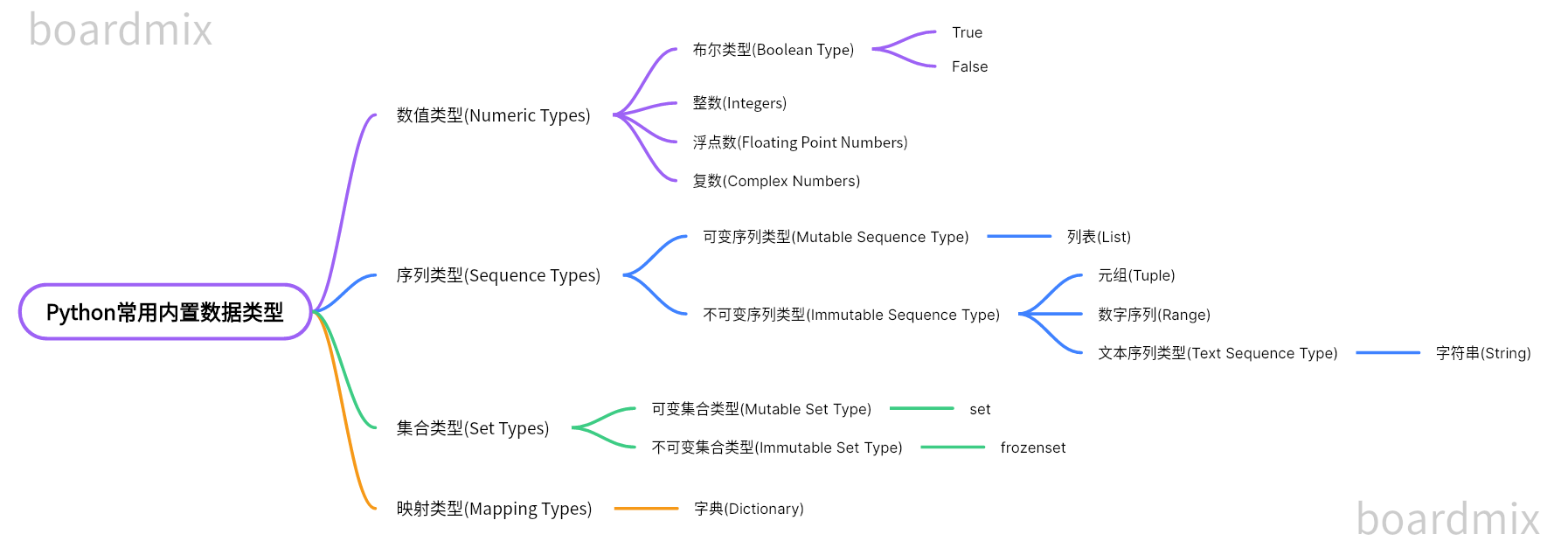
这一篇主要讲 Spark 中的 Shuffle 机制.
将 job 划分成多个 task 后, stage 内的一个 task 可以在一个节点上完成计算, task 内以来的数据可以直接存储在当前结点上 (内存或者磁盘中). 但是 stage 间的 task 可能在不同节点上计算, 那么当前 task 怎么拿到上一 stage 的数据呢? 注意到在生成物理执行计划时, 是按照宽依赖对 DAG 进行划分的, 也就是在宽依赖型的 transformation 的输入和输出之间切一刀. 所以这个问题等价于宽依赖的输入输出是怎么连接起来的. Spark 中的 Shuffle 机制就是解决这个问题的: 如何重新组织数据, 使其能够在上游和下游 task 之间进行传递和计算. Shuffle 考虑的不仅是数据传输, 还有支持不同类型的计算 (因为不同的宽依赖 transformation 有不同的计算逻辑), 并且尽可能保证性能.
Shuffle 机制分为 Shuffle Write 和 Shuffle Read 两个阶段, 前者主要解决上游 Stage 输出数据的分区问题, 后者主要解决下游 stage 如何从上游 stage 获取数据, 重新组织, 并为后续操作提供数据的问题.
1. Shuffle Write
注意到, 宽依赖型的 transformation 是会跨越两个 stage 的, 可以将上下游 stage 的 task 分别视为 map task 和 reduce task, 即这个 transformation 由两个阶段 (map, reduce) 完成, Shuffle Write 就是 map 阶段.
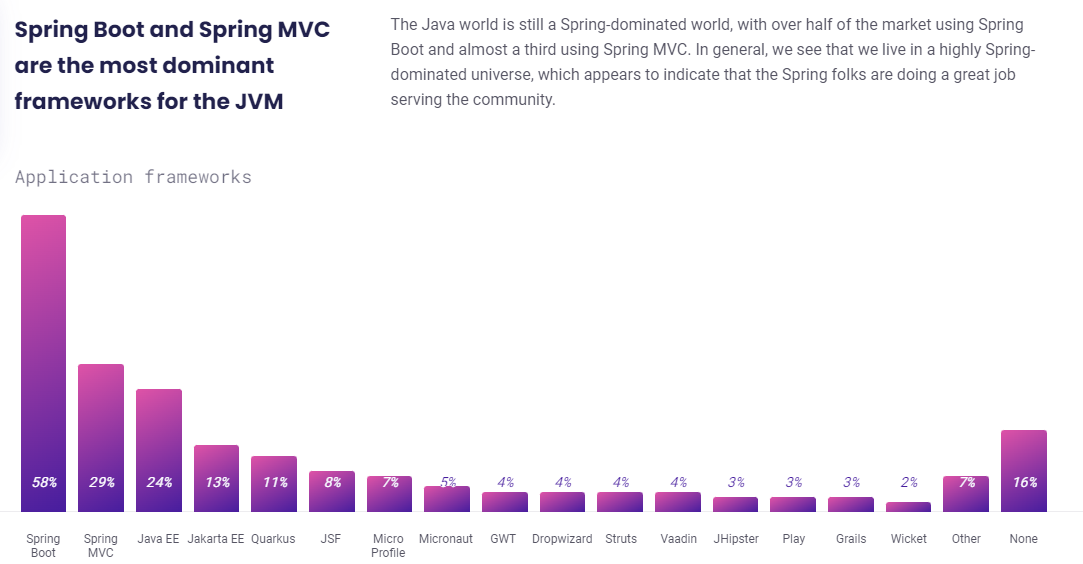
可以把 Shuffle 看作是宽依赖操作的一种范式, 因此 Shuffle 机制的设计需要能够包含各种宽依赖操作的流程. 一个通用的 Shuffle Write 框架如 shuffle-write 所示.

