1 版本参数
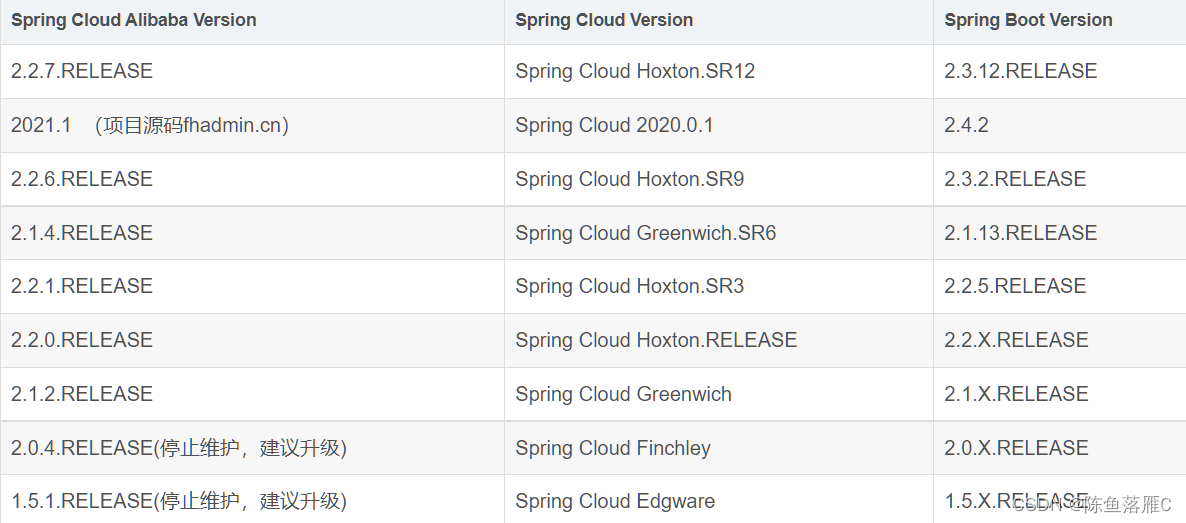
查看hadoop和hive的版本号
ls -l /opt
# 总用量 3
# drwxr-xr-x 11 root root 227 1月 26 19:23 hadoop-3.3.6
# drwxr-xr-x 10 root root 205 2月 12 18:53 hive-3.1.3
# drwxrwxrwx. 4 root root 32 2月 11 22:19 tmp
查看java版本号
java -version
# java version "1.8.0_391"
# Java(TM) SE Runtime Environment (build 1.8.0_391-b13)
# Java HotSpot(TM) 64-Bit Server VM (build 25.391-b13, mixed mode)
查看mysql版本号
mysql --version
# mysql Ver 8.0.35 for Linux on x86_64 (MySQL Community Server - GPL)
2 启动环境
启动hadoop集群
start-all.sh
# WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
# Starting namenodes on [ml]
# 上一次登录:三 3月 6 23:34:59 CST 2024tty1 上
# Starting datanodes
# 上一次登录:三 3月 6 23:37:56 CST 2024pts/0 上
# Starting secondary namenodes [ml]
# 上一次登录:三 3月 6 23:38:01 CST 2024pts/0 上
# Starting resourcemanager
# 上一次登录:三 3月 6 23:38:30 CST 2024pts/0 上
# Starting nodemanagers
# 上一次登录:三 3月 6 23:39:01 CST 2024pts/0 上
查看hadoop集群状态
jps|sort
# 2337 NameNode
# 2548 DataNode
# 3161 ResourceManager
# 3379 NodeManager
# 5654 Jps
启动hiveserver2服务
nohup hiveserver2 &
# [1] 7486
# (pyspark) (base) [root@~ ~]# nohup: 忽略输入并把输出追加到"nohup.out"
#
检测hiveserver2状态
jps|grep 7486
# 7486 RunJar
检测thrift端口号状态
netstat -anp|grep 10000
# tcp6 0 0 :::10000 :::* LISTEN 7486/java
3 安装环境
安装python第三方库
conda install sasl
conda install thrift
conda install thrift-sasl
conda install pyhive
conda install sqlalchemy
conda install pandas
使用everything检索sasl2文件夹并打开该文件夹
在open git bash here窗口查看sasl2里面的文件
ls
# saslANONYMOUS.dll* saslLOGIN.dll* saslPLAIN.dll* saslSQLITE.dll*
# saslCRAMMD5.dll* saslNTLM.dll* saslSASLDB.dll* saslSRP.dll*
# saslDIGESTMD5.dll* saslOTP.dll* saslSCRAM.dll*
创建C:/CMU/bin/sasl2文件夹
拷贝当前文件夹的dll文件到C:/CMU/bin/sasl2文件夹中
mkdir -p C:/CMU/bin/sasl2
cp ./* C:/CMU/bin/sasl2/
4 读取数据
编写python脚本连接hive数仓
import pandas as pd
from pyhive import hive
from sqlalchemy import create_engine
engine = create_engine('hive://root:ml123456@ml:10000/default?auth=LDAP')
df = pd.read_sql_query('show databases',con=engine)
df.head()
能看到数据库名记录就证明连接成功