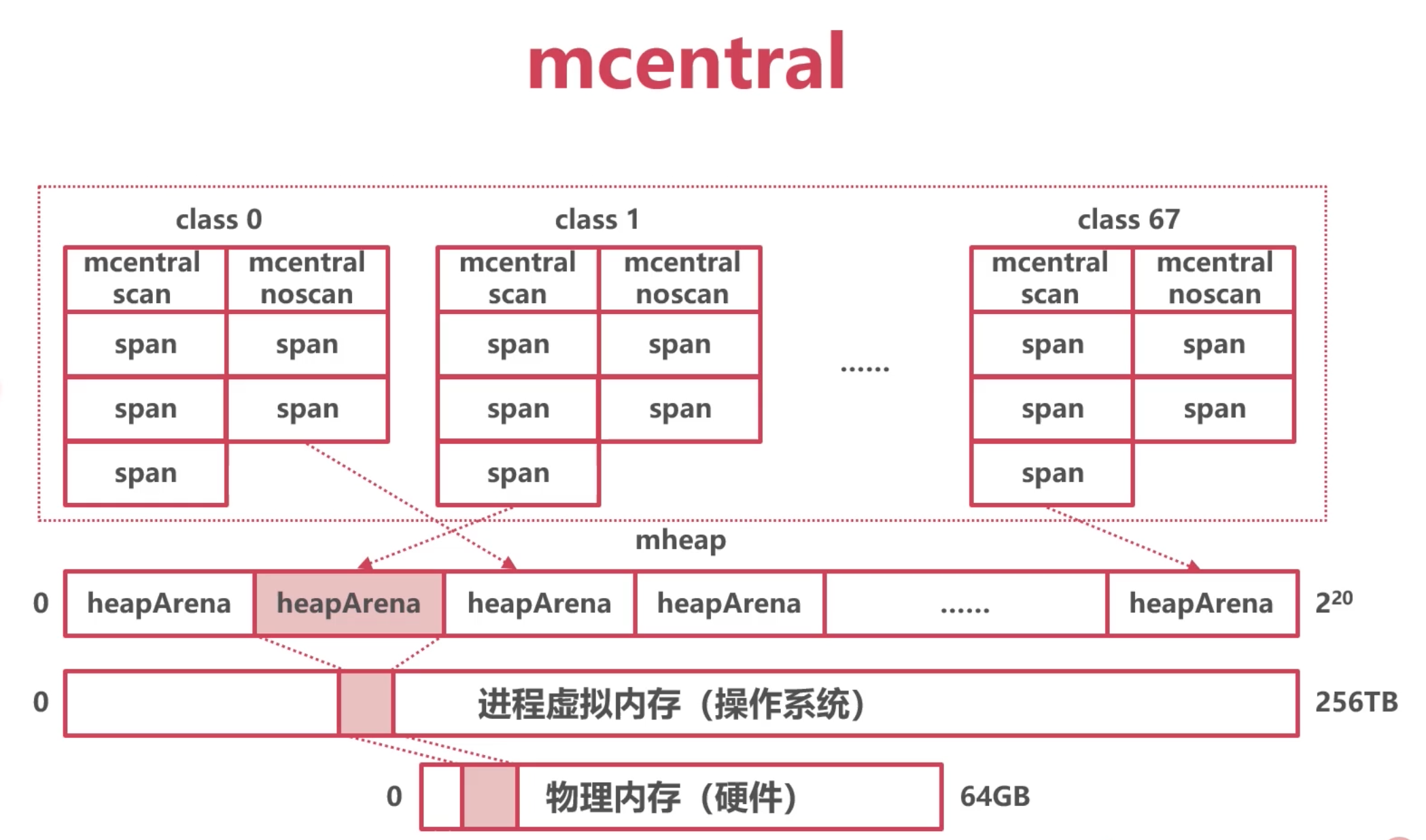
每一组对应一个级别的mspan, mspan本身是可以组成一个链表的 next和prev.
