百分比堆叠式柱状图是一种特殊的柱状图,它的每根柱子是等长的,总额为100%。
柱子内部被分割为多个部分,高度由该部分占总体的百分比决定。
百分比堆叠式柱状图不显示数据的“绝对数值”,而是显示“相对比例”。
但同时,它也仍然具有柱状图的固有功能,即“比较”——我们可以通过比较多个柱子的构成,分析数值之间的相对差异,或者得出数值变化的趋势。
1. 主要元素
百分比柱状图是一种用于可视化比较不同类别或组的百分比或比例的图表。
它的主要元素包括:
- 横轴:表示数据的主分类。
- 纵轴:每个子分类的比例关系。
- 堆叠的矩形:每个柱状图由多个堆叠部分组成,和堆叠柱状图不同的是,每个柱子都是一样高的。
- 图例:每个堆叠部分代表的意义。

2. 适用的场景
百分比柱状图适用的场景很多,比如:
- 市场份额:比较不同产品或服务的市场份额,帮助决策者了解市场竞争情况。
- 人口比例:显示不同地区或不同群体的人口比例,或不同年龄段的人口比例。
- 问卷调查结果:比较不同选项或答案的频率或比例,或者用户对产品特性的满意度。
- 部门预算分配:显示不同部门或项目的预算分配比例,帮助管理者了解资源分配情况。
- 等等。。。
3. 不适用的场景
百分比柱状图也有不适用于的场景,比如:
- 比较绝对数值:如果需要比较具体的数值大小而不仅仅是比例,那么百分比柱状图可能不是最合适的选择。
- 数据存在重叠:如果不同类别的数据存在重叠或者相互依赖的情况,百分比柱状图可能无法清晰地展示比例关系。
- 数据量过大或过小:如果数据量过大或过小,百分比柱状图可能无法有效地显示比例关系。
4. 分析实战
和上一篇堆叠柱状图使用相同的原始数据,绘制图形之后可以看看这两种柱状图展示分析结果的区别。
4.1. 数据来源
数据来自国家统计局公开的人民生活数据,可从下面的网址下载:
https://databook.top/nation/A0A
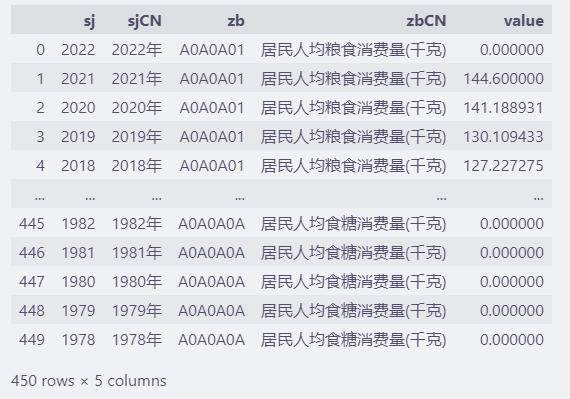
使用的是其中 A0A0A.csv文件(全国居民主要食品消费量)
fp = "d:/share/A0A0A.csv"
df = pd.read_csv(fp)
df
4.2. 数据清理
选取和上一篇堆叠柱状图一样,还是5类:
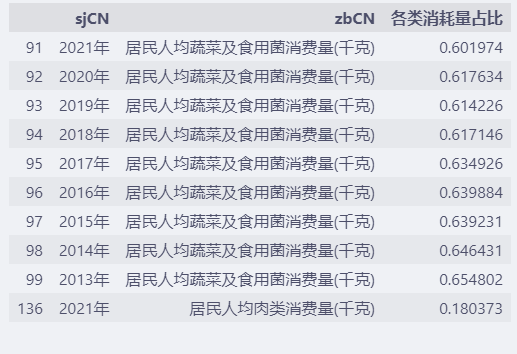
- 居民人均蔬菜及食用菌消费量(千克)
- 居民人均肉类消费量(千克)
- 居民人均禽类消费量(千克)
- 居民人均水产品消费量(千克)
- 居民人均蛋类消费量(千克)
和堆叠柱状图不同的是,绘制百分比柱状图用的是百分比数值,
所有要把原始数据中每年的绝对数值转换为百分比数值。
data = df[(df["sj"] >= 2013) &
(df["sj"] <= 2021) &
(df["zb"].isin(["A0A0A03",
"A0A0A04",
"A0A0A05",
"A0A0A06",
"A0A0A07"]))].copy()
data["年消耗总量"] = data.groupby("sj").value.transform("sum")
data["各类消耗量占比"] = data["value"] / data["年消耗总量"]
data.loc[:, ["sjCN", "zbCN", "各类消耗量占比"]].head(10)
4.3. 分析结果可视化
import matplotlib.ticker as mticker
data = data.sort_values("sj")
data["各类消耗量占比"] = data["各类消耗量占比"]*100
with plt.style.context("seaborn-v0_8"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
years = data["sjCN"].drop_duplicates(keep="first").tolist()
bar_data = {
"蔬菜及菌类(%)": data[data["zb"] == "A0A0A03"]["各类消耗量占比"].tolist(),
"肉类(%)": data[data["zb"] == "A0A0A04"]["各类消耗量占比"].tolist(),
"禽类(%)": data[data["zb"] == "A0A0A05"]["各类消耗量占比"].tolist(),
"水产品(%)": data[data["zb"] == "A0A0A06"]["各类消耗量占比"].tolist(),
"蛋类(%)": data[data["zb"] == "A0A0A07"]["各类消耗量占比"].tolist(),
}
bottom = np.zeros(len(years))
for key, vals in bar_data.items():
ax.bar(years, vals, label=key, bottom=bottom)
bottom += vals
# 设置Y轴刻度的显示格式
ax.set_ylim(0, 110)
yticks = ax.get_yticks().tolist()
ax.yaxis.set_major_locator(mticker.FixedLocator(yticks))
ax.set_yticklabels(["{}%".format(x) for x in yticks])
ax.set_title("全国居民主要粮食消耗情况")
ax.legend(loc="upper left", ncol=5)

百分比柱状图每年的数据高度都一样,与堆叠柱状图相比,更容易比较每个种类粮食的消耗情况。
不过,这种图看不出粮食总量的变化情况了。










![原来你是这样的JAVA–[07]聊聊Integer和BigDecimal](https://img2024.cnblogs.com/blog/37001/202402/37001-20240224171021931-593439949.png)