注意到 Shuffle Write 只是宽依赖操作的 map task, 且该操作是当前 stage 的最后一个操作. 每个 map task 的处理流程:
- 每个 map task 处理一个分区的数据, 对每条记录进行处理并计算出一个 partitionID (生成的分区数与下一个 stage 的 task 数相等);
- 可选项: 将记录存放到类似 Hashmap 的数据结构进行聚合;
- 可选项: 聚合完成后, 将 Hashmap 中的数据放入类似数组中的数据结构中进行排序 (可以按照 partitionID 或者 partitionID + Key 进行排序);
- 最后根据 partitionID 将数据写入不同的数据分区中, 存放到本地磁盘;
Spark 在聚合和排序阶段有更深入的考量, 并为提高性能设计了特殊的数据结构, 这里就先不展开了.
2. Shuffle Read
Shuffle Read 阶段的 task 可以看作是 reduce task, 可以简略地看作是 Shuffle Write 阶段的宽依赖操作的后半部分. 一个通用的 Shuffle Read 框架如 shuffle-read 所示.

在 Shuffle Read 阶段, 每个 map task 输出的分区数与 Shuffle Read 阶段的 reduce task 数一样多, 即每个 reduce task 会从每个 map task 那儿获取对应的分区文件. reduce task 的处理流程:
- reduce task 从各个 map task 的分区文件中获取数据;
- 可选项: 使用类似 Hashmap 的数据结构对数据进行聚合, 边获取数据边聚合;
- 可选项: 聚合完成后, 将 Hashmap 中的数据放入类似数组的数据结构中按照 Key 进行排序;
- 将结果输出或者传递给下一操作.
Spark 中一些典型操作的计算需求如 shuffle-ops 所示:

关于 MapReduce 和 Spark 的 Shuffle 机制的一个对比:
- MR 的 Shuffle 流程固定, 每个阶段读取什么数据, 进行什么操作, 输出什么数据都是确定性的. Spark 的 Shuffle 过程中有可选操作;
- MR 对记录按照 Key 进行排序, 但实际上并不是所有的操作都需要排序. Spark 中排序是可选的, 且排序方式比较灵活;
- MR 不能在线聚合 (获取数据的同时进行聚合). Spark 中在获取数据插入到 Hashmap 时可以进行在线聚合;
- MR 产生的临时文件过多, Spark 中做了相应的优化: 可以将多个分区文件合并为一个文件, 按照 partitionID 的顺序存储.













![原来你是这样的JAVA–[07]聊聊Integer和BigDecimal](https://img2024.cnblogs.com/blog/37001/202402/37001-20240224171021931-593439949.png)