// Central list of free objects of a given size.
type mcentral struct {
_ sys.NotInHeap
spanclass spanClass // 一个具体的级别
partial [2]spanSet // list of spans with a free object 空闲的
full [2]spanSet // list of spans with no free objects 不空闲
}
mheap结构体定义的:
numSpanClasses = 136
central [numSpanClasses]struct {
mcentral mcentral
pad [(cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte
}
从mheap出发, 通过这个 central 这个元素 , 能找到所有的mspan
小结和问题:
mcentral实际是中心素引,使用互斥锁保护
在高并发场景下,锁冲突问题严重
参考协程GMP模型,增加线程本地缓存
线程缓存 mcache
模仿GMP的本地协程队列, 避免每次申请都去 mcentral中, 因为 要为了线程安全, mcentral 需要加锁, 导致有性能问题.
给每一个p增加一些 span的缓存,这样避免每次都去申请.
每个P拥有一个mcache,也就是每个M,每个线程;
一个mcache拥有136个mspan,其中68个需要GC扫描的mspan, 68个不需要GC扫描的mspan
一样来一个
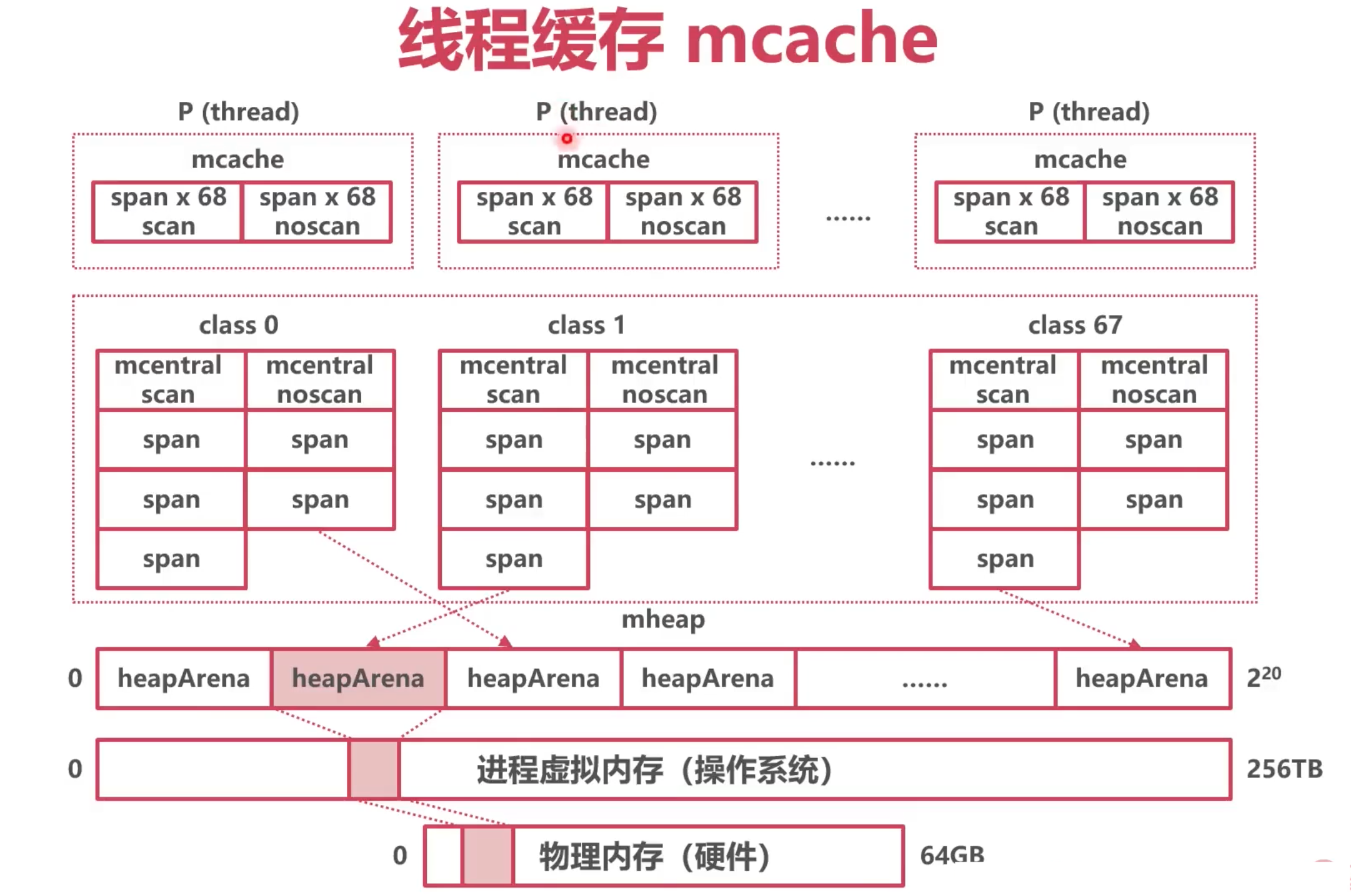
如何本地的span满了, 就需要去和mcentral中的span 进行交换, 如果mcentral中也没有可用的,就去申请,通过mheapArena申请一个64M的空间
代码定义:
numSpanClasses =136
type mcache struct {
_ sys.NotInHeap
// The following members are accessed on every malloc,
// so they are grouped here for better caching.
nextSample uintptr // trigger heap sample after allocating this many bytes
scanAlloc uintptr // bytes of scannable heap allocated
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
// 包含了136个span
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}
// 部分字段
type p struct {
id int32
