1 多分类
在pytorch中,例如我们最常用的计算一条数据的交叉熵(下面的公式少打了
∗
1
N
*\frac{1}{N}
∗N1):
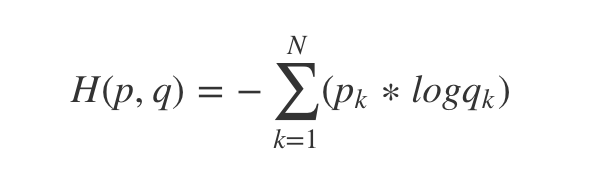
并非就是 torch.nn.CrossEntropyLoss,
torch.nn.CrossEntropyLoss包括了三个步骤的处理:
-
把输出矢量 [z1, z2, …, zK] 进行softmax化,使得概率和为1;
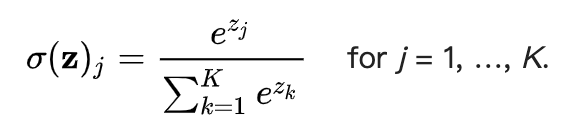
-
softmax化后的输出进行 log 计算。
-
根据交叉熵的计算公式,结合该条数据真实标签,计算损失熵,注意这里会自动加上一个负号,以得到正的结果,并进行算术平均!!!。
所以说,在pytorch框架下,我们在设计模型时,模型的最后一层不需要加任何激活函数!!!!!!!!!(用nn.Linear直接输出即可)
如果你在最后一层加了激活函数,并且也计算出 log(预测值) ,那么你可以选择用 torch.nn.NLLLoss() 来实现上述 步骤3:
t
o
r
c
h
.
n
n
.
N
L
L
L
o
s
s
(
p
r
e
d
_
v
e
c
t
o
r
,
t
a
r
g
e
t
)
=
1
N
∑
k
=
1
N
t
a
r
g
e
t
[
k
]
∗
p
r
e
d
_
v
e
c
t
o
r
[
k
]
torch.nn.NLLLoss(pred\_vector,target)=\frac{1}{N}\sum_{k=1}^{N} target[k]*pred\_vector[k]
torch.nn.NLLLoss(pred_vector,target)=N1∑k=1Ntarget[k]∗pred_vector[k]
target 为one-hot的形式,仅在真实标签时为1。
参考代码:
import torch
input=torch.randn(3,3)
soft_input = torch.nn.Softmax(dim=0)
>>soft_input(input)
Out[20]:
tensor([[0.7284, 0.7364, 0.3343],
[0.1565, 0.0365, 0.0408],
[0.1150, 0.2270, 0.6250]])
#对softmax结果取log
>> torch.log(soft_input(input))
Out[21]:
tensor([[-0.3168, -0.3059, -1.0958],
[-1.8546, -3.3093, -3.1995],
[-2.1625, -1.4827, -0.4701]])
# 假设标签是[0,1,2],第一行取第0个元素,第二行取第1个,第三行取第2个,去掉负号,
# 即[0.3168,3.3093,0.4701],求平均值,就可以得到损失值,注意这里取了3个数的平均!
>> (0.3168+3.3093+0.4701)/3
Out[22]: 1.3654000000000002
#验证一下
loss=torch.nn.NLLLoss()
target=torch.tensor([0,1,2])
>>loss(input,target)
Out[26]: tensor(0.1365)
2 二分类
2.1 torch.nn.BCELoss()
二分类的损失函数一般用 torch.nn.BCELoss()。
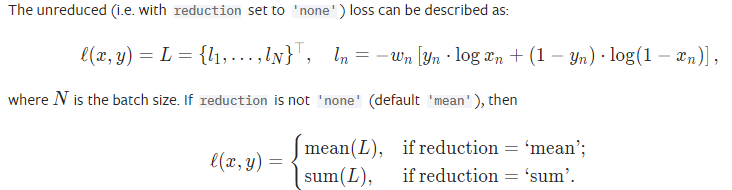
用法:
>>> m = nn.Sigmoid()
>>> loss = nn.BCELoss()
>>> input = torch.randn(3, requires_grad=True)
>>> target = torch.empty(3).random_(2)
>>> output = loss(m(input), target)
>>> output.backward()
当出现 log 0 的情况时,那一项的损失值当作 -100 来算~
强烈建议若用这个损失函数得在模型最后一层加上 sigmoid 层。
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction=‘mean’)
weight (Tensor, optional) – a manual rescaling weight given to the loss of each batch element. If given, has to be a Tensor of size nbatch.
size_average (bool, optional) – Deprecated (see reduction). By default, the losses are averaged over each loss element in the batch. Note that for some losses, there are multiple elements per sample. If the field size_average is set to False, the losses are instead summed for each minibatch. Ignored when reduce is False. Default: True
reduce (bool, optional) – Deprecated (see reduction). By default, the losses are averaged or summed over observations for each minibatch depending on size_average. When reduce is False, returns a loss per batch element instead and ignores size_average. Default: True
reduction (string, optional) – Specifies the reduction to apply to the output: ‘none’ | ‘mean’ | ‘sum’. ‘none’: no reduction will be applied, ‘mean’: the sum of the output will be divided by the number of elements in the output, ‘sum’: the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction. Default: ‘mean’
输入输出规定:
Input: (N, ∗) where *∗ means, any number of additional dimensions
Target: (N, ∗), same shape as the input
Output: scalar. If reduction is ‘none’, then (N,∗) , same shape as input.
2.2 torch.nn.BCEWithLogitsLoss()
为了避免2.1方法中 log 0 无法计算的局限性,我们可以使用torch.nn.BCEWithLogitsLoss(),他在计算的时候会自动给
y
p
r
e
d
i
c
t
i
o
n
y^{prediction}
yprediction 加一个 Sigmoid 函数。
torch.nn.BCEWithLogitsLoss(weight=None, size_average=None, reduce=None, reduction=‘mean’, pos_weight=None)

用法同 2.1
参考:
https://blog.csdn.net/Jeremy_lf/article/details/102725285