m muintptr // back-link to associated m (nil if idle)
mcache *mcache //对应一个mcahe
}
小结:
Go模仿TCmalloc (C++使用,也是Google开发的),建立了自己的堆内存架构
使用heapArena向操作系统申请内存
使用heapArena时,以mspan为单位,防止碎片化
mcentral是mspan们的中心索引
mcache记录了分配给各个P的本地mspan
如何分配这些内存
对象分级
Tiny 微对象(0,16B) 无指针 如果是结构体, 成员不能包含指针
Small 小对象 [16B,32KB]
Large 大对象 (32KB, +∞)
使用
微小对象分配至普通 mspan, 32k以下
大对象量身定做 mspan, 这里值得是0级, 上面提到mspan有67级,
但是,在定义mcentral时候, 定了68个不需要GC的,还有一个是没有固定大小的级别, 0级.
微对象分配
- 从mcache 拿到2级mspan
- 将多个微对象合并成一个16Byte 存入

大对象分配
直接从heapArena开辟0级的mspan
0级的mspan为大对象定制
在runtime的 malloc.go中能体现:
// 分配内存的入口
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if size <= maxSmallSize {
// 微小对象分配
} else {
span = c.allocLarge(size, noscan)
}
}
// allocLarge allocates a span for a large object.
func (c *mcache) allocLarge(size uintptr, noscan bool) *mspan {
npages := size >> _PageShift
if size&_PageMask != 0 {
npages++
}
deductSweepCredit(npages*_PageSize, npages)
spc := makeSpanClass(0, noscan) // 0级 class
s := mheap_.alloc(npages, spc)
if s == nil {
throw("out of memory")
}
}
分配规则小结
Go将对象按照大小分为3种
微小对象使用mcache
mcache中的mspan填满后,与mcentral交换新的
mcentral不足时,在heapArena开辟新的mspan
大对象直接在heapArena开辟新的mspan









![原来你是这样的JAVA–[07]聊聊Integer和BigDecimal](https://img2024.cnblogs.com/blog/37001/202402/37001-20240224171021931-593439949